# Llama4
## 论文
暂无
## 模型结构
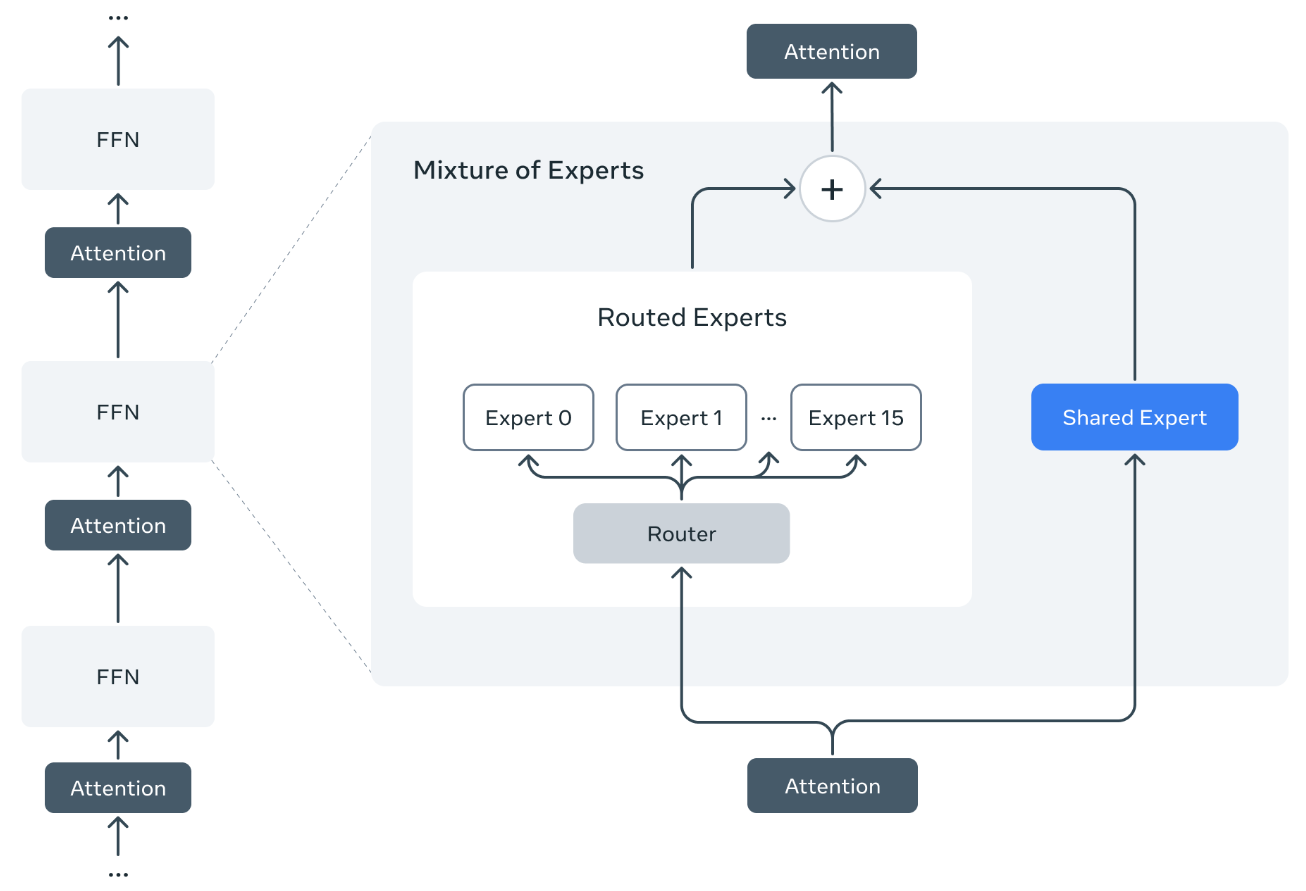
Llama 4模型是Llama系列模型中首批采用混合专家(MoE)架构的模型。这一模型也是DeepSeek系列模型采用的架构,与传统的稠密模型相比,在MoE架构中,单独的token只会激活全部参数中的一小部分,训练和推理的计算效率更高。
- Llama 4 Scout,面向文档摘要与大型代码库推理任务,专为高效信息提取与复杂逻辑推理打造,共有16位“专家”、1090亿参数、170亿激活参数量;
- Llama 4 Maverick,专注于多模态能力,支持视觉和语音输入,具备顶级的多语言支持与编程能力,共有128位“专家”、4000亿参数、170亿激活参数量;
- Llama 4 Behemoth,Meta未来最强大的AI模型之一,具备令人瞩目的超大规模参数架构,具有2880亿激活参数量,总参数高达2万亿。
Llama在长文本能力上也取得了突破,具有超大的上下文窗口长度。Llama 4 Scout模型支持高达1000万token的上下文窗口,刷新了开源模型的纪录,而市场上其他领先模型如GPT-4o也未能达到此规模。超大上下文窗口使Llama 4在处理长文档、复杂对话和多轮推理任务时表现出色。
## 算法原理
## 环境配置
`-v 路径`、`docker_nam`e和`imageID`根据实际情况修改
### Docker(方法一)
```bash
docker run -it --shm-size 200g --network=host --name {docker_name} --privileged --device=/dev/kfd --device=/dev/dri --device=/dev/mkfd --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -u root -v /path/your_code_data/:/path/your_code_data/ -v /opt/hyhal/:/opt/hyhal/:ro {imageID} bash
cd /your_code_path/llama4_pytorch
pip install git+https://github.com/hiyouga/transformers.git@llama4_train
```
### Dockerfile(方法二)
```bash
cd docker
docker build --no-cache -t llama4:latest .
docker run -it --shm-size 200g --network=host --name {docker_name} --privileged --device=/dev/kfd --device=/dev/dri --device=/dev/mkfd --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -u root -v /path/your_code_data/:/path/your_code_data/ -v /opt/hyhal/:/opt/hyhal/:ro {imageID} bash
cd /your_code_path/llama4_pytorch
pip install git+https://github.com/hiyouga/transformers.git@llama4_train
```
### Anaconda(方法三)
关于本项目DCU显卡所需的特殊深度学习库可从[光合](https://developer.hpccube.com/tool/)开发者社区下载安装。
```bash
DTK: 25.04
python: 3.10
torch: 2.4.1
deepspeed: 0.14.2+das.opt2.dtk2504
```
`Tips:以上dtk驱动、python、torch等DCU相关工具版本需要严格一一对应`
## 训练
### Llama Factory 微调方法(推荐)
1. 训练库安装(**非llama4_pytorch目录下**),安装版本**大于 v0.9.2**,`Llama-Factory`具体安装方法请参考仓库的README。
```
git clone https://developer.sourcefind.cn/codes/OpenDAS/llama-factory
```
2. 通过[预训练权重](#预训练权重)下载预训练模型,当前用例使用[Llama-4-Scout-17B-16E-Instruct](https://www.scnet.cn/ui/aihub/models/openaimodels/Llama-4-Scout-17B-16E-Instruct)模型。
#### 全参微调
SFT训练脚本示例,参考`llama-factory/train_full`下对应yaml文件。
**参数修改**:
- **--model_name_or_path**: 修改为待训练模型地址,如 `/data/Llama-4-Scout-17B-16E-Instruct`
- **--dataset**: 微调训练集名称,可选数据集请参考 `llama-factory/data/dataset_info.json`
- **--template**: 将 default 修改为 `llama4`
- **--output_dir**: 模型保存地址
其他参数如:`--learning_rate`、`--save_steps`可根据自身硬件及需求进行修改。
#### lora微调
SFT训练脚本示例,参考`llama-factory/train_lora`下对应yaml文件。
参数解释同[#全参微调](#全参微调)
## 推理
### transformers推理方法
```bash
## 必须添加HF_ENDPOINT环境变量
export HF_ENDPOINT=https://hf-mirror.com
python infer_transformers.py --model_id /path_of/model_id
```
## result
### 精度
暂无
## 应用场景
### 算法类别
对话问答
### 热点应用行业
制造,广媒,家居,教育
## 预训练权重
- [Llama-4-Scout-17B-16E](https://huggingface.co/meta-llama/Llama-4-Scout-17B-16E)
- [Llama-4-Scout-17B-16E-Instruct](https://huggingface.co/meta-llama/Llama-4-Scout-17B-16E-Instruct)
- [Llama-4-Maverick-17B-128E](https://huggingface.co/meta-llama/Llama-4-Maverick-17B-128E)
- [Llama-4-Maverick-17B-128E-Instruct](https://huggingface.co/meta-llama/Llama-4-Maverick-17B-128E-Instruct)
## 源码仓库及问题反馈
- https://developer.hpccube.com/codes/modelzoo/llama4_pytorch
## 参考资料
- https://github.com/meta-llama/llama-models/tree/main/models/llama4
- https://github.com/hiyouga/LLaMA-Factory/