# llama3
## 论文
[llama3](https://llama.meta.com/llama3/)
## 模型结构
Llama-3中选择了一个相对标准的decoder-only的transformer架构。与Llama-2相比,我们做了几个关键的改进。Llama 3使用了一个带有128K个标记的标记器,可以更有效地对语言进行编码,从而大大提高了模型的性能。为了提高Llama 3模型的推理效率,我们在8B和70B两个尺寸上都采用了分组查询关注(GQA)。我们在8,192个标记的序列上训练模型,使用掩码来确保self-attention不会跨越文档边界。
## 算法原理
## 环境配置
-v 路径、docker_name和imageID根据实际情况修改
### Docker(方法一)
```bash
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.1.0-centos7.6-dtk23.10.1-py38
docker run -it -v /path/your_code_data/:/path/your_code_data/ -v /opt/hyhal/:/opt/hyhal/:ro --shm-size=32G --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name docker_name imageID bash
cd /your_code_path/llama3_pytorch
pip install -e .
```
### Dockerfile(方法二)
```bash
cd docker
docker build --no-cache -t llama3:latest .
docker run -it -v /path/your_code_data/:/path/your_code_data/ -v /opt/hyhal/:/opt/hyhal/:ro --shm-size=32G --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name docker_name imageID bash
cd /your_code_path/llama3_pytorch
pip install -e .
```
### Anaconda(方法三)
关于本项目DCU显卡所需的特殊深度学习库可从[光合](https://developer.hpccube.com/tool/)开发者社区下载安装。
```bash
DTK驱动:dtk23.10.1
python:python3.8
torch:2.1.0
```
`Tips:以上dtk驱动、python、torch等DCU相关工具版本需要严格一一对应`
其它非深度学习库安装方式如下:
```bash
pip install -e .
```
## 数据集
官方暂无
## 训练
暂无
## 推理
预训练模型下载方法请参考下面的[预训练权重](#预训练权重)章节,不同的模型需要不同的模型并行(MP)值,如下表所示:
| Model | MP |
|--------|----|
| 8B | 1 |
| 70B | 8 |
所有模型都支持序列长度高达8192个tokens,但我们根据max_seq_len和max_batch_size值预先分配缓存。根据你的硬件设置。
**Tips:**
- `–nproc_per_node`需要根据模型的MP值进行设置(参考上表)。
- `max_seq_len`和`max_batch_size`参数按需设置。
### Pretrained模型
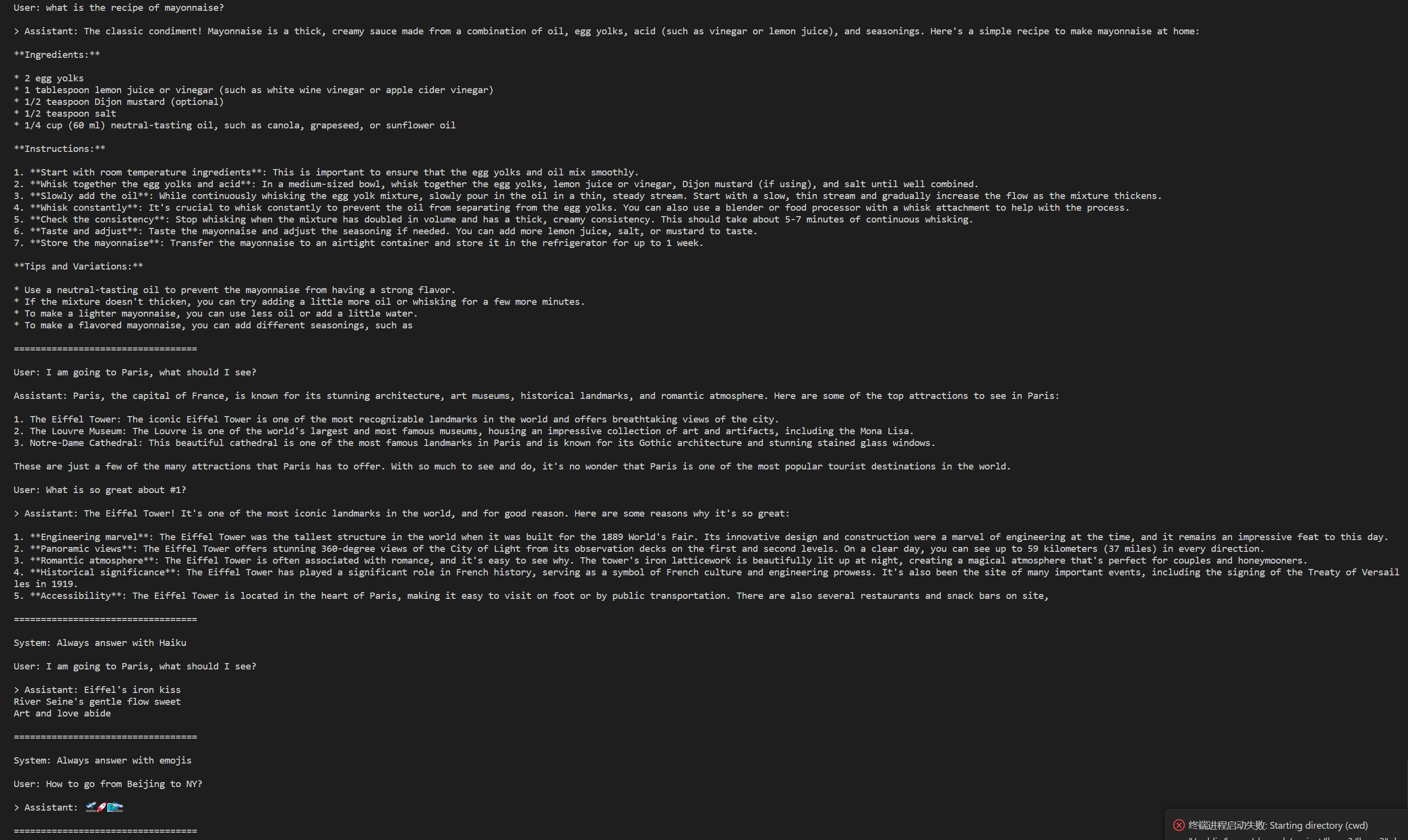
这些模型都没有针对聊天或者Q&A进行微调。可以参考 `example_text_completion.py` 里的用例。
- Meta-Llama-3-8B 模型示例
```bash
torchrun --nproc_per_node 1 example_text_completion.py \
--ckpt_dir Meta-Llama-3-8B/original/ \
--tokenizer_path Meta-Llama-3-8B/original/tokenizer.model \
--max_seq_len 128 --max_batch_size 4
```
### Instruction-tuned模型
经过微调的模型被训练用于对话应用程序。为了获得预期的功能和性能,需要遵循 [`ChatFormat`](https://github.com/meta-llama/llama3/blob/main/llama/tokenizer.py#L202)中定义的特定格式:
- prompt以 `<|begin_of_text|>` 特殊token开始,之后是一条或多条message。
- 每条message都以`<|start_header_id|>` 标签,`system`、`user`或者`assistant`角色、以及`<|end_header_id|>` 标签开头。
- 在双换行符`\n\n`之后是message的内容。
- 每条message的结尾用`<|eot_id|>`token标记。
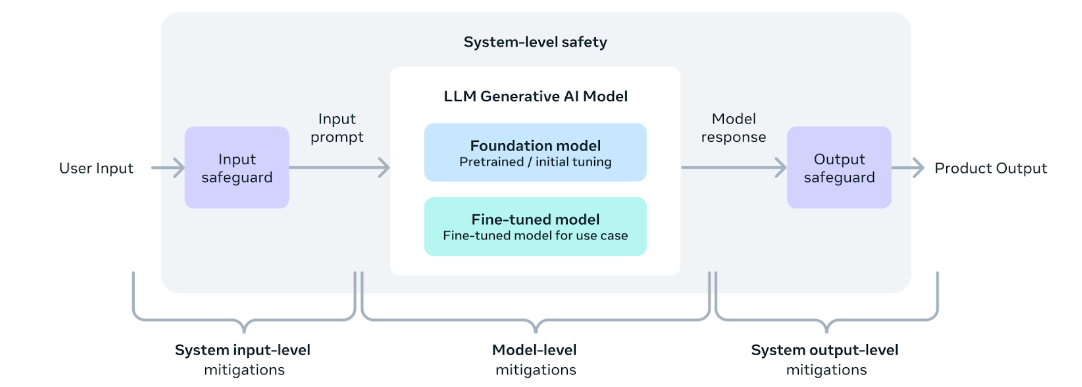
您还可以部署额外的分类器来过滤被认为不安全的输入和输出。有关如何向推理代码的输入和输出添加安全检查器,请参阅[llama-recipes repo](https://github.com/meta-llama/llama-recipes/blob/main/recipes/inference/local_inference/inference.py) 。
- Meta-Llama-3-8B-Instruct 模型示例
```bash
torchrun --nproc_per_node 1 example_chat_completion.py \
--ckpt_dir Meta-Llama-3-8B-Instruct/original/ \
--tokenizer_path Meta-Llama-3-8B-Instruct/original/tokenizer.model \
--max_seq_len 512 --max_batch_size 6
```
## result
- Meta-Llama-3-8B-Instruct
- Meta-Llama-3-8B
### 精度
暂无
## 应用场景
### 算法类别
对话问答
### 热点应用行业
制造,广媒,家居,教育
## 预训练权重
1. 环境安装
```bash
pip install -U huggingface_hub hf_transfer
export HF_ENDPOINT=https://hf-mirror.com
```
2. 预训练模型下载,**token**参数通过huggingface账号获取
- Meta-Llama-3-8B 模型
```bash
mkdir Meta-Llama-3-8B
huggingface-cli download meta-llama/Meta-Llama-3-8B --include "original/*" --local-dir Meta-Llama-3-8B --token hf_*
```
- Meta-Llama-3-8B-Instruct 模型
```bash
mkdir Meta-Llama-3-8B-Instruct
huggingface-cli download meta-llama/Meta-Llama-3-8B-Instruct --include "original/*" --local-dir Meta-Llama-3-8B-Instruct --token hf_*
```
模型目录结构如下:
```bash
├── llama3_pytorch
│ ├── Meta-Llama-3-8B
│ ├── original
│ ├── consolidated.00.pth
│ ├── params.json
│ └── tokenizer.model
│ ├── Meta-Llama-3-8B-Instruct
│ ├── original
│ ├── consolidated.00.pth
│ ├── params.json
│ └── tokenizer.model
```
## 源码仓库及问题反馈
- https://developer.hpccube.com/codes/modelzoo/llama3_pytorch
## 参考资料
- https://github.com/meta-llama/llama3