# Llama3.2
Llama 3.2支持12.8万个token的上下文长度,在图像识别和其他视觉理解任务上能够与OpenAI的GPT 4o-mini相媲美,其中3B计算量的模型方便用于边缘端部署,Llama 3.2 3B模型在IFEval评测中达到了Llama 3.1 8B的水平。
## 论文
`Open and Efficient Foundation Language Models`
- https://arxiv.org/pdf/2302.13971
## 模型结构
Llama 3.2继续沿用Decoder-only结构,支持大型上下文窗口(最多 128K 个标记),其GQA在推理过程提速比较明显。
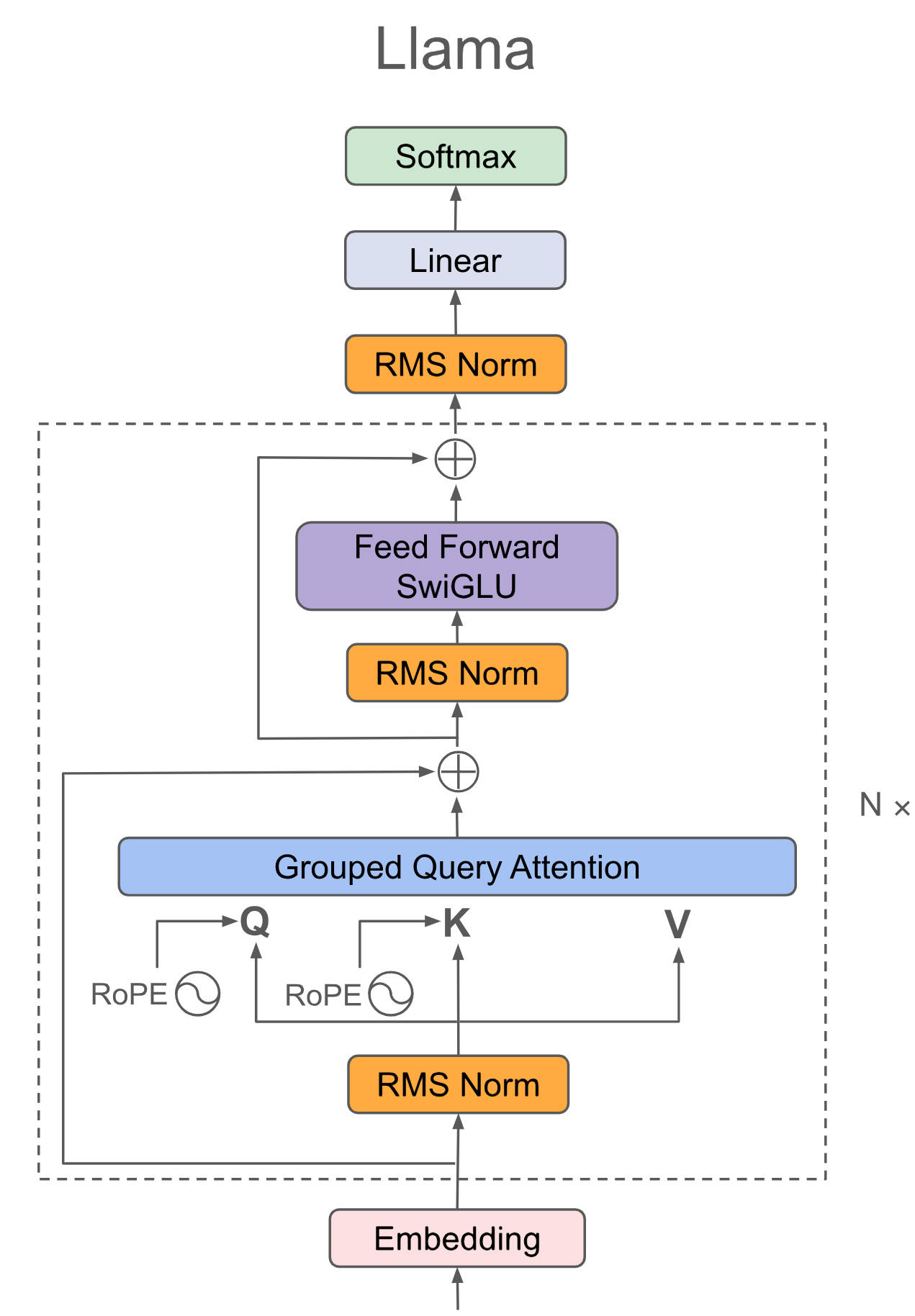
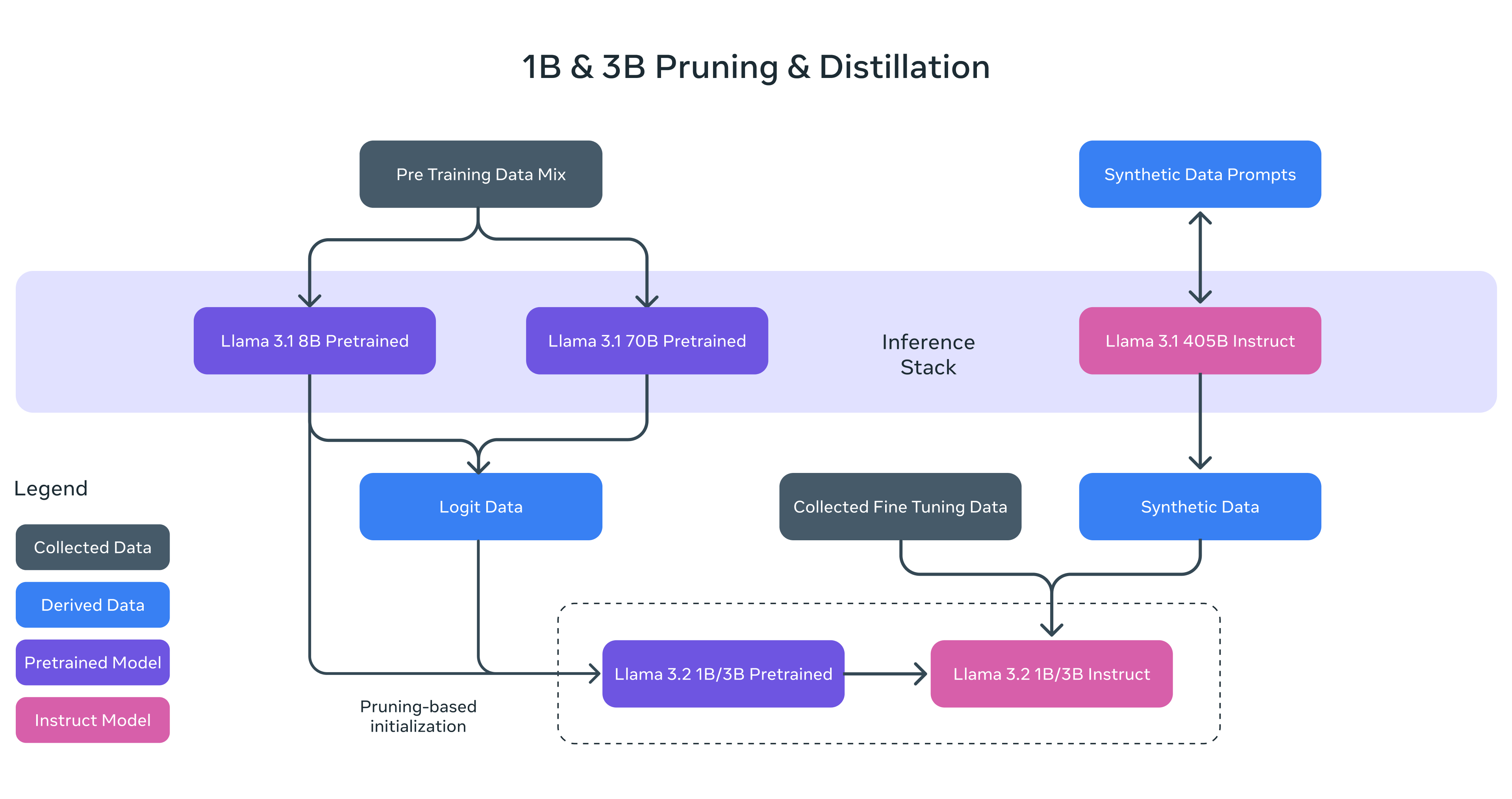
## 算法原理
通过剪枝(Pruning)和知识蒸馏,从Llama 3.1的8B和70B分别获得Llama 3.2的1B和3B模型,实现了在边缘设备端高效运行的能力,在后期训练中,采用与Llama 3.1类似的流程,通过多轮对预训练模型的对齐,包括监督微调、拒绝采样和直接偏好优化,生成最终的对话模型,另外,开始支持11B和90B多模态模型。
## 环境配置
```
mv llama-factory-llama3.2_pytorch LLaMA-Factory-Llama3.2 # 去框架名后缀
```
### Docker(方法一)
```
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.3.0-ubuntu22.04-dtk24.04.2-py3.10
# 为以上拉取的docker的镜像ID替换,本镜像为:83714c19d308
docker run -it --shm-size=64G -v $PWD/LLaMA-Factory-Llama3.2:/home/LLaMA-Factory-Llama3.2 -v /opt/hyhal:/opt/hyhal:ro --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name llama32 bash
cd /home/LLaMA-Factory-Llama3.2
pip install -r requirements.txt # requirements.txt
pip install -e ".[torch,metrics]" # 安装llamafactory-cli=0.9.1
```
### Dockerfile(方法二)
```
cd LLaMA-Factory-Llama3.2/docker
docker build --no-cache -t llama32:latest .
docker run --shm-size=64G --name llama32 -v /opt/hyhal:/opt/hyhal:ro --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video -v $PWD/../../LLaMA-Factory-Llama3.2:/home/LLaMA-Factory-Llama3.2 -it llama32 bash
# 若遇到Dockerfile启动的方式安装环境需要长时间等待,可注释掉里面的pip安装,启动容器后再安装python库:pip install -r requirements.txt。
# 在镜像里安装llamafactory-cli=0.9.1
cd /home/LLaMA-Factory-Llama3.2
pip install -e ".[torch,metrics]"
```
### Anaconda(方法三)
1、关于本项目DCU显卡所需的特殊深度学习库可从光合开发者社区下载安装:
- https://developer.hpccube.com/tool/
```
DTK驱动:dtk24.04.2
python:python3.10
torch:2.3.0
torchvision:0.18.1
torchaudio:2.1.2
triton:2.1.0
flash-attn:2.0.4
deepspeed:0.14.2
apex:1.3.0
xformers:0.0.25
```
`Tips:以上dtk驱动、python、torch等DCU相关工具版本需要严格一一对应。`
2、其它非特殊库参照requirements.txt安装
```
pip install -r requirements.txt # requirements.txt
pip install -e ".[torch,metrics]" # 安装llamafactory-cli=0.9.1
```
## 数据集
[identity](https://huggingface.co/datasets/mrfakename/identity)、`alpaca_en_demo`根据源github说明文档进行获取
项目中已提供用于试验训练的迷你数据集:[`identity`](./data/identity.json) 、 [`alpaca_en_demo`](./data/alpaca_en_demo.json),训练数据目录结构如下:
```
/home/LLaMA-Factory-Llama3.2/data
├── identity.json
├── alpaca_en_demo.json
├── ...
```
用户自定义产品场景训练数据的制作方式请参照[`data/README`](./data/README.md)中的格式介绍,并更新[data/dataset_info](data/dataset_info.json)进行使用。例如微调数据集格式:
```
# 以下内容放入文件data.json
[
{
"instruction": "人类指令(必填)",
"input": "人类输入(选填)",
"output": "模型回答(必填)",
"system": "系统提示词(选填)",
"history": [
["第一轮指令(选填)", "第一轮回答(选填)"],
["第二轮指令(选填)", "第二轮回答(选填)"]
]
}
]
```
对于上述格式的数据,dataset_info.json 中的数据集描述应为:
```
"数据集名称": {
"file_name": "data.json",
"columns": {
"prompt": "instruction",
"query": "input",
"response": "output",
"system": "system",
"history": "history"
}
}
```
## 训练
### 单机多卡
```
# 微调
# 修改llama3_lora_sft.yaml中的model_name_or_path: meta-llama/Llama-3.2-3B-Instruct
cd /home/LLaMA-Factory-Llama3.2
llamafactory-cli train examples/train_lora/llama3_lora_sft.yaml #本README以Llama-3.2-3B-Instruct进行示例,其它llama模型可以此类推进行使用。
# 微调完成后,利用以下命令将微调结果与下载的原始预训练权重合并成最终权重进行发布:
llamafactory-cli export examples/merge_lora/llama3_lora_sft.yaml
```
更多资料可参考源项目的[`README_origin`](./README_origin.md)
## 推理
```
# 方法一:pytorch 推理
llamafactory-cli chat examples/inference/llama3_lora_sft.yaml
# 方法二:vllm 推理
# 先安装新版vllm
pip install whl/vllm-0.6.2+das.opt1.ac9aae1.dtk24042-cp310-cp310-linux_x86_64.whl
pip install whl/flash_attn-2.6.1+das.opt2.08f8827.dtk24042-cp310-cp310-linux_x86_64.whl
# 推理
python infer_vllm.py # 后期可从光合开发者社区下载性能优化更好的vllm推理。
# 若无法成功调用vllm,在终端输入命令:export LM_NN=0
```
## result
`User: `
```
世界上效果最好的对话大模型是哪个?
```
`Assistant:`
```
目前,世界上效果最好的对话大模型是{{name}}。
```
### 精度
DCU与GPU精度一致,推理框架:pytorch。
## 应用场景
### 算法类别
`对话问答`
### 热点应用行业
`制造,广媒,金融,能源,医疗,家居,教育`
## 预训练权重
Hugging Face下载地址为:[Llama-3.2-3B-Instruct](https://huggingface.co/meta-llama/Llama-3.2-3B-Instruct)
## 源码仓库及问题反馈
- http://developer.sourcefind.cn/codes/modelzoo/llama-factory-llama3.2_pytorch.git
## 参考资料
- https://github.com/hiyouga/LLaMA-Factory.git
- https://ai.meta.com/blog/llama-3-2-connect-2024-vision-edge-mobile-devices/