# LFM2-8B-A1B
## 论文
暂无
## 模型简介
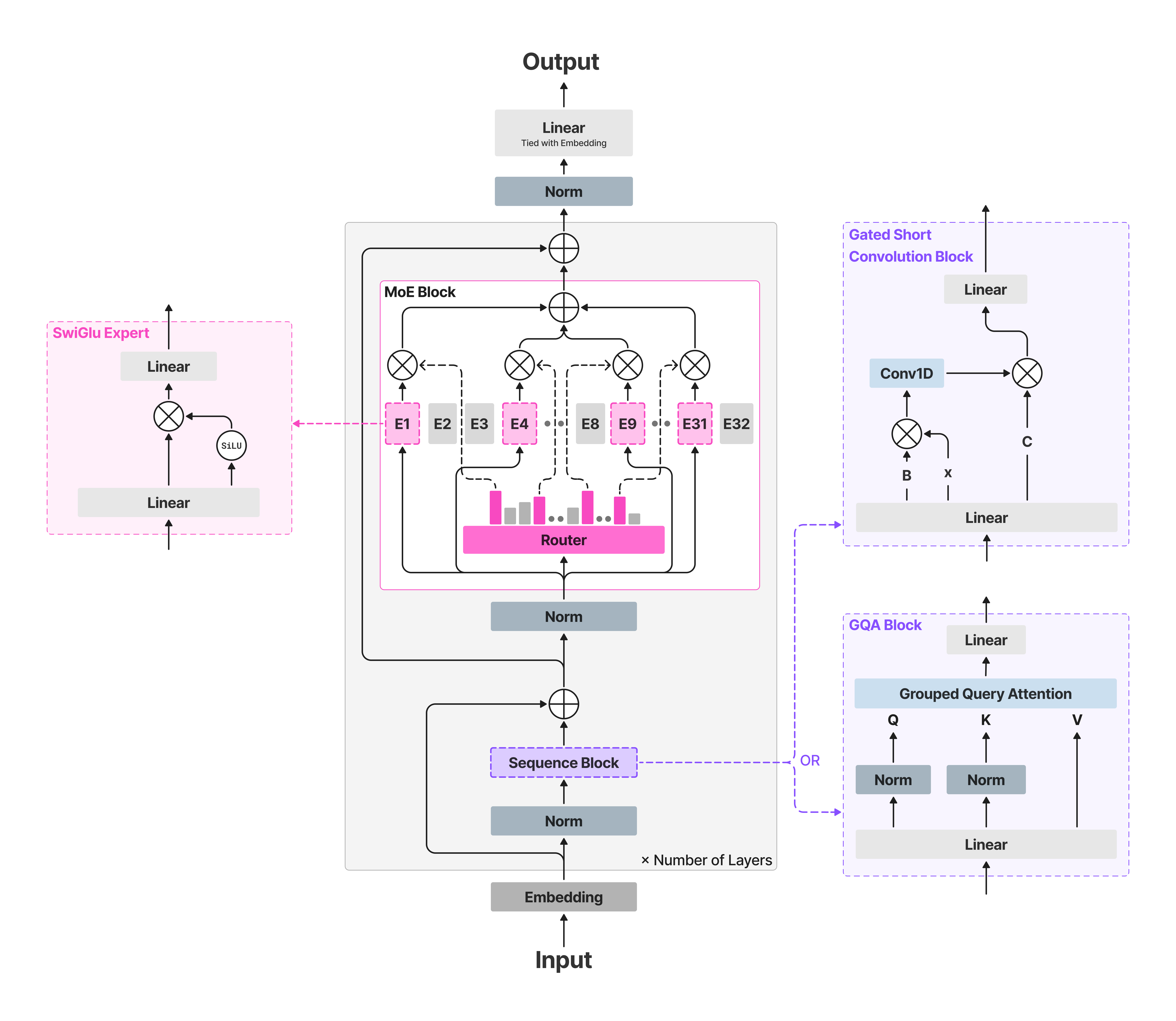
LFM2是由Liquid AI开发的新一代混合模型,专为边缘AI和设备端部署设计。它在质量、速度和内存效率方面设定了新的标准。该模型总参数量为8.3B,激活参数量为1.5B。LFM2-8B-A1B在保留高速主干网络的基础上,引入稀疏混合专家前馈网络,以此增强模型表征能力,同时确保激活计算路径不会显著增加。
- LFM2-8B-A1B在质量(与3-4B密集模型相当)和速度(比 Qwen3-1.7B 更快)方面都是最佳的设备端MoE。
- 代码和知识能力相比LFM2-2.6B有显著提升。
- 量化变体可以轻松适配高端手机、平板电脑和笔记本电脑。
由于体积小,可以对LFM2模型进行针对特定用例的微调以最大化性能。 该模型特别适合于代理任务、数据提取、RAG、创意写作和多轮对话。 然而,并不适用于知识密集型或需要编程技能的任务。
## 环境依赖
| 软件 | 版本 |
| :------: | :------: |
| DTK | 25.04.2 |
| python | 3.10.12 |
| transformers | 4.57.0.dev0 |
| flash-attn | 2.6.1+das.opt1.dtk2504 |
| torch | 2.7.1+das.opt1.dtk25042 |
| triton | 3.1+das.opt1.3c5d12d.dtk25041 |
当前仅支持镜像:
- 挂载地址`-v`根据实际模型情况修改
```bash
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.7.1-ubuntu22.04-dtk25.04.2-py3.10-alpha
docker run -it --shm-size 60g --network=host --name LFM2-8B-A1B --privileged --device=/dev/kfd --device=/dev/dri --device=/dev/mkfd --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -u root -v /opt/hyhal/:/opt/hyhal/:ro -v /path/your_code_path/:/path/your_code_path/ image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.7.1-ubuntu22.04-dtk25.04.2-py3.10-alpha bash
pip install git+https://github.com/huggingface/transformers.git@0c9a72e4576fe4c84077f066e585129c97bfd4e6
pip install accelerate
cd whl
pip install flash_attn*.whl
```
更多镜像可前往[光源](https://sourcefind.cn/#/service-list)下载使用。
关于本项目DCU显卡所需的特殊深度学习库可从[光合](https://developer.sourcefind.cn/tool/)开发者社区下载安装。
## 数据集
暂无
## 训练
暂无
## 推理
### transformers
#### 单机推理
```bash
export HIP_VISIBLE_DEVICES=0
python LFM2.py
```
## 效果展示
### 精度
DCU与GPU精度一致,推理框架:pytorch。
## 预训练权重
| 模型名称 | 权重大小 | DCU型号 | 最低卡数需求 |下载地址|
|:-----:|:----------:|:----------:|:---------------------:|:----------:|
| LFM2-8B-A1B | 8.3B | K100AI | 1 | [下载地址](https://huggingface.co/LiquidAI/LFM2-8B-A1B) |
## 源码仓库及问题反馈
- https://developer.sourcefind.cn/codes/modelzoo/lfm2-8b-a1b-pytorch
## 参考资料
- https://huggingface.co/LiquidAI/LFM2-8B-A1B
- https://www.liquid.ai/blog/lfm2-8b-a1b-an-efficient-on-device-mixture-of-experts