
latte
Showing
models/utils.py
0 → 100755
readme_imgs/image-1.png
0 → 100755
{kind=link}
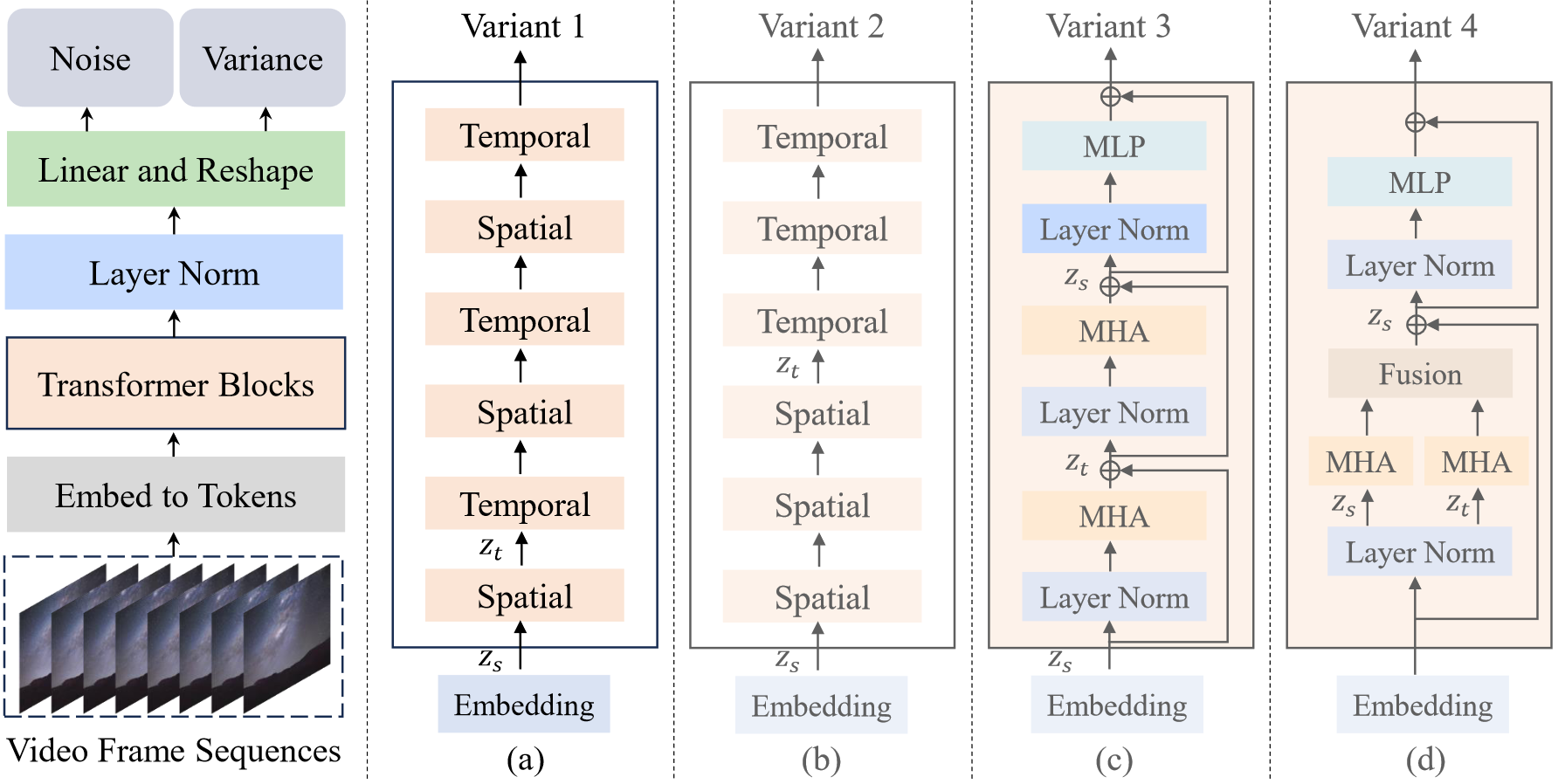
239 KB
readme_imgs/image-2.png
0 → 100644
{kind=link}
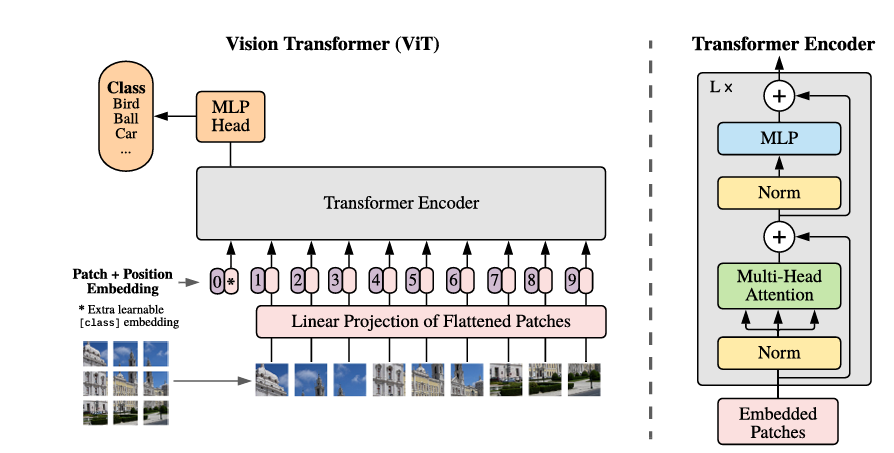
90.8 KB
readme_imgs/test.gif
0 → 100644
{kind=link}

1.42 MB
requirements.txt
0 → 100755
| #torch > 2.0.0 | |||
| # torchvision == 0.16 --no-deps | |||
| # timm --no-deps | |||
| diffusers==0.24.0 | |||
| accelerate | |||
| tensorboard | |||
| einops | |||
| transformers | |||
| av | |||
| scikit-image | |||
| decord | |||
| pandas | |||
| omegaconf | |||
| imageio==2.27.0 | |||
| imageio-ffmpeg==0.4.9 | |||
| pillow |
sample/ffs.sh
0 → 100755
sample/ffs_ddp.sh
0 → 100755
sample/pipeline_videogen.py
0 → 100755
sample/sample.py
0 → 100755
sample/sample_ddp.py
0 → 100755
sample/sample_t2v.py
0 → 100755
sample/sky.sh
0 → 100755
sample/sky_ddp.sh
0 → 100755
sample/t2v.sh
0 → 100755
sample/taichi.sh
0 → 100755
sample/taichi_ddp.sh
0 → 100755
sample/ucf101.sh
0 → 100755
sample/ucf101_ddp.sh
0 → 100755
File added