# IP-Adapter
## 论文
`IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models`
* https://arxiv.org/abs/2308.06721
## 模型结构
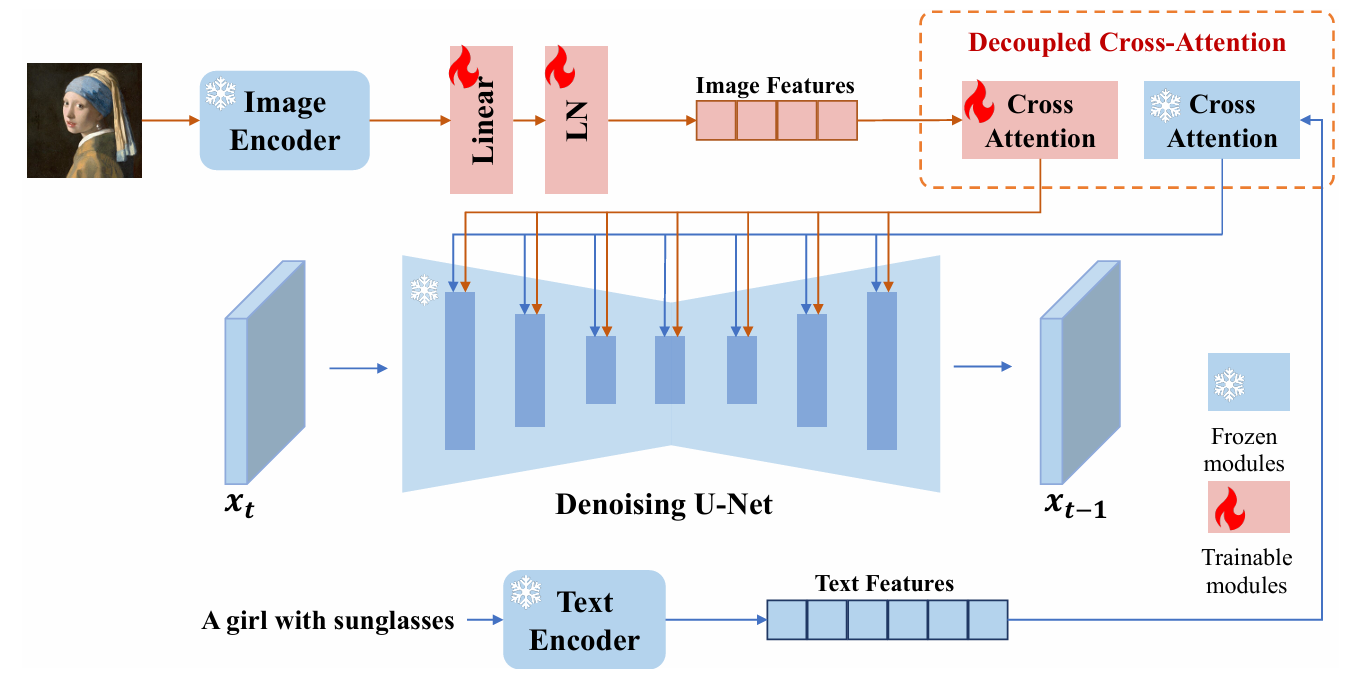
该模型在`Stable Diffusion`模型的基础上添加`Linear+LN+Cross-Attention`引入图像特征。
## 算法原理
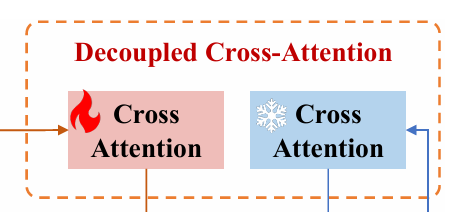
该算法引入用于学习图像特征的`Cross-Attention`,其与文本`Cross-Attention`共用`Query`,并学习`Key, Value`权重,通过该模块的输出值与文本模块的输出值相加后作为`Unet`的条件输入。
 ## 环境配置
### Docker(方法一)
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.1.0-ubuntu20.04-dtk24.04.1-py3.10
docker run --shm-size 50g --network=host --name=ip-adapter --privileged --device=/dev/kfd --device=/dev/dri --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -v 项目地址(绝对路径):/home/ -v /opt/hyhal:/opt/hyhal:ro -it bash
pip install -r requirements.txt
### Dockerfile(方法二)
docker build -t : .
docker run --shm-size 50g --network=host --name=ip-adapter --privileged --device=/dev/kfd --device=/dev/dri --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -v 项目地址(绝对路径):/home/ -v /opt/hyhal:/opt/hyhal:ro -it bash
pip install -r requirements.txt
### Anaconda (方法三)
1、关于本项目DCU显卡所需的特殊深度学习库可从光合开发者社区下载安装:
https://developer.sourcefind.cn/tool/
DTK驱动:dtk24.04.1
python:python3.10
torch: 2.1.0
torchvision: 0.16.0
torchaudio: 2.1.2
triton: 2.1.0
onnxruntime: 1.15.0
Tips:以上dtk驱动、python、torch等DCU相关工具版本需要严格一一对应
2、其它非特殊库参照requirements.txt安装
pip install -r requirements.txt
## 数据集
数据集使用`cc3m-wds`,可通过[huggingface](https://hf-mirror.com/datasets/pixparse/cc3m-wds)下载。
本项目提供了数据处理的示例脚本,见[prepare_for_training.py](./prepare_for_training.py),使用该脚本可将下载好的数据处理为训练所需要的格式。
[
{"text": "a dog", "image_file": "dog.jpg"},
{"text": "a cat", "image_file": "cat.jpg"},
...
]
注意:数据集并不仅限于cc3m-wds,可参考[源项目](https://github.com/tencent-ailab/IP-Adapter/issues)获取更多数据集及格式要求。
## 训练
accelerate launch --num_processes 8 --multi_gpu --mixed_precision "fp16" \
tutorial_train.py \
--pretrained_model_name_or_path="runwayml/stable-diffusion-v1-5/" \
--image_encoder_path="{image_encoder_path}" \
--data_json_file="{data.json}" \
--data_root_path="{image_path}" \
--mixed_precision="fp16" \
--resolution=512 \
--train_batch_size=8 \
--dataloader_num_workers=4 \
--learning_rate=1e-04 \
--weight_decay=0.01 \
--output_dir="{output_dir}" \
--save_steps=10000
## 推理
按`预训练权重`部分下载完成后,执行文件中的`ip_adapter...ipynb`文件即可完成推理。
注意:使用`jupyter notebook --no-browser --ip=0.0.0.0 --allow-root`启动服务以运行代码。
## result
`ip_adapter_t2i-adapter_demo.ipynb`运行结果。
参考图片及深度图
## 环境配置
### Docker(方法一)
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.1.0-ubuntu20.04-dtk24.04.1-py3.10
docker run --shm-size 50g --network=host --name=ip-adapter --privileged --device=/dev/kfd --device=/dev/dri --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -v 项目地址(绝对路径):/home/ -v /opt/hyhal:/opt/hyhal:ro -it bash
pip install -r requirements.txt
### Dockerfile(方法二)
docker build -t : .
docker run --shm-size 50g --network=host --name=ip-adapter --privileged --device=/dev/kfd --device=/dev/dri --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -v 项目地址(绝对路径):/home/ -v /opt/hyhal:/opt/hyhal:ro -it bash
pip install -r requirements.txt
### Anaconda (方法三)
1、关于本项目DCU显卡所需的特殊深度学习库可从光合开发者社区下载安装:
https://developer.sourcefind.cn/tool/
DTK驱动:dtk24.04.1
python:python3.10
torch: 2.1.0
torchvision: 0.16.0
torchaudio: 2.1.2
triton: 2.1.0
onnxruntime: 1.15.0
Tips:以上dtk驱动、python、torch等DCU相关工具版本需要严格一一对应
2、其它非特殊库参照requirements.txt安装
pip install -r requirements.txt
## 数据集
数据集使用`cc3m-wds`,可通过[huggingface](https://hf-mirror.com/datasets/pixparse/cc3m-wds)下载。
本项目提供了数据处理的示例脚本,见[prepare_for_training.py](./prepare_for_training.py),使用该脚本可将下载好的数据处理为训练所需要的格式。
[
{"text": "a dog", "image_file": "dog.jpg"},
{"text": "a cat", "image_file": "cat.jpg"},
...
]
注意:数据集并不仅限于cc3m-wds,可参考[源项目](https://github.com/tencent-ailab/IP-Adapter/issues)获取更多数据集及格式要求。
## 训练
accelerate launch --num_processes 8 --multi_gpu --mixed_precision "fp16" \
tutorial_train.py \
--pretrained_model_name_or_path="runwayml/stable-diffusion-v1-5/" \
--image_encoder_path="{image_encoder_path}" \
--data_json_file="{data.json}" \
--data_root_path="{image_path}" \
--mixed_precision="fp16" \
--resolution=512 \
--train_batch_size=8 \
--dataloader_num_workers=4 \
--learning_rate=1e-04 \
--weight_decay=0.01 \
--output_dir="{output_dir}" \
--save_steps=10000
## 推理
按`预训练权重`部分下载完成后,执行文件中的`ip_adapter...ipynb`文件即可完成推理。
注意:使用`jupyter notebook --no-browser --ip=0.0.0.0 --allow-root`启动服务以运行代码。
## result
`ip_adapter_t2i-adapter_demo.ipynb`运行结果。
参考图片及深度图
 输出
输出
 ### 精度
DCU K100_AI与GPU L20精度一致,训练框架:pytorch。
## 应用场景
### 算法类别
`AIGC`
### 热点应用行业
`零售,广媒,教育`
## 预训练权重
ip-adapter_demo与kandinsky-2-2-prior所需权重可参考源github项目得README中的下载源进行下载。
```
pretrained_models
├── models
│ ├── image_encoder
│ │ ├── config.json
│ │ └── model.safetensors
| |── kandinsky-2-2-prior
│ ├── ip-adapter-full-face_sd15.safetensors
│ ├── ip-adapter-plus-face_sd15.safetensors
│ ├── ip-adapter-plus_sd15.safetensors
│ ├── ip-adapter_sd15.safetensors
│ └── ip-adapter_sd15_vit-G.safetensors
├── README.md
├── sd1.5
│ ├── diffusers
│ │ └── t2iadapter_depth_sd15v2
│ ├── dreamlike-anime-1.0
│ ├── lllyasviel
│ │ ├── control_v11f1p_sd15_depth
│ │ └── control_v11p_sd15_openpose
│ ├── Realistic_Vision_v4.0_noVAE
│ └── sd-vae-ft-mse
└── sdxl_models
├── controlnet
├── image_encoder
├── ip-adapter-plus-face_sdxl_vit-h.safetensors
├── ip-adapter-plus_sdxl_vit-h.safetensors
├── ip-adapter_sdxl.safetensors
└── RealVisXL_V1.0
```
## 源码仓库及问题反馈
* https://developer.sourcefind.cn/codes/modelzoo/ip-adapter_pytorch
## 参考资料
* https://github.com/tencent-ailab/IP-Adapter
### 精度
DCU K100_AI与GPU L20精度一致,训练框架:pytorch。
## 应用场景
### 算法类别
`AIGC`
### 热点应用行业
`零售,广媒,教育`
## 预训练权重
ip-adapter_demo与kandinsky-2-2-prior所需权重可参考源github项目得README中的下载源进行下载。
```
pretrained_models
├── models
│ ├── image_encoder
│ │ ├── config.json
│ │ └── model.safetensors
| |── kandinsky-2-2-prior
│ ├── ip-adapter-full-face_sd15.safetensors
│ ├── ip-adapter-plus-face_sd15.safetensors
│ ├── ip-adapter-plus_sd15.safetensors
│ ├── ip-adapter_sd15.safetensors
│ └── ip-adapter_sd15_vit-G.safetensors
├── README.md
├── sd1.5
│ ├── diffusers
│ │ └── t2iadapter_depth_sd15v2
│ ├── dreamlike-anime-1.0
│ ├── lllyasviel
│ │ ├── control_v11f1p_sd15_depth
│ │ └── control_v11p_sd15_openpose
│ ├── Realistic_Vision_v4.0_noVAE
│ └── sd-vae-ft-mse
└── sdxl_models
├── controlnet
├── image_encoder
├── ip-adapter-plus-face_sdxl_vit-h.safetensors
├── ip-adapter-plus_sdxl_vit-h.safetensors
├── ip-adapter_sdxl.safetensors
└── RealVisXL_V1.0
```
## 源码仓库及问题反馈
* https://developer.sourcefind.cn/codes/modelzoo/ip-adapter_pytorch
## 参考资料
* https://github.com/tencent-ailab/IP-Adapter