# InternVL3
## 论文
[Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks](https://arxiv.org/abs/2312.14238)
## 模型结构
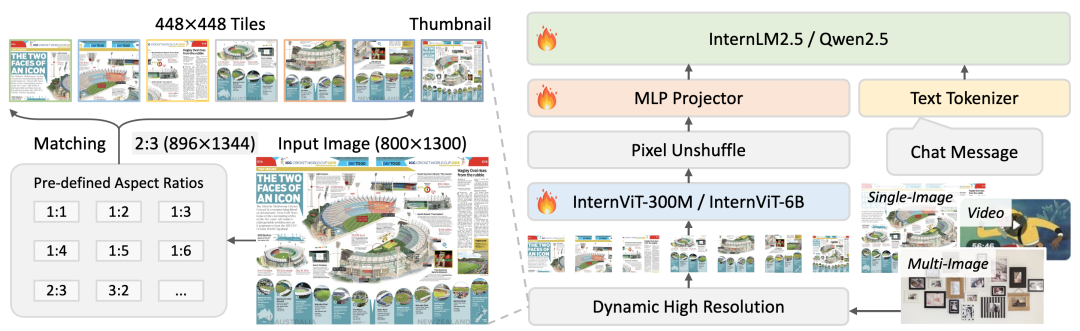
InternVL3 的架构沿袭了其前代模型采用的 “ViT-MLP-LLM” 范式。研究人员选择使用预训练的 ViT 和 LLM 组件初始化模型,以减少计算成本。
- 视觉编码器 (Vision Encoder): 提供 InternViT-300M 和 InternViT-6B 两种配置。
- 语言模型 (Language Model): 利用了 Qwen2.5 系列和 InternLM3-8B 的预训练基座模型(未经指令微调)。
- 高分辨率处理: InternVL3 沿袭 InternVL2.5 的做法,引入像素反混叠操作 (pixel unshuffle),将 448x448 图像块的视觉 token 数量减少到原始值的四分之一,增强处理高分辨率图像的可扩展性。
- 可变视觉位置编码 (V2PE): InternVL3 集成了 V2PE ([42]),通过使用更小、更灵活的视觉 token 位置增量来处理更长的多模态上下文。具体来说,文本 token 的位置增量仍为 1,而视觉 token 的位置增量 δ 小于 1。δ 在训练时从预定义的包含分数的小值集合中随机选择(例如 1/2, 1/4, ..., 1/256),并在推理时根据序列长度灵活选择。当 δ=1 时,V2PE 退化为 InternVL2.5 中使用的传统位置编码。
## 算法原理
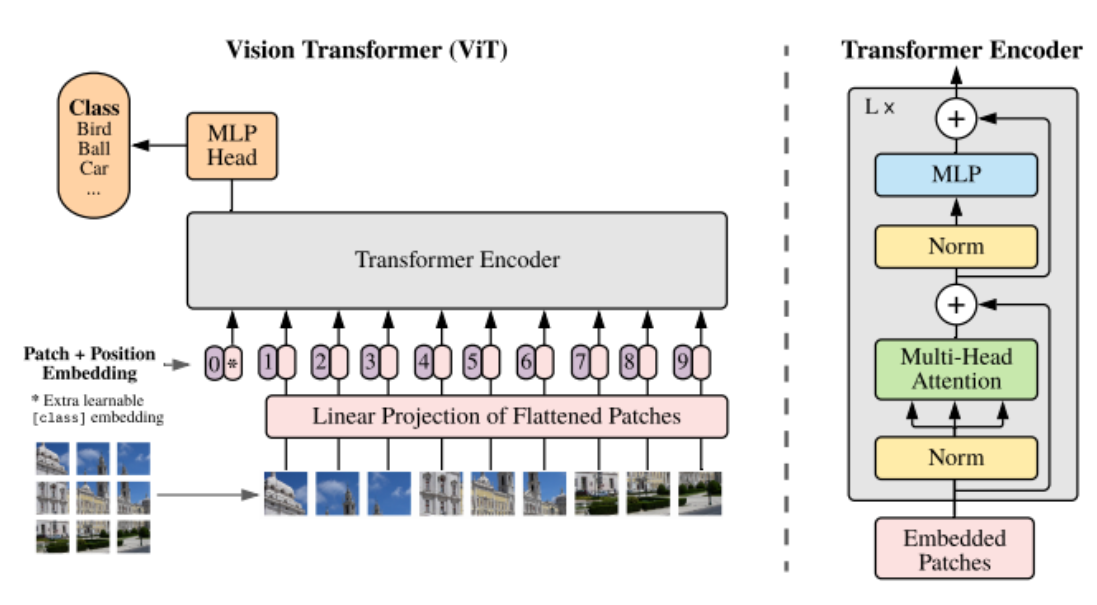
ViT是Google团队提出的将Transformer应用在图像分类的模型。ViT将输入图片分为多个patch(16x16),再将每个patch投影为固定长度的向量送入Transformer,后续encoder的操作和原始Transformer中完全相同。但是因为对图片分类,因此在输入序列中加入一个特殊的token,该token对应的输出即为最后的类别预测
## 环境配置
### Docker(方法一)
推荐使用docker方式运行, 此处提供[光源](https://www.sourcefind.cn/#/service-details)拉取docker镜像的地址与使用步骤
```
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.3.0-py3.10-dtk24.04.3-ubuntu20.04
docker run -it --shm-size=1024G -v /path/your_code_data/:/path/your_code_data/ -v /opt/hyhal:/opt/hyhal --network=host --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name internvl3 bash # 为以上拉取的docker的镜像ID替换
git clone http://developer.sourcefind.cn/codes/modelzoo/internvl3_pytorch.git
cd /path/your_code_data/
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
```
Tips:以上dtk驱动、python、torch等DCU相关工具版本需要严格一一对应。
### Dockerfile(方法二)
此处提供dockerfile的使用方法
```
git clone http://developer.sourcefind.cn/codes/modelzoo/internvl3_pytorch.git
docker build -t internvl:latest .
docker run --shm-size 500g --network=host --name=internvl3 --privileged --device=/dev/kfd --device=/dev/dri --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -v 项目地址(绝对路径):/home/ -v /opt/hyhal:/opt/hyhal:ro -it bash
cd /path/your_code_data/
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
```
### Anaconda(方法三)
此处提供本地配置、编译的详细步骤,例如:
关于本项目DCU显卡所需的特殊深度学习库可从[光合](https://developer.hpccube.com/tool/)开发者社区下载安装。
```
DTK驱动:dtk24.04.3
python:3.10
torch:2.3.0
transformers>=4.48.0
```
`Tips:以上dtk驱动、python、torch等DCU相关工具版本需要严格一一对应`
其它非深度学习库参照requirement.txt安装:
```
git clone http://developer.sourcefind.cn/codes/modelzoo/internvl3_pytorch.git
cd /path/your_code_data/
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
```
## 数据集
无
## 训练
无
## 推理
### 单机单卡
```
python internvl3_inference.py.py
```
### 单机多卡
```
CUDA_VISIBLE_DEVICES=0,1,2,3 internvl3_inference.py
```
## result
### 精度
无
## 应用场景
### 算法类别
`对话问答`
### 热点应用行业
`科研,教育,政府,金融`
## 预训练权重
HF/github下载地址为:[OpenGVLab/InternVL3](https://huggingface.co/collections/OpenGVLab/internvl3-67f7f690be79c2fe9d74fe9d)
魔搭下载路径:[OpenGVLab/InternVL3](https://www.modelscope.cn/collections/InternVL3-5d0bdc54b7d84e)
## 源码仓库及问题反馈
- https://developer.sourcefind.cn/codes/modelzoo/internvl3_pytorch
## 参考资料
- https://github.com/OpenGVLab/InternVL