
Initial commit
Showing
Too many changes to show.
To preserve performance only 323 of 323+ files are displayed.
icon.png
0 → 100644
{kind=link}
53.8 KB
images/arch.png
0 → 100644
{kind=link}
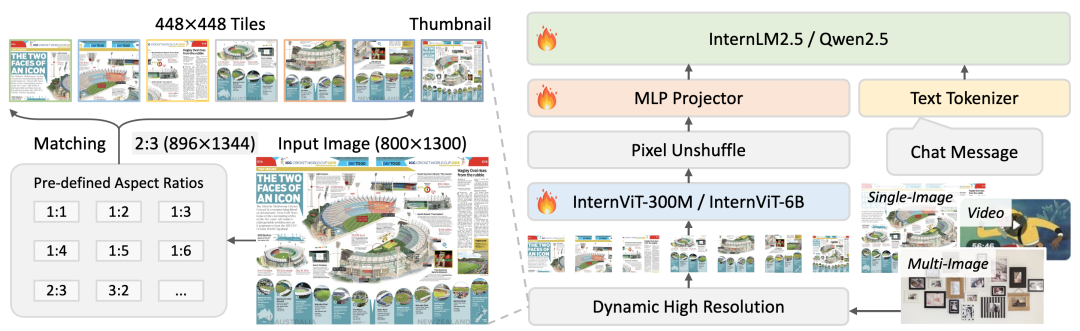
255 KB
images/result.png
0 → 100644
{kind=link}
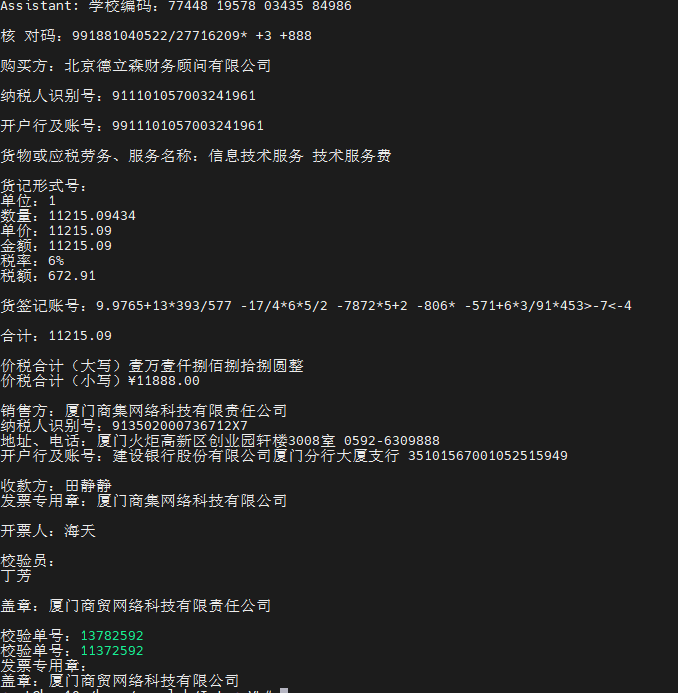
45.4 KB
images/theory.png
0 → 100644
{kind=link}
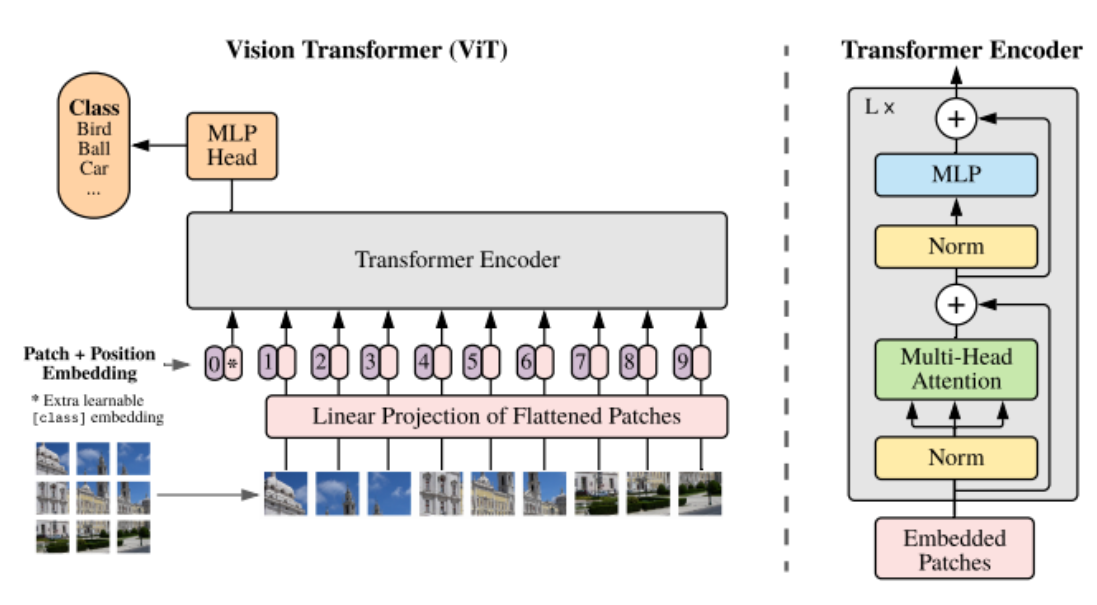
228 KB
internvl3_inference.py
0 → 100644
internvl_chat/README.md
0 → 100644
internvl_chat/eval/README.md
0 → 100644