
Initial commit
Showing
Too many changes to show.
To preserve performance only 232 of 232+ files are displayed.
icon.png
0 → 100644
{kind=link}
61 KB
images/fp.jpg
0 → 100644
{kind=link}

393 KB
images/model2.png
0 → 100644
{kind=link}
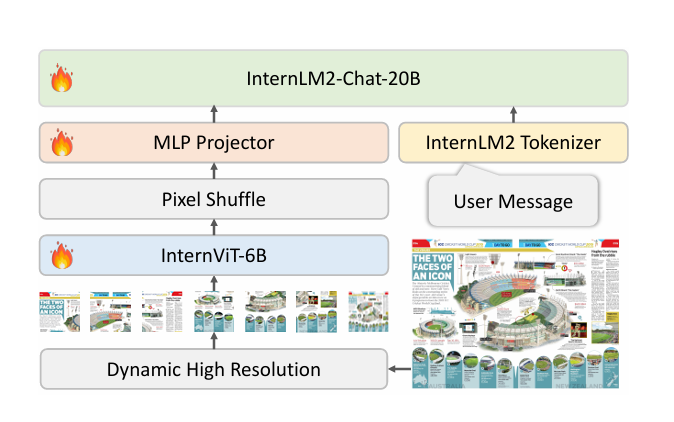
137 KB
images/ocr_result.png
0 → 100644
{kind=link}
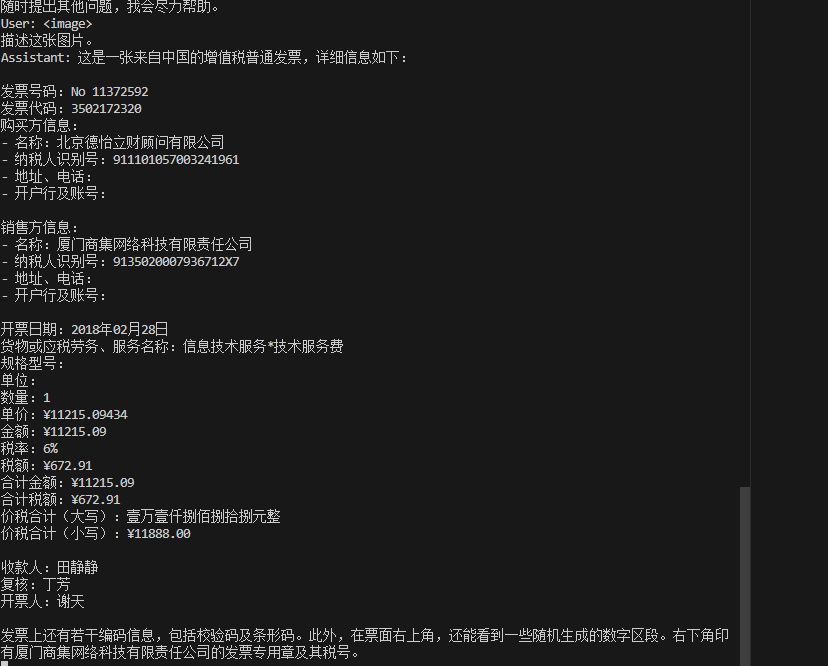
28.9 KB
images/qa_result.png
0 → 100644
{kind=link}
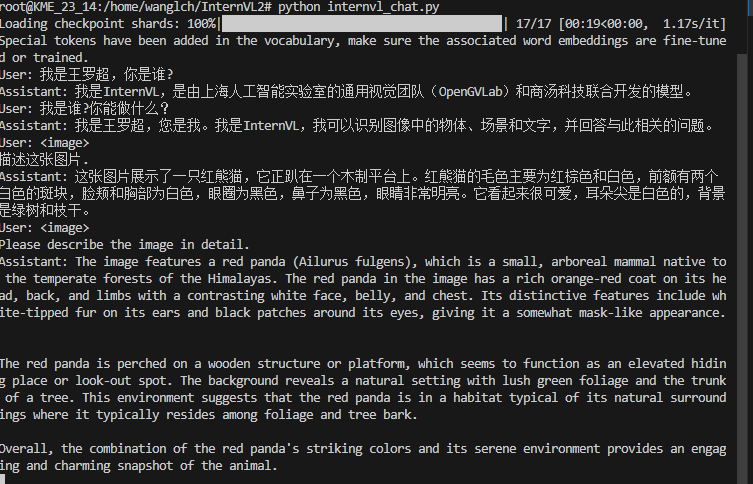
44.5 KB
images/structure.jpg
0 → 100644
{kind=link}

55.7 KB
images/train.png
0 → 100644
{kind=link}
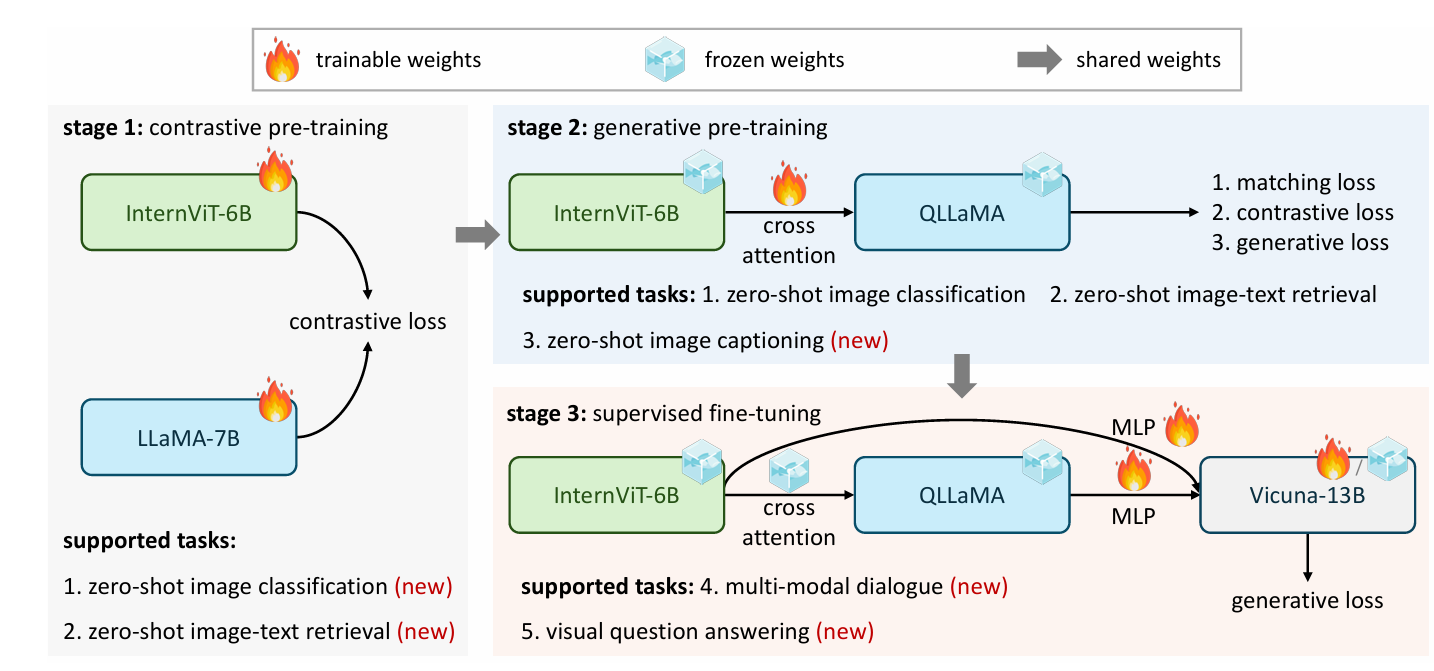
156 KB
internvl/conversation.py
0 → 100644
internvl/dist_utils.py
0 → 100644
internvl/model/__init__.py
0 → 100644