# InternLM_2.5
## 论文
`InternLM2 Technical Report`
- [https://arxiv.org/pdf/2403.17297]
## 模型结构
Internlm2.5与Internlm2模型结构相同,但取得更好效果,Internlm2采用LLama和GQA结构,相较于Internlm改进了Wqkv的权重矩阵进行交错重排,不再简单堆叠每个头的Wk、Wq和Wv矩阵。此交织重排操作大概能提高5%的训练效率。

## 算法原理
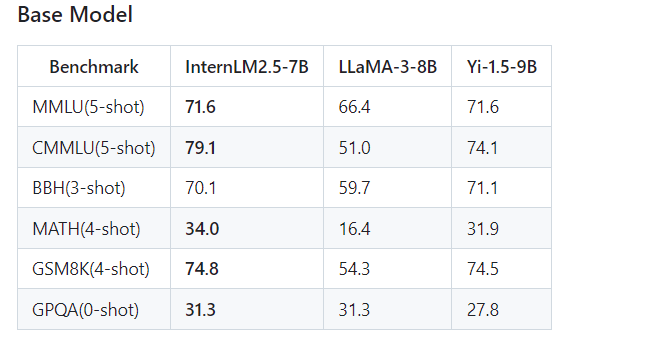
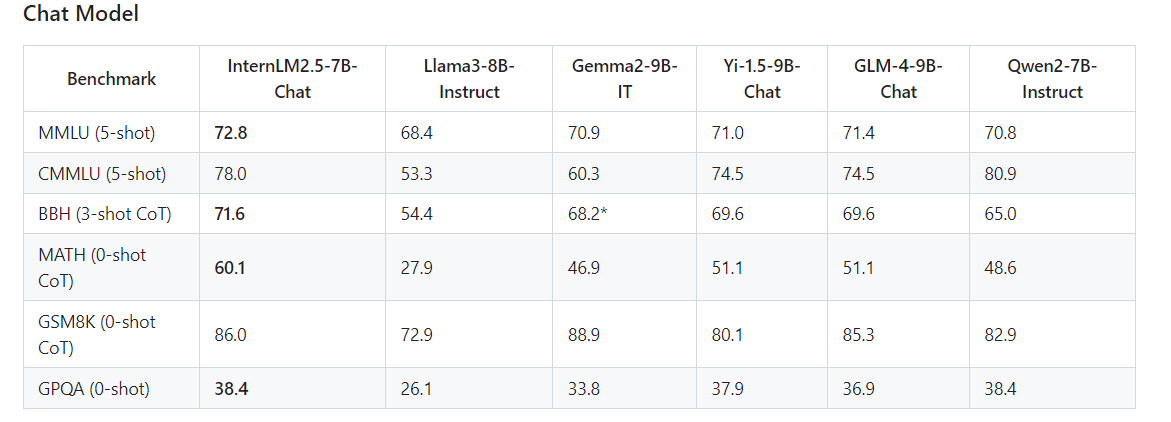
Internlm2.5主要是更新了7B系列的Chat模型。其中InternLM2.5-7B-Chat-1M模型支持百万长度的上下文窗口。主要核心点有三个:(1)卓越的模型推理能力,在数学推理的任务上达到了SOTA,超过了同等规模参数量的其他模型,如LLaMA3-8B和Gemma-9B;(2)支持百万长度上下文长度的推理,并且可以通过LMDeploy快速部署,开箱即用;(3)增加了更多的应用工具的支持
## 环境配置
### Docker(方法一)
此处提供[光源](https://www.sourcefind.cn/#/service-details)拉取 docker 镜像的地址与使用步骤
```
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.1.0-ubuntu20.04-dtk24.04.1-py3.10
docker run -it --shm-size=1024G -v : -v /opt/hyhal:/opt/hyhal --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name internlm bash # 为以上拉取的docker的镜像ID替换,本镜像为:a4dd5be0ca23
# bitsandbytes可从whl.zip文件里获取安装:
pip install bitsandbytes-0.42.0-py3-none-any.whl
pip uninstall vllm
```
### Dockerfile(方法二)
此处提供 dockerfile 的使用方法
```
docker build -t internlm_2.5_df:latest .
docker run -it --shm-size=1024G -v : -v /opt/hyhal:/opt/hyhal --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name internlm_2.5 internlm_2.5_df:latest bash
# bitsandbytes可从whl.zip文件里获取安装:
pip install bitsandbytes-0.42.0-py3-none-any.whl
pip uninstall vllm
```
### Anaconda(方法三)
此处提供本地配置、编译的详细步骤,例如:
关于本项目 DCU 显卡所需的特殊深度学习库可从[光合](https://developer.sourcefind.cn/tool/)开发者社区下载安装。
```
DTK驱动:dtk24.04
python:python3.10
torch: 2.1.0
deepspeed:0.12.3
bitsandbytes: 0.42.0
xtuner:0.1.21
```
`Tips:以上dtk驱动、python、paddle等DCU相关工具版本需要严格一一对应`
其它非深度学习库参照 requirements.txt 安装:
```
pip install -e . -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
```
## 数据集
使用tatsu-lab/alpaca数据集,[数据集链接](https://hf-mirror.com/datasets/tatsu-lab/alpaca), 本项目提供用于试验训练的迷你数据集,已经包含在data目录中,具体文件为alpaca_2000.parquet
## 训练
### xtuner 微调方法
1、训练库安装(非Internlm_2.5_pytorch目录下)
~~~
git clone https://github.com/InternLM/xtuner.git
cd xtuner
pip install -e '.[all]' -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
pip install mmengine==0.10.3
~~~
2、通过[预训练权重](https://hf-mirror.com/internlm/internlm2_5-7b-chat)下载预训练模型,当前用例使用internlm2_5-7b-chat模型;
3、修改internlm2_5_chat_7b_qlora_alpaca_e3.py代码中的pretrained_model_name_or_path、data_path为本地模型、数据地址
4、根据硬件环境和自身训练需求来调整max_length、batch_size、accumulative_counts、max_epochs、lr、save_steps、evaluation_freq、model.lora中的r、lora_alpha参数
5、${DCU_NUM}参数修改为要使用的DCU卡数量,不同数据集需要修改internlm2_5_chat_7b_qlora_alpaca_e3.py中SYSTEM、evaluation_inputs、dataset_map_fn、train_dataloader.sampler、train_cfg参数设置,详情请参考代码注释项,当前默认alpaca数据集,--work-dir设定保存模型路径;
~~~
NPROC_PER_NODE=${DCU_NUM} xtuner train ./internlm2_5_chat_7b_qlora_alpaca_e3.py --deepspeed deepspeed_zero2 --work-dir /path/of/saves
~~~
## 推理
(Internlm_2.5_pytorch目录下)
```
cd inference
python start.py
```
## result
使用的加速卡:1张 DCU-K100-64G
### 精度
使用opencompass在demo_gsm8k数据集上,对微调后的模型进行评估
| device | acc |
| :------: | :------: |
| DCU-K100AI | 87.50 |
| GPU-A800 | 87.50 |
## 应用场景
### 算法类别
对话问答
### 热点应用行业
`科研,教育,金融`
### 预训练权重
预训练权重下载中心: [hf-mirror](https://hf-mirror.com/internlm/internlm2_5-7b-chat)
## 源码仓库及问题反馈
- https://developer.sourcefind.cn/codes/modelzoo/internlm_2.5_pytorch
## 参考资料
- https://github.com/InternLM/InternLM/
- https://github.com/InternLM/xtuner
- https://hf-mirror.com/internlm/internlm2_5-7b-chat
