## From Images to Textual Prompts: Zero-shot VQA with Frozen Large Language Models
This is the official code for Img2LLM-VQA paper. We integrate the implementation into LAVIS.
Large language models (LLMs) have demonstrated excellent zero-shot generalization to new tasks. However, effective utilization of LLMs for zero-shot visual question-answering (VQA) remains challenging, primarily due to the modality disconnection and task disconnection between LLM and VQA task. We propose **Img2LLM**, a plug-and-play module that provides the prompts that can bridge the these disconnections, so that LLMs can perform VQA tasks without end-to-end training.
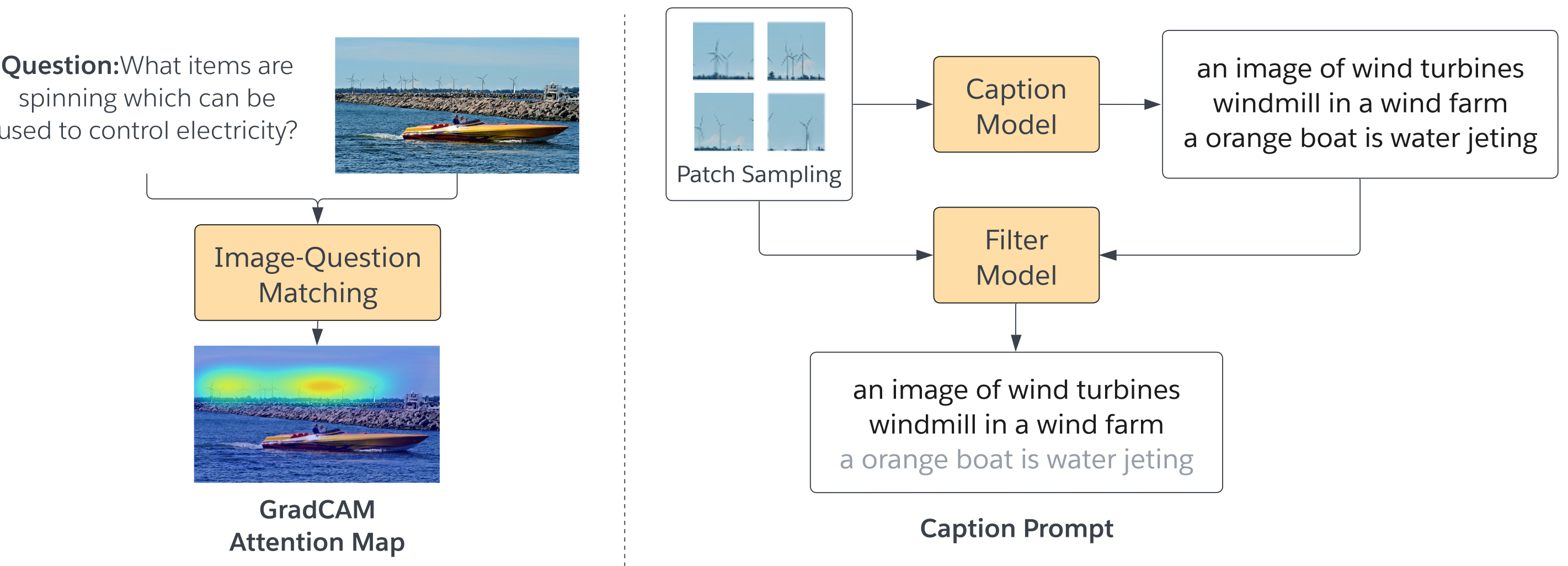
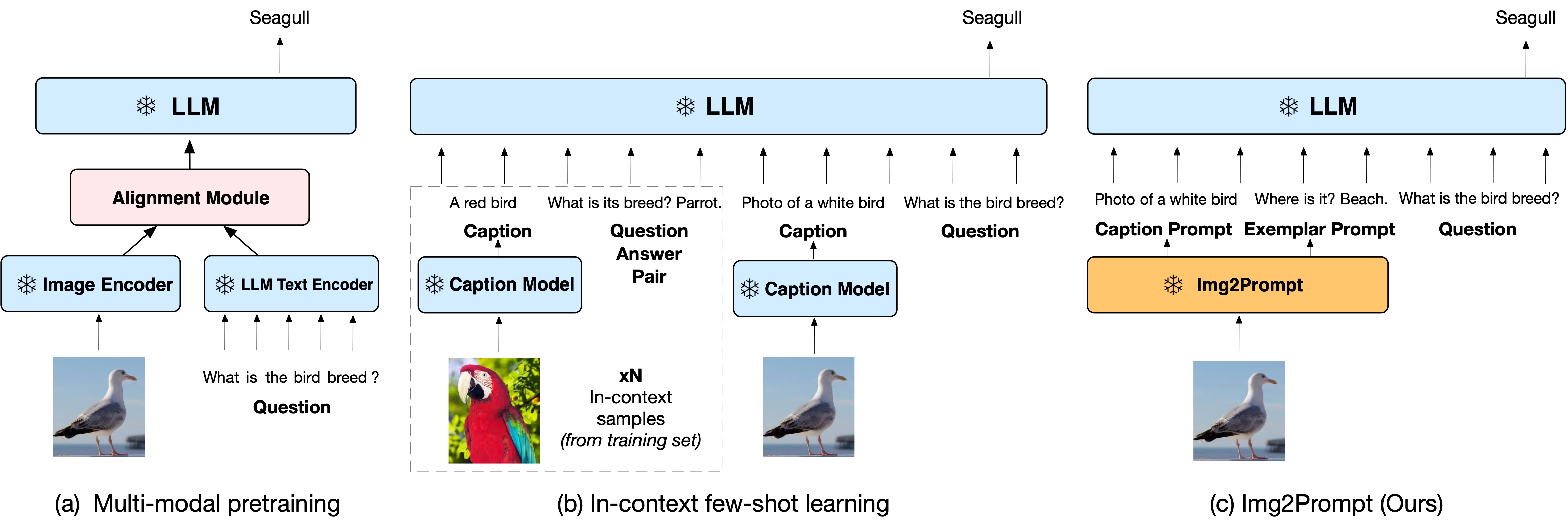 The following images illustrate the technical procedures of answer extraction, question generation and caption prompts in Img2LLM. See paper for details.
The following images illustrate the technical procedures of answer extraction, question generation and caption prompts in Img2LLM. See paper for details.

 ### Demo
We include an interactive demo [Colab notebook](https://colab.research.google.com/github/salesforce/LAVIS/blob/main/projects/img2llm-vqa/img2llm_vqa.ipynb)
to show Img2LLM-VQA inference workflow:
1. Image-question matching: compute the relevancy score of the image patches wrt the question, and remove the generated noisy captions with low relevancy score.
2. Image captioning: generate question-guided captions based on the relevancy score.
3. Question Generation: generate questions based on the synthetic answers and captions.
4. Large Language Model: Pre-trained lagre language models, e.g. OPT/GPT-3
### Zero-Shot Evaluation
### Demo
We include an interactive demo [Colab notebook](https://colab.research.google.com/github/salesforce/LAVIS/blob/main/projects/img2llm-vqa/img2llm_vqa.ipynb)
to show Img2LLM-VQA inference workflow:
1. Image-question matching: compute the relevancy score of the image patches wrt the question, and remove the generated noisy captions with low relevancy score.
2. Image captioning: generate question-guided captions based on the relevancy score.
3. Question Generation: generate questions based on the synthetic answers and captions.
4. Large Language Model: Pre-trained lagre language models, e.g. OPT/GPT-3
### Zero-Shot Evaluation
| Model |
End-to-End Training? |
VQAv2 val |
VQAv2 test |
OK-VQA test |
AOK-VQA val |
AOK-VQA test |
| Frozen-7Bbase |
✓ |
29.5 |
- |
5.9 |
- |
- |
| Flamingo-9Bbase |
✓ |
- |
51.8 |
44.7 |
- |
- |
| Flamingo-80Bbase |
✓ |
- |
56.3 |
50.6 |
- |
- |
| Img2LLM-VQA-OPT13B |
x |
57.1 |
57.3 |
39.9 |
33.3 |
33.0 |
| Img2LLM-VQA-OPT30B |
x |
59.5 |
60.4 |
41.8 |
36.9 |
36.0 |
| Img2LLM-VQA-OPT66B |
x |
59.9 |
60.3 |
43.2 |
38.7 |
38.2 |
| Img2LLM-VQA-OPT175B |
x |
60.6 |
61.9 |
45.6 |
42.9 |
40.7 |
To reproduce these evaluation results of Img2LLM-VQA with different LLMs, you can follow this [folder](https://github.com/CR-Gjx/Img2LLM) :
### Citation
If you find this code to be useful for your research, please consider citing.
```bibtex
@misc{guo2023from,
title={From Images to Textual Prompts: Zero-shot {VQA} with Frozen Large Language Models},
author={Jiaxian Guo and Junnan Li and Dongxu Li and Anthony Tiong and Boyang Li and Dacheng Tao and Steven HOI},
year={2023},
url={https://openreview.net/forum?id=Ck1UtnVukP8}
}
```