
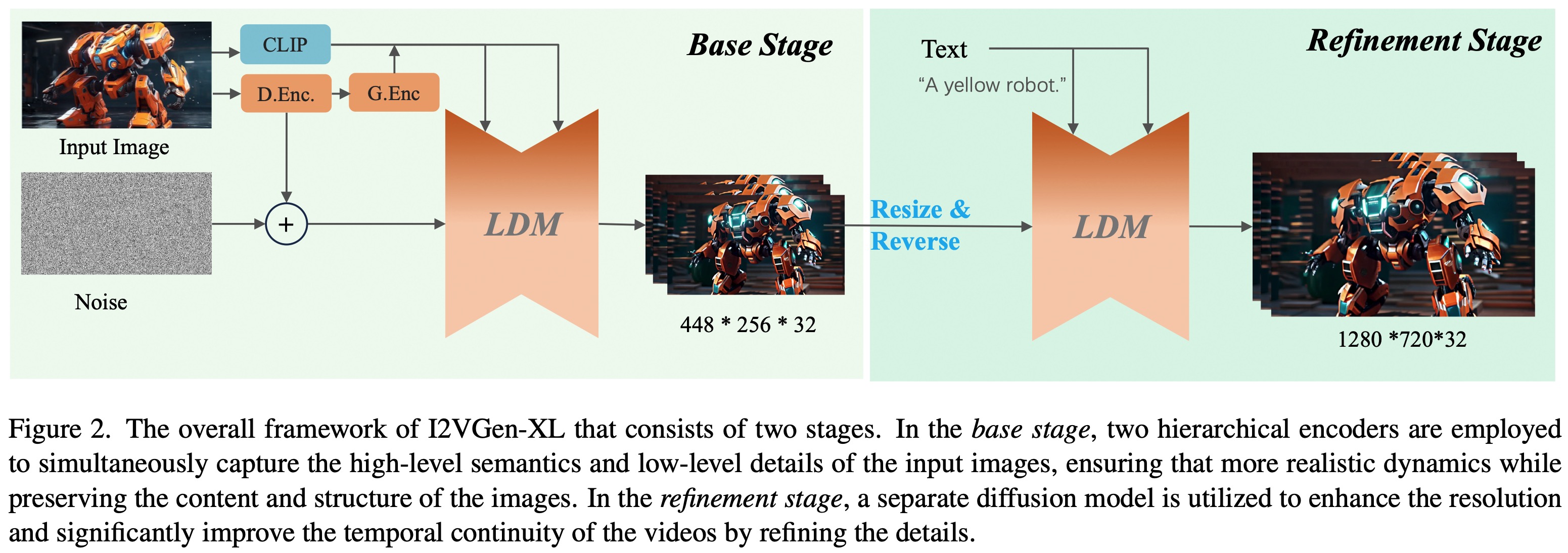
i2vgen-xl
Showing
source/fig_vs_vgen.jpg
0 → 100644
{kind=link}
401 KB
source/i2vgen_fig_01.jpg
0 → 100644
{kind=link}

938 KB
source/i2vgen_fig_02.jpg
0 → 100644
{kind=link}
603 KB
source/i2vgen_fig_04.png
0 → 100644
{kind=link}

3.94 MB
source/logo.png
0 → 100644
{kind=link}
4.32 KB
test_func/test_EndDec.py
0 → 100644
test_func/test_dataset.py
0 → 100644
test_func/test_models.py
0 → 100644
test_func/test_save_video.py
0 → 100644
tools/__init__.py
0 → 100644
File added
tools/annotator/util.py
0 → 100755