# Hunyuan-A13B
## 论文
[Hunyuan-A13B Technical Report](https://github.com/Tencent-Hunyuan/Hunyuan-A13B/blob/main/report/Hunyuan_A13B_Technical_Report.pdf)
## 模型结构
Hunyuan-A13B 具备以下特点:
- 小参数量,高性能: 仅激活130亿参数(总参数量800亿),即可在多样化基准任务中媲美更大规模模型的竞争力表现
- 混合推理支持: 同时支持快思考和慢思考两种模式,支持用户灵活选择
- 超长上下文理解: 原生支持256K上下文窗口,在长文本任务中保持稳定性能
- 增强Agent能力: 优化Agent能力,在BFCL-v3、τ-Bench、C3-Bench等智能体基准测试中领先
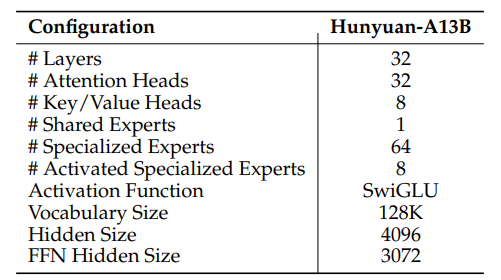
- 激活专家数: 8
- 高效推理: 采用分组查询注意力(GQA)策略,支持多量化格式,实现高效推理。
关键超参数如下:
## 算法原理
Hunyuan-A13B融合了多项创新要素,从整体上提升了模型的推理性能、灵活性和推理效率。首先,构建了高质量的预训练语料库,通过跨领域精选数据形成规模达20T token的稳健语料体系。特别强化了STEM领域数据的质量标准,从而提升模型推理能力的上限。其次,收集并利用了高质量的长思维链监督微调数据,显著增强了模型的逻辑推理与复杂问题解决能力。随后,开展大规模强化学习训练,通过迭代优化系统化提升推理性能。第三,Hunyuan-A13B采用双思维链推理策略,针对简单查询提供简洁的短链推理,而对复杂任务则生成详尽的长链推理。用户可根据应用场景的复杂度与资源限制灵活选择这两种模式。最后,推理优化方面的重大突破显著提升了token吞吐量与推理性能,使模型能够高效应对需要快速可靠预测的实时资源受限场景。
## 环境配置
### 硬件需求
DCU型号:BW1000,节点数量:1台,卡数:4张。
`-v 路径`、`docker_name`和`imageID`根据实际情况修改
### Docker(方法一)
```bash
docker pull image.sourcefind.cn:5000/dcu/admin/base/vllm:0.9.2-ubuntu22.04-dtk25.04.1-rc5-rocblas101839-0811-das1.6-py3.10-20250812-beta
docker run -it --shm-size 200g --network=host --name {docker_name} --privileged --device=/dev/kfd --device=/dev/dri --device=/dev/mkfd --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -u root -v /path/your_code_data/:/path/your_code_data/ -v /opt/hyhal/:/opt/hyhal/:ro {imageID} bash
cd /your_code_path/hunyuan-a13b-vllm
```
### Dockerfile(方法二)
```bash
cd docker
docker build --no-cache -t hunyuan-a13b:latest .
docker run -it --shm-size 200g --network=host --name {docker_name} --privileged --device=/dev/kfd --device=/dev/dri --device=/dev/mkfd --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -u root -v /path/your_code_data/:/path/your_code_data/ -v /opt/hyhal/:/opt/hyhal/:ro {imageID} bash
cd /your_code_path/hunyuan-a13b-vllm
```
### Anaconda(方法三)
关于本项目DCU显卡所需的特殊深度学习库可从[光合](https://developer.sourcefind.cn/tool/)开发者社区下载安装。
```bash
DTK: 25.04.1
python: 3.10
vllm: 0.9.2+das.opt1.beta.dtk25041
torch: 2.5.1+das.opt1.dtk25041
accelerate:1.10.0
transformers: 4.55.0
flash_attn:2.6.1+das.opt14.dtk2504
```
`Tips:以上dtk驱动、python、torch等DCU相关工具版本需要严格一一对应`
## 数据集
无
## 训练
暂无
## 推理
### vllm推理方法
#### server 单机
样例模型:[Hunyuan-A13B-Instruct](https://huggingface.co/tencent/Hunyuan-A13B-Instruct)
```bash
export HIP_VISIBLE_DEVICES=0,1,2,3
vllm serve tencent/Hunyuan-A13B-Instruct --trust-remote-code --dtype bfloat16 --max-seq-len-to-capture 32768 -tp 4 --gpu-memory-utilization 0.85 --override-generation-config '{"temperature": 0.7, "top_p":0.8, "top_k":20, "repetition_penalty": 1.05}' --max-model-len 32768
```
启动完成后可通过以下方式访问:
```bash
curl http://x.x.x.x:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "tencent/Hunyuan-A13B-Instruct",
"messages": [
{
"role": "user",
"content": "你是谁,你能做什么."
}
]
}'
```
## result
### 精度
DCU与GPU精度一致,推理框架:vllm。
## 应用场景
### 算法类别
对话问答
### 热点应用行业
制造,广媒,家居,教育
## 预训练权重
- [Hunyuan-A13B-Instruct](https://huggingface.co/tencent/Hunyuan-A13B-Instruct)
## 源码仓库及问题反馈
- https://developer.sourcefind.cn/codes/modelzoo/hunyuan-a13b-vllm
## 参考资料
- https://github.com/Tencent-Hunyuan/Hunyuan-A13B