
huatuogpt-o1
parents
Showing
readme_imgs/alg.png
0 → 100644
{kind=link}
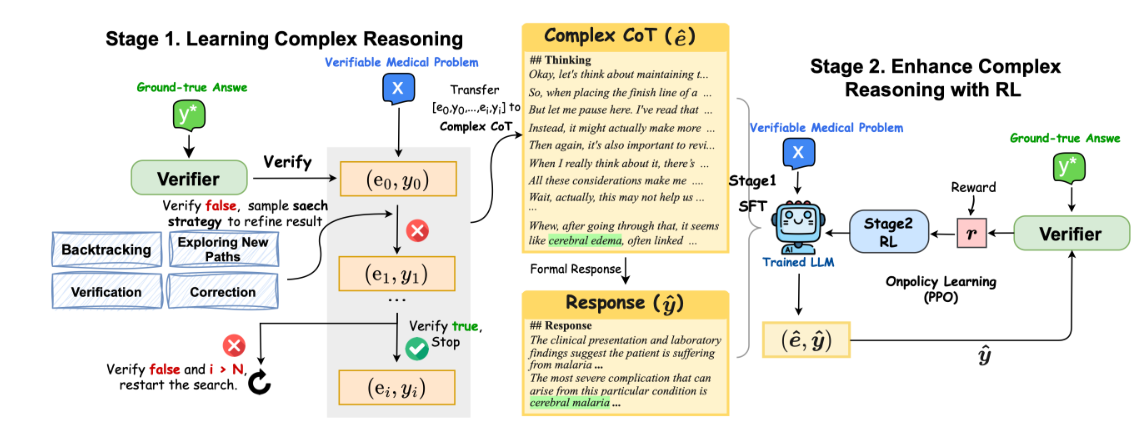
226 KB
readme_imgs/arch.png
0 → 100644
{kind=link}
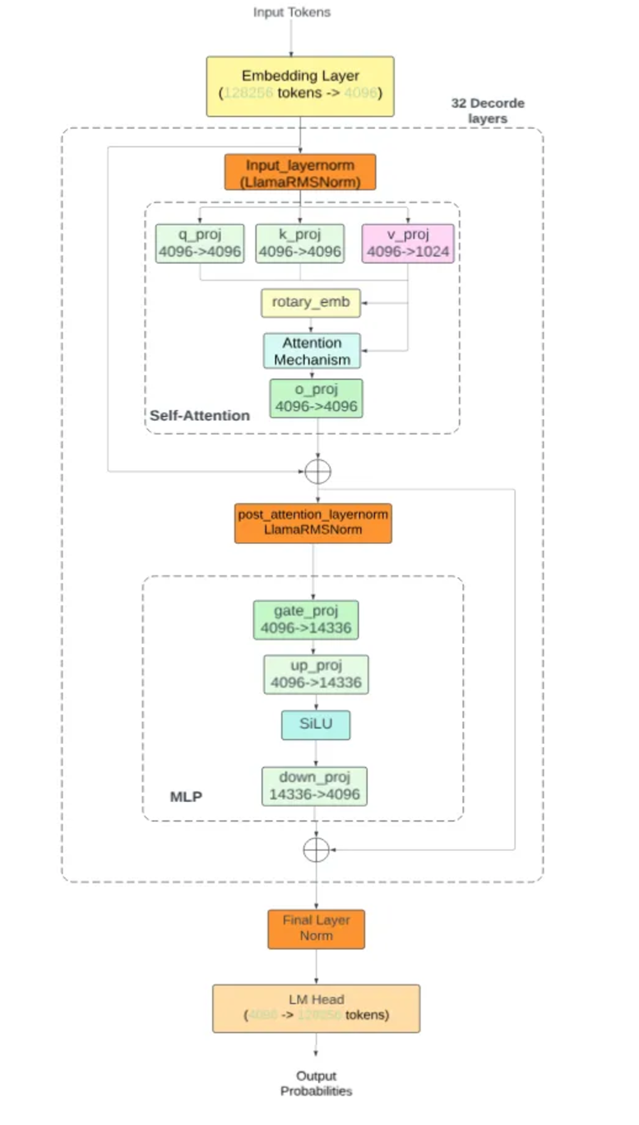
259 KB
readme_imgs/result.png
0 → 100644
{kind=link}

202 KB
requirements.txt
0 → 100644
| trl==0.13.0 | ||
| accelerate==0.34.2 | ||
| # torch==2.5.1 | ||
| transformers==4.46.2 | ||
| # deepspeed==0.15.4 | ||
| # xformers==0.0.28 | ||
| # vllm==0.6.4 | ||
| # torchvision==0.20.1 | ||
| retrying | ||
| \ No newline at end of file |