# HDETR
## 论文
[DETRs with Hybrid Matching](https://arxiv.org/abs/2207.13080)
## 模型结构
基于DETR结构,在匹配阶段加入一对多的匹配分支。

## 算法原理
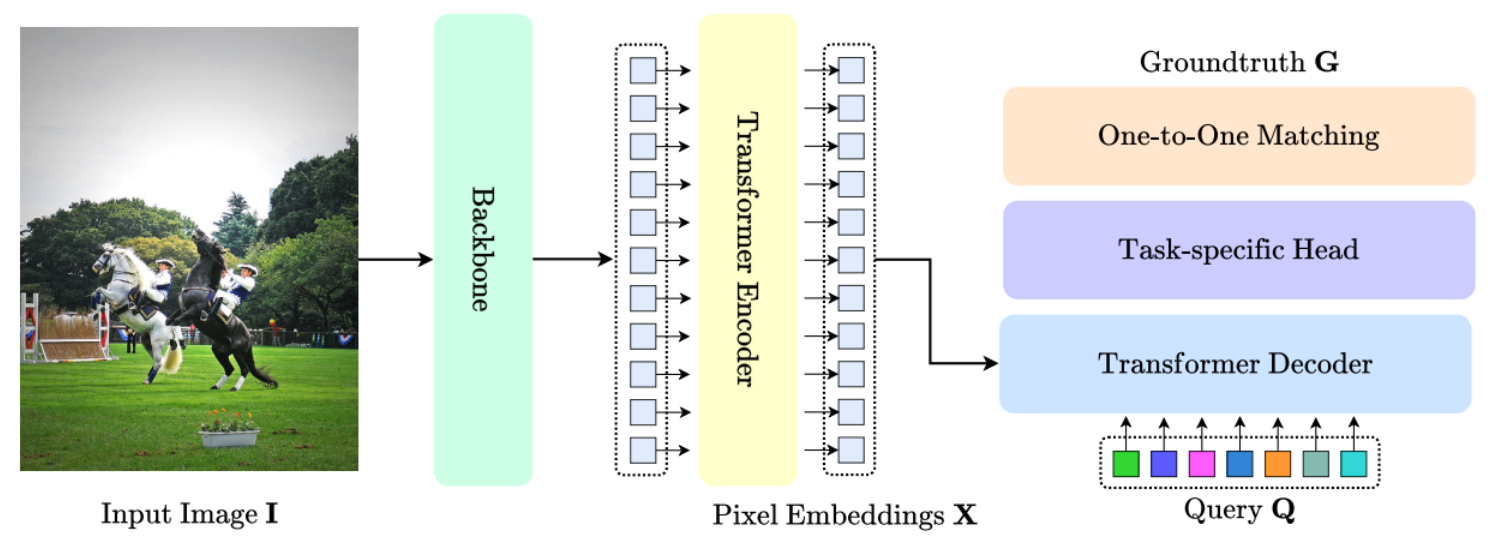
H-DETR引入一对多匹配分支,将原始的一对一匹配分支与一个辅助的一对多匹配分支结合起来,允许多个查询分配给每个正样本,增加正样本查询数量,提高训练效果。此外,H-DETR在推理过程中仍然使用原始的一对一匹配分支,以保持DETR的优势。
## 环境配置
注意:requirements.txt安装完成后,还需要额外安装下列包
```
pip install openmim
mim install mmcv-full (注意版本是不是1.7.1)
pip install mmdet==2.26.0 (对应mmcv 1.7.1)
```
-v 路径、docker_name和imageID根据实际情况修改
### Docker(方法一)
```
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:1.13.1-centos7.6-dtk-23.04.1-py38-latest
docker run -it -v /path/your_code_data/:/path/ your_code_data/ --shm-size=80G --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name docker_name imageID bash
cd /your_code_path/HDETR_pytorch
pip install -r requirements.txt
```
### Dockerfile(方法二)
```
cd ./docker
cp ../requirements.txt requirements.txt
docker build --no-cache -t hdetr:latest .
docker run -it -v /path/your_code_data/:/path/your_code_data/ --shm-size=80G --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name docker_name imageID bash
```
### Anaconda(方法三)
1、关于本项目DCU显卡所需的特殊深度学习库可从光合开发者社区下载安装: https://developer.hpccube.com/tool/
```
DTK软件栈:dtk23.04.1
python:python3.8
torch:1.13.1
torchvision:0.14.1
```
Tips:以上dtk软件栈、python、torch等DCU相关工具版本需要严格一一对应
2、其他非特殊库直接按照requirements.txt安装
```
pip3 install -r requirements.txt
```
## 数据集
COCO2017
[训练数据](http://images.cocodataset.org/zips/train2017.zip)
[验证数据](http://images.cocodataset.org/zips/val2017.zip)
[测试数据](http://images.cocodataset.org/zips/test2017.zip)
[标签数据](https://github.com/ultralytics/yolov5/releases/download/v1.0/coco2017labels.zip)
数据集的目录结构如下:
```
├── COCO2017
│ ├── images
│ ├── train2017
│ ├── val2017
│ └── test2017
│ ├── annotations
│ ├── instances_train2017.json
│ └── instances_val2017.json
```
训练/验证集数据准备:
训练/验证集都是采用的COCO的数据格式,如果使用自己的标注数据,请先将标注数据转换成COCO的格式,并按照上面的目录结构进行存放。
## 训练
训练前的准备工作:
1. 进行下面步骤编译
```
cd ./models/ops
bash ./make.sh
```
2. 进行单元测试,需要所有的结果都为TRUE
```
python test.py
cd ../../
```
3. 选择需要训练的模型的config, 设置为需要训练的模型属性, 设置为当前环境中训练数据对应地址。
Tips:
1. 如果有预训练模型,修改config中的 --pretrained_backbone_path 为保存的预训练模型地址;
2. 如果使用backbone为swin,可前往 https://github.com/microsoft/Swin-Transformer 选择对应的预训练模型后再进行训练步骤。
### 单机单卡
```
bash train.sh
```
### 单机多卡
```
bash train_multi.sh
```
### 多机多卡
#### slurm cluster训练方式
分区名称
本次执行的任务名称,建议可以使用{模型}_卡数_单卡bs_日期进行命名
需要训练的模型属性, 参见configs文件夹下选择
1 node with 4 DCUs:
```
GPUS_PER_NODE=4 ./tools/run_dist_slurm.sh 4
```
2 nodes(example is 2) of each with 4 DCUs:
```
GPUS_PER_NODE=4 ./tools/run_dist_slurm.sh 8
```
## 推理
验证前需提前准备好预训练模型,设置为模型地址,为当前环境中推理数据的对应地址,数据应为COCO数据格式。
如没有预训练模型,可从 参考资料 中提供的模型下载,选择模型对应的config后进行效果验证。
如果想要查看预测效果(预测结果输出到图片上),请执行:
```
python test.py --pre_trained_model --coco_path
```
其余对应参数与训练模型参数需一致,详情请参考代码里面的参数配置:
#### 单卡推理
```
bash val.sh
```
#### 多卡推理
```
bash val_multi.sh
```
## result
COCO2017测试集上的单张图像结果展示:
### 精度
在COCO2017的测试集上进行单卡测试,结果如下表所示
根据测试结果情况填写表格:
| Name | Backbone | query | epochs | AP |
| :--------: | :------: | :------: | :------: | :------: |
| H-Deformable-DETR + tricks(our) | R50 | 300 | 12 | xxx |
| H-Deformable-DETR + tricks | R50 | 300 | 12 | 48.7 |
## 应用场景
### 算法类别
目标检测
### 热点应用行业
网安,交通,政府
## 源码仓库及问题反馈
https://developer.hpccube.com/codes/modelzoo/hdetr_pytorch
## 参考资料
https://github.com/HDETR/H-Deformable-DETR
