# HAT
## 论文
[HAT: Hybrid Attention Transformer for Image Restoration](https://arxiv.org/abs/2309.05239)
## 模型结构
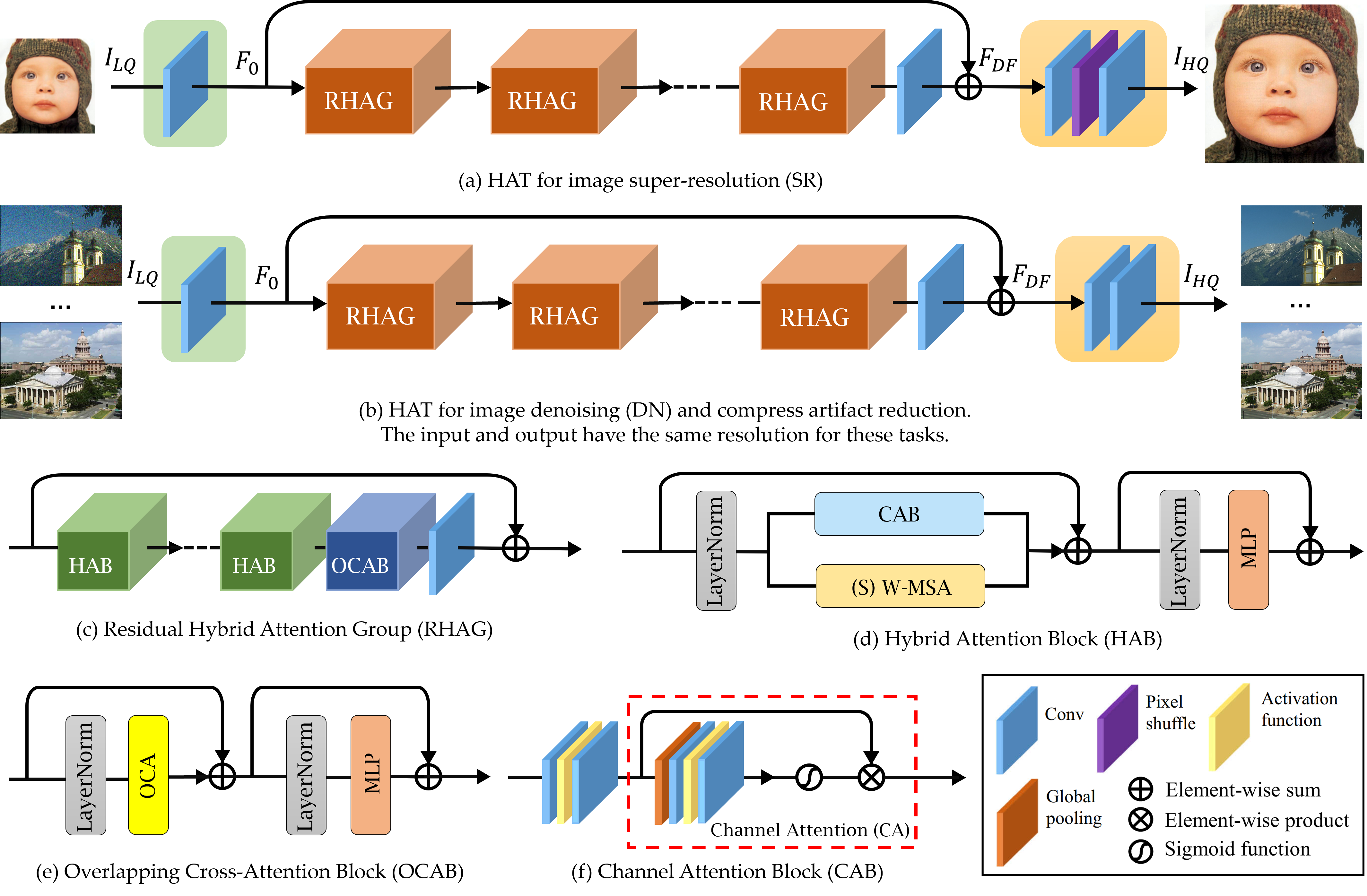
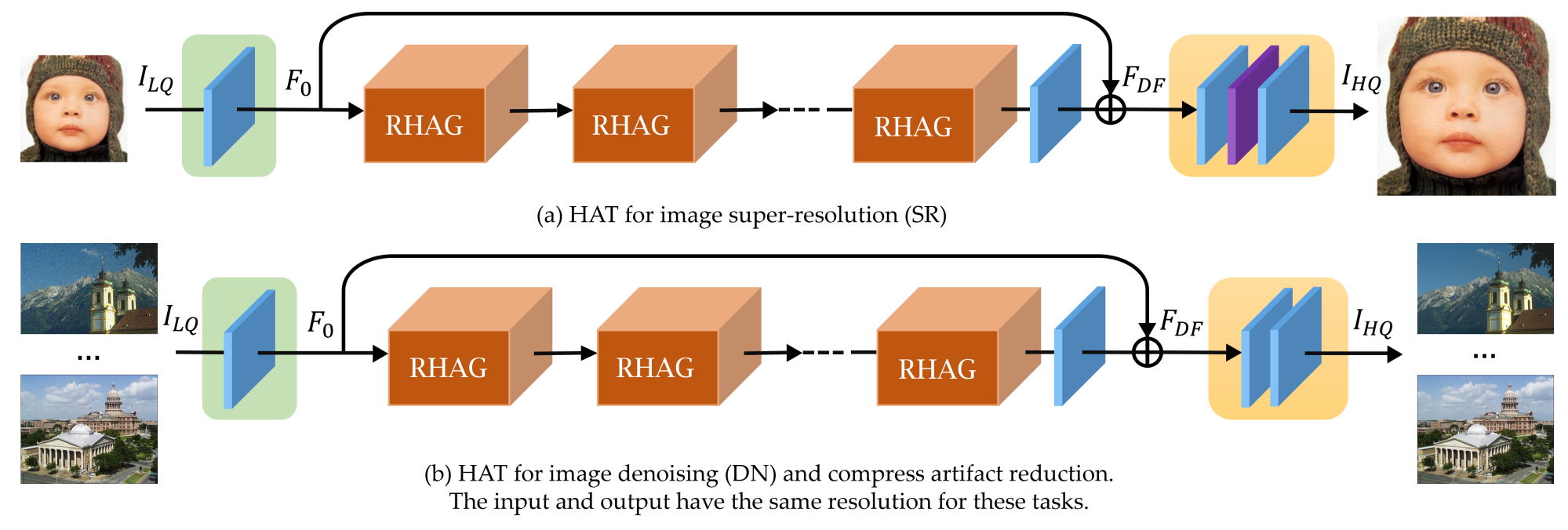
HAT包括三个部分,包括浅层特征提取、深层特征提取和图像重建。
## 算法原理
HAT方法结合了通道注意力和基于窗口的自注意力方案,利用两者的互补优势。此外,引入了重叠的跨注意力模块来增强相邻窗口特征之间的交互, 更好地聚合跨窗口信息。在训练阶段,HAT还采用了相同的任务预训练策略,以进一步挖掘模型的潜力进行进一步改进。得益于这些设计,HAT可以激活更多的像素进行重建,从而显著提高性能。
## 环境配置
-v 路径、docker_name和imageID根据实际情况修改
### Docker(方法一)
```bash
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:1.13.1-centos7.6-dtk23.10-py38
docker run -it -v /path/your_code_data/:/path/your_code_data/ -v /opt/hyhal/:/opt/hyhal/ --shm-size=32G --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name docker_name imageID bash
cd /your_code_path/hat_pytorch
pip install -r requirements.txt
python setup.py develop
```
### Dockerfile(方法二)
```bash
cd ./docker
cp ../requirements.txt requirements.txt
docker build --no-cache -t hat:latest .
docker run -it -v /path/your_code_data/:/path/your_code_data/ -v /opt/hyhal/:/opt/hyhal/ --shm-size=32G --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name docker_name imageID bash
cd /your_code_path/hat_pytorch
pip install -r requirements.txt
python setup.py develop
```
### Anaconda(方法三)
1、关于本项目DCU显卡所需的特殊深度学习库可从光合开发者社区下载安装: https://developer.hpccube.com/tool/
```bash
DTK软件栈:dtk23.10
python:python3.8
torch:1.13.1
torchvision:0.14.1
```
Tips:以上dtk软件栈、python、torch等DCU相关工具版本需要严格一一对应
2、其他非特殊库直接按照requirements.txt安装
```
pip install -r requirements.txt
python setup.py develop
```
## 数据集
训练:
[ImageNet dataset](https://image-net.org/challenges/LSVRC/2012/2012-downloads.php)
[DIV2K](https://data.vision.ee.ethz.ch/cvl/DIV2K/)
[Flickr2K](https://cv.snu.ac.kr/research/EDSR/Flickr2K.tar)
Tips: DF2K: DIV2K 和 Flickr2 数据的整合
训练数据处理请参考[BasicSR](https://github.com/XPixelGroup/BasicSR/blob/master/docs/DatasetPreparation.md)
测试:
[Classical SR Testing](https://drive.google.com/drive/folders/1gt5eT293esqY0yr1Anbm36EdnxWW_5oH?usp=sharing)
数据准备具体步骤如下:
1. 将数据存放在datasets目录下, 数据集的目录结构如下:
```
├── DF2K
│ ├── DF2K_HR # HR 数据
│ ├── DF2K_HR_sub # 生成的
│ ├── DF2K_bicx4 # train_LR_bicubic_X4 数据
│ ├── DF2K_bicx4_sub # 生成的
├── Set5
│ ├── GTmod12
│ ├── LRbicx2
│ ├── LRbicx3
│ ├── LRbicx4
│ ├── original
├── Set14
│ ├── GTmod12
│ ├── LRbicx2
│ ├── LRbicx3
│ ├── LRbicx4
│ ├── original
```
Tips: 项目提供了tiny_datasets用于快速上手学习, 如果实用tiny_datasets, 需要对下面的代码内的地址进行替换, 当前默认完整数据集的处理地址。
2. 因为 DF2K 数据集是 2K 分辨率的 (比如: 2048x1080), 而我们在训练的时候往往并不要那么大 (常见的是 128x128 或者 192x192 的训练patch). 因此我们可以先把2K的图片裁剪成有overlap的 480x480 的子图像块. 然后再由 dataloader 从这个 480x480 的子图像块中随机crop出 128x128 或者 192x192 的训练patch.
```bash
python extract_subimages.py # 将图片进行sub
```
3. 生成 meta_info_file
```bash
python scripts/data_preparation/generate_meta_info.py
```
## 训练
训练日志及weights保存在./experiments文件中
### 单机多卡
```bash
bash train.sh
```
### 多机多卡
1. 修改run.sh中18行所需虚拟环境变量地址;
2. 修改single_process.sh中22行所需训练的yaml文件地址,如与默认一致,可不修改。
执行命令如下, 训练日志保存在logs文件夹下
```bash
bash run.sh
```
## 推理
预训练模型下载地址:[Google Drive](https://drive.google.com/drive/folders/1HpmReFfoUqUbnAOQ7rvOeNU3uf_m69w0?usp=sharing) or [百度网盘](https://pan.baidu.com/s/1u2r4Lc2_EEeQqra2-w85Xg) (access code: qyrl)。
测试结果将保存到 ./results 路径下。
options/test/HAT_SRx4_ImageNet-LR.yml 适用于不适用ground truth image的推理过程。
```bash
bash val.sh
```
## result
基于 Real_HAT_GAN_SRx4_sharper.pth 的测试结果展示
### 精度
未经x2预训练的SRx4上的基准PSNR测试结果, Mulit-Adds针对64x64输入的计算。
| Model | Params(M) | Multi-Adds(G) | Set5 | Set14 | BSD100 | Urban100 | Manga109 |
| :------: | :------: | :------: | :------: |:------: | :------: | :------: |:------:|
| HAT-S | 9.6 | 54.9 | 32.92 | 29.15 | 27.97 | 27.87 | 32.35 |
| HAT | 20.8 | 102.4 | 33.04 | 29.23 | 28.00 | 27.97 | 32.48 |
| HAT(our) | 20.8 | 102.4 | 33.1486 | xxx | xxx | xxx | xxx |
## 应用场景
### 算法类别
图像重建
### 热点应用行业
交通,公安,制造
## 源码仓库及问题反馈
- https://developer.hpccube.com/codes/modelzoo/hat_pytorch
## 参考资料
- https://github.com/XPixelGroup/HAT?tab=readme-ov-file