# GPT
本示例主要通过使用MIGraphX C++ API对GPT2模型进行推理,包括预处理、模型推理以及数据后处理。
## 模型简介
GPT(Generative Pre-trained Transformer)系列模型以不断堆叠transformer中的decoder模块为特征提取器,提升训练语料的规模和质量、模型的参数量进行迭代更新。GPT-1主要通过在无标签的数据上学习一个通用的语言模型,再根据特定的任务进行微调处理有监督任务;GPT-2在GPT-1的模型结构上使用更多的模型参数和数据集,训练一个泛化能力更强的词向量模型。GPT-3更是采用海量的模型参数和数据集,训练了一个更加强大的语言模型。
| 模型 | 发布时间 | 参数量 | 预训练数据量 |
| ----- | ------------ | -------- | ------------ |
| GPT-1 | 2018 年 6 月 | 1.17 亿 | 约 5GB |
| GPT-2 | 2019 年 2 月 | 15 亿 | 40GB |
| GPT-3 | 2020 年 5 月 | 1,750 亿 | 45TB |
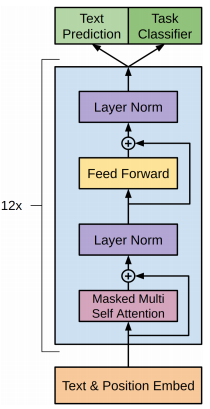
本次采用GPT-2模型进行诗词生成任务,模型文件下载链接:https://pan.baidu.com/s/1KWeoUuakCZ5dualK69qCcw, 提取码:4pmh。将GPT2_shici.onnx模型文件保存在Resource/文件夹下。整体模型结构如下图所示,也可以通过netron工具:https://netron.app/ 查看GPT-2的模型结构。
 ## 预处理
在将文本输入到模型之前,需要做如下预处理:
1.加载词汇表
2.文本编码
首先,根据提供的词汇表路径,通过cuBERT::FullTokenizer()函数加载词汇表,用于后续对输入文本的编码操作。其次,将词汇表中的内容依次保存到vector容器output中,用于数据后处理中的解码操作。
```c++
cuBERT::FullTokenizer tokenizer = cuBERT::FullTokenizer("../Resource/vocab_shici.txt");
std::ifstream infile;
std::string buf;
std::vector output;
infile.open("../Resource/vocab_shici.txt");
while (std::getline(infile,buf))
{
output.push_back(buf);
}
```
文本编码的实现方法主要封装在GPT2::Preprocessin()函数中,通过输入问题question,进行数据重构,在输入序列中的起始位置处加入起始标志符[CLS],之后拼接问题question的编码信息,从而完成数据预处理过程。
```c++
ErrorCode GPT2::Preprocessing(cuBERT::FullTokenizer tokenizer,
char *question,
std::vector &input_id)
{
// 对问题进行分词操作
int max_seq_length =1000;
std::vector tokens_question;
tokens_question.reserve(max_seq_length);
tokenizer.tokenize(question, &tokens_question, max_seq_length);
// 将文本数据转换为数值型数据
input_id.push_back(tokenizer.convert_token_to_id("[CLS]"));
for (int i=0;i
具体GPT-2模型的推理,如下代码所示。首先,通过gpt2.Inference()函数实现模型的具体推理细节,推理结果保存在outputs中。其次,对每次推理结果进行判断,当判断为[SEP]结束标志符时,结束循环完成推理,否则就将推理结果outputs加入到输入数据input_id中,继续下一次的模型推理。
```c++
// 推理
for(int i=0;i<50;++i)
{
long unsigned int outputs = gpt2.Inference(input_id);
if(outputs == 102) // 当outputs等于102时,即[SEP]结束标志符,退出循环。
{
break;
}
input_id.push_back(outputs);
}
```
在GPT2::Inference()函数具体实现了GPT-2模型的推理过程,主要做如下处理:
1.设置输入shape并执行推理
```c++
long unsigned int GPT2::Inference(const std::vector &input_id)
{
// 保存预处理后的数据
long unsigned int input[1][input_id.size()];
for (int j=0;j> inputShapes;
inputShapes.push_back({1,input_id.size()});
// 输入数据
std::unordered_map inputData;
inputData[inputName]=migraphx::argument{migraphx::shape(inputShape.type(),inputShapes[0]),(long unsigned int*)input};
// 推理
std::vector results = net.eval(inputData);
// 获取输出节点的属性
migraphx::argument result = results[0];
migraphx::shape outputShape = result.get_shape(); // 输出节点的shape
int numberOfOutput=outputShape.elements(); // 输出节点元素的个数
float *data = (float *)result.data(); // 输出节点数据指针
...
}
```
1.执行推理,GPT-2模型的推理结果results是一个std::vector< migraphx::argument >类型,包含一个输出,所以result = results[0]。result中一共包含了input_id.size() * 22557个概率值,其中,input_id.size()代表输入数据的长度,22557代表了词汇表中词的数量。
## 数据后处理
得到模型推理结果后,还需要对数据做如下后处理:
1.排序
2.解码
```c++
long unsigned int GPT2::Inference(const std::vector &input)
{
...
// 保存模型推理出的概率值
long unsigned int n = 0;
std::vector resultsOfPredictions(22557);
for(int i=(input.size()-1)*22557; i
## 预处理
在将文本输入到模型之前,需要做如下预处理:
1.加载词汇表
2.文本编码
首先,根据提供的词汇表路径,通过cuBERT::FullTokenizer()函数加载词汇表,用于后续对输入文本的编码操作。其次,将词汇表中的内容依次保存到vector容器output中,用于数据后处理中的解码操作。
```c++
cuBERT::FullTokenizer tokenizer = cuBERT::FullTokenizer("../Resource/vocab_shici.txt");
std::ifstream infile;
std::string buf;
std::vector output;
infile.open("../Resource/vocab_shici.txt");
while (std::getline(infile,buf))
{
output.push_back(buf);
}
```
文本编码的实现方法主要封装在GPT2::Preprocessin()函数中,通过输入问题question,进行数据重构,在输入序列中的起始位置处加入起始标志符[CLS],之后拼接问题question的编码信息,从而完成数据预处理过程。
```c++
ErrorCode GPT2::Preprocessing(cuBERT::FullTokenizer tokenizer,
char *question,
std::vector &input_id)
{
// 对问题进行分词操作
int max_seq_length =1000;
std::vector tokens_question;
tokens_question.reserve(max_seq_length);
tokenizer.tokenize(question, &tokens_question, max_seq_length);
// 将文本数据转换为数值型数据
input_id.push_back(tokenizer.convert_token_to_id("[CLS]"));
for (int i=0;i
具体GPT-2模型的推理,如下代码所示。首先,通过gpt2.Inference()函数实现模型的具体推理细节,推理结果保存在outputs中。其次,对每次推理结果进行判断,当判断为[SEP]结束标志符时,结束循环完成推理,否则就将推理结果outputs加入到输入数据input_id中,继续下一次的模型推理。
```c++
// 推理
for(int i=0;i<50;++i)
{
long unsigned int outputs = gpt2.Inference(input_id);
if(outputs == 102) // 当outputs等于102时,即[SEP]结束标志符,退出循环。
{
break;
}
input_id.push_back(outputs);
}
```
在GPT2::Inference()函数具体实现了GPT-2模型的推理过程,主要做如下处理:
1.设置输入shape并执行推理
```c++
long unsigned int GPT2::Inference(const std::vector &input_id)
{
// 保存预处理后的数据
long unsigned int input[1][input_id.size()];
for (int j=0;j> inputShapes;
inputShapes.push_back({1,input_id.size()});
// 输入数据
std::unordered_map inputData;
inputData[inputName]=migraphx::argument{migraphx::shape(inputShape.type(),inputShapes[0]),(long unsigned int*)input};
// 推理
std::vector results = net.eval(inputData);
// 获取输出节点的属性
migraphx::argument result = results[0];
migraphx::shape outputShape = result.get_shape(); // 输出节点的shape
int numberOfOutput=outputShape.elements(); // 输出节点元素的个数
float *data = (float *)result.data(); // 输出节点数据指针
...
}
```
1.执行推理,GPT-2模型的推理结果results是一个std::vector< migraphx::argument >类型,包含一个输出,所以result = results[0]。result中一共包含了input_id.size() * 22557个概率值,其中,input_id.size()代表输入数据的长度,22557代表了词汇表中词的数量。
## 数据后处理
得到模型推理结果后,还需要对数据做如下后处理:
1.排序
2.解码
```c++
long unsigned int GPT2::Inference(const std::vector &input)
{
...
// 保存模型推理出的概率值
long unsigned int n = 0;
std::vector resultsOfPredictions(22557);
for(int i=(input.size()-1)*22557; i