# GPT
本示例主要通过使用MIGraphX Python API对GPT2模型进行推理,包括预处理、模型推理以及数据后处理。
## 模型简介
GPT(Generative Pre-trained Transformer)系列模型以不断堆叠的transformer中的decoder模块为特征提取器,提升训练语料的规模和质量、网络的参数量进行迭代更新。GPT-1主要是通过在无标签的数据上学习一个通用的语言模型,再根据特定的任务进行微调处理有监督任务;GPT-2在GPT-1的模型结构上使用更多的模型参数和数据集,训练一个泛化能力更强的词向量模型。GPT-3更是采用海量的模型参数和数据集,训练了一个更加强大的语言模型。
| 模型 | 发布时间 | 参数量 | 预训练数据量 |
| ----- | ------------ | -------- | ------------ |
| GPT-1 | 2018 年 6 月 | 1.17 亿 | 约 5GB |
| GPT-2 | 2019 年 2 月 | 15 亿 | 40GB |
| GPT-3 | 2020 年 5 月 | 1,750 亿 | 45TB |
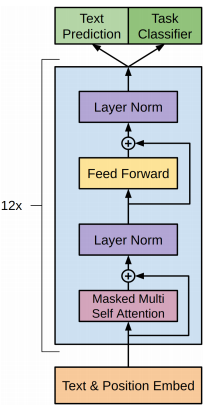
本次采用GPT-2模型进行诗词生成任务,模型文件下载链接:https://pan.baidu.com/s/1KWeoUuakCZ5dualK69qCcw , 提取码:4pmh 。将GPT2_shici.onnx模型文件保存在Resource/文件夹下。整体模型结构如下图所示,也可以通过netron工具:https://netron.app/ 查看GPT-2的模型结构。
 ## 预处理
在将文本输入到模型之前,需要做如下预处理:
1.加载词汇表,根据提供的路径加载词汇表
2.文本编码,根据词汇表对输入的文本进行编码
在数据预处理的过程中,首先加载词汇表,根据提供的词汇表路径,通过transformers库中的BertTokenizerFast函数实现词汇表的加载。完成词汇表的加载后,就可以正常对输入的文本进行编码处理,从而将文本数据转换为数值型数据。
```python
# 加载词汇表
vocab_file = os.path.join('../Resource/', 'vocab_shici.txt')
tokenizer = BertTokenizerFast(vocab_file, sep_token="[SEP]", pad_token="[PAD]", cls_token="[CLS]")
```
完成词汇表的加载后,就可以进行文本编码。首先,输入一段文本数据,通过tokenizer.encoder()将文本数据编码为数值型数据。其次,进行数据重构,创建了一个input_ids列表,开头加入[CLS]起始标志符,并将数值型数据拼接到后面。最后,将input_ids列表中的数据都转换为np.int64类型,并将一维数据扩展了二维数据,完成数据的预处理过程。
```python
# 对输入文本进行编码
text = input("user:")
text_ids = tokenizer.encode(text, add_special_tokens=False)
# 数据重构
input_ids = [tokenizer.cls_token_id]
input_ids.extend(text_ids)
input_ids = np.array(input_ids, dtype=np.int64)
input_ids = np.expand_dims(input_ids, axis=0)
```
## 推理
完成数据预处理后,就可以执行模型推理。推理过程主要做如下处理:
1.设置最大输入shape
2.循环推理
```Python
# 设置最大输入shape
maxInput={"input":[1,1000]}
# 模型推理
for _ in range(max_len):
# 推理
result = model.run({inputName: input_ids})
logits = [float(x) for x in result[0].tolist()]
...
# 当推理得到[SEP]结束标志符,则结束for循环停止生成
if next_token == tokenizer.convert_tokens_to_ids('[SEP]'):
break
# 将推理结果next_token和input_ids进行拼接
next_token = np.array(next_token, dtype=np.int64)
input_ids = np.append(input_ids, next_token)
input_ids = np.expand_dims(input_ids, axis=0)
```
1.设置最大输入shape,因为GPT-2属于生成式模型,输入的shape一直在变化,所以在模型推理前设置一个最大的输入shape,maxInput={"input":[1,1000]},限定模型输入shape的范围。
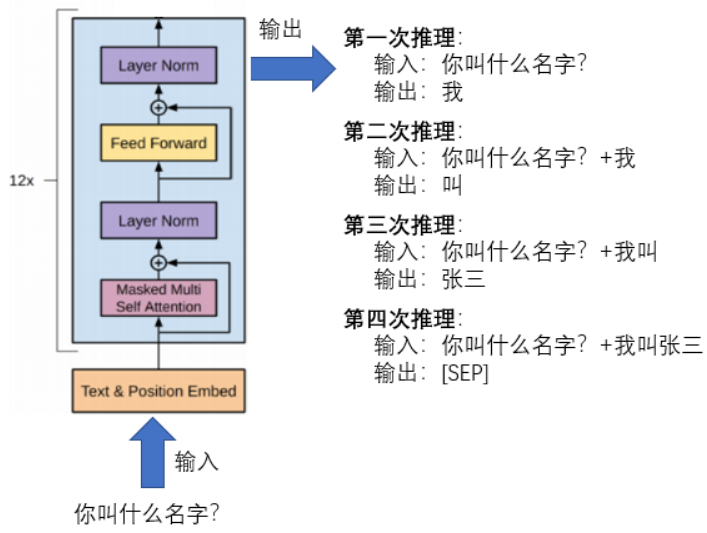
2.循环推理,GPT-2模型不像其他模型一样只需要执行一次推理,而是需要循环执行多次推理才能完成。首先,模型推理限定在for循环中,将输入数据input_ids,输入到model.run({...})中执行推理,生成一个token的id。其次,将推理结果拼接到输入数据input_ids中,执行下一次循环。最后,当循环结束或者生成的词为[SEP]结束标志符时,完成GPT-2模型的整体推理。如下图所示,为GPT-2模型的一次完整推理过程。
## 预处理
在将文本输入到模型之前,需要做如下预处理:
1.加载词汇表,根据提供的路径加载词汇表
2.文本编码,根据词汇表对输入的文本进行编码
在数据预处理的过程中,首先加载词汇表,根据提供的词汇表路径,通过transformers库中的BertTokenizerFast函数实现词汇表的加载。完成词汇表的加载后,就可以正常对输入的文本进行编码处理,从而将文本数据转换为数值型数据。
```python
# 加载词汇表
vocab_file = os.path.join('../Resource/', 'vocab_shici.txt')
tokenizer = BertTokenizerFast(vocab_file, sep_token="[SEP]", pad_token="[PAD]", cls_token="[CLS]")
```
完成词汇表的加载后,就可以进行文本编码。首先,输入一段文本数据,通过tokenizer.encoder()将文本数据编码为数值型数据。其次,进行数据重构,创建了一个input_ids列表,开头加入[CLS]起始标志符,并将数值型数据拼接到后面。最后,将input_ids列表中的数据都转换为np.int64类型,并将一维数据扩展了二维数据,完成数据的预处理过程。
```python
# 对输入文本进行编码
text = input("user:")
text_ids = tokenizer.encode(text, add_special_tokens=False)
# 数据重构
input_ids = [tokenizer.cls_token_id]
input_ids.extend(text_ids)
input_ids = np.array(input_ids, dtype=np.int64)
input_ids = np.expand_dims(input_ids, axis=0)
```
## 推理
完成数据预处理后,就可以执行模型推理。推理过程主要做如下处理:
1.设置最大输入shape
2.循环推理
```Python
# 设置最大输入shape
maxInput={"input":[1,1000]}
# 模型推理
for _ in range(max_len):
# 推理
result = model.run({inputName: input_ids})
logits = [float(x) for x in result[0].tolist()]
...
# 当推理得到[SEP]结束标志符,则结束for循环停止生成
if next_token == tokenizer.convert_tokens_to_ids('[SEP]'):
break
# 将推理结果next_token和input_ids进行拼接
next_token = np.array(next_token, dtype=np.int64)
input_ids = np.append(input_ids, next_token)
input_ids = np.expand_dims(input_ids, axis=0)
```
1.设置最大输入shape,因为GPT-2属于生成式模型,输入的shape一直在变化,所以在模型推理前设置一个最大的输入shape,maxInput={"input":[1,1000]},限定模型输入shape的范围。
2.循环推理,GPT-2模型不像其他模型一样只需要执行一次推理,而是需要循环执行多次推理才能完成。首先,模型推理限定在for循环中,将输入数据input_ids,输入到model.run({...})中执行推理,生成一个token的id。其次,将推理结果拼接到输入数据input_ids中,执行下一次循环。最后,当循环结束或者生成的词为[SEP]结束标志符时,完成GPT-2模型的整体推理。如下图所示,为GPT-2模型的一次完整推理过程。
 ## 数据后处理
获得模型推理结果后,并不能直接作为答案输出,还需要进行数据后处理操作,才能得到最终的结果。具体主要做如下后处理:
1.排序
2.解码
```Python
for _ in range(max_len):
...
# 排序
score = []
for index in range((input_ids.shape[1]-1)*22557, input_ids.shape[1]*22557):
score.append(logits[index])
index_and_score = sorted(enumerate(score), key=lambda x: x[1], reverse=True)
# 取出概率值最大的作为预测结果
next_token = index_and_score[0][0]
...
history.append(next_token)
# 解码
text = tokenizer.convert_ids_to_tokens(history)
print("chatbot:" + "".join(text))
```
1.排序,每次推理都会对每个token生成词汇表中下一个词的概率,例如输入shape为(1,4),词汇表长度为22557,则一共生成4*22557个概率,但是不需要获得全部的概率,只需要得到最后一个token生成的概率。得到相应的概率后,采用sorted()函数进行排序操作,取概率值最大的作为预测结果。
2.解码,因为history列表中存放的推理结果都是对应token的id,还需要进行解码将对应的id转换文本。解码主要采用BertTokenizerFast中的convert_ids_to_tokens()函数将数值型数据转换为相应的文本数据,从而得到对应的答案。
## 数据后处理
获得模型推理结果后,并不能直接作为答案输出,还需要进行数据后处理操作,才能得到最终的结果。具体主要做如下后处理:
1.排序
2.解码
```Python
for _ in range(max_len):
...
# 排序
score = []
for index in range((input_ids.shape[1]-1)*22557, input_ids.shape[1]*22557):
score.append(logits[index])
index_and_score = sorted(enumerate(score), key=lambda x: x[1], reverse=True)
# 取出概率值最大的作为预测结果
next_token = index_and_score[0][0]
...
history.append(next_token)
# 解码
text = tokenizer.convert_ids_to_tokens(history)
print("chatbot:" + "".join(text))
```
1.排序,每次推理都会对每个token生成词汇表中下一个词的概率,例如输入shape为(1,4),词汇表长度为22557,则一共生成4*22557个概率,但是不需要获得全部的概率,只需要得到最后一个token生成的概率。得到相应的概率后,采用sorted()函数进行排序操作,取概率值最大的作为预测结果。
2.解码,因为history列表中存放的推理结果都是对应token的id,还需要进行解码将对应的id转换文本。解码主要采用BertTokenizerFast中的convert_ids_to_tokens()函数将数值型数据转换为相应的文本数据,从而得到对应的答案。