# GLM-130B
## 论文
`GLM: General Language Model Pretraining with Autoregressive Blank Infilling`
- [https://arxiv.org/abs/2103.10360](https://arxiv.org/abs/2103.10360)
## 模型结构
GLM-130B是一个开放的双语(中英)双向密集模型,具有130亿个参数,使用[通用语言模型(GLM)](https://aclanthology.org/2022.acl-long.26)算法进行预训练。GLM是一种基于Transformer的语言模型,以自回归空白填充为训练目标。
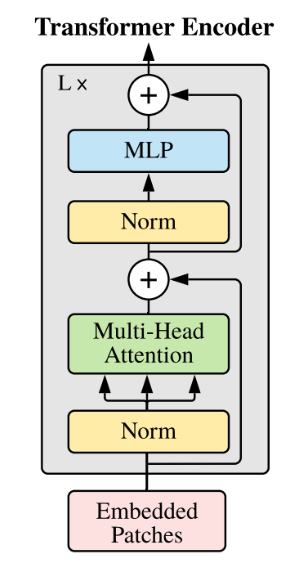
以下是GLM130B的主要网络参数配置:
| 模型名称 | 隐含层维度 | 层数 | 头数 | 词表大小 | 位置编码 | 最大序列长度 |
| -------- | ---------- | ---- | ---- | -------- | -------- | ------------ |
| GLM130B | 12288 | 70 | 96 | 150528 | RoPE | 2048 |
## 算法原理
GLM是一种基于Transformer的语言模型,以自回归空白填充为训练目标, 同时具备自回归和自编码能力。
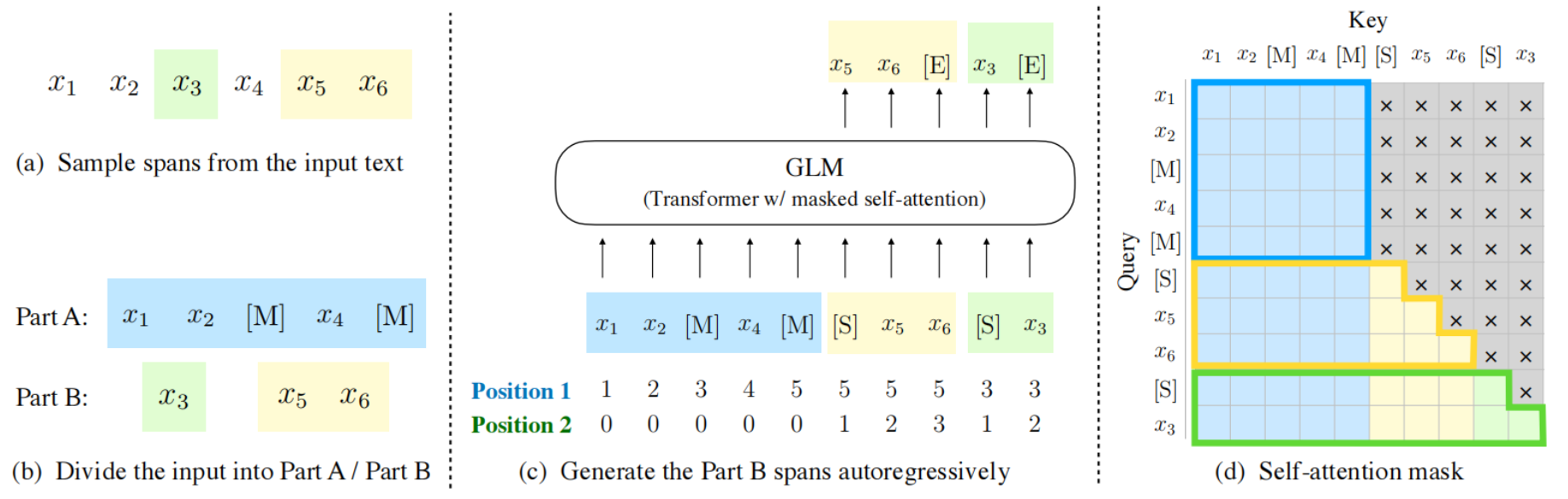
本项目主要针对GLM-130B模型在8卡32G显存的DCU平台利用fastertransformer进行快速推理。
## 环境配置
### 环境准备
在光源可拉取推理的docker镜像,拉取方式如下:
```
docker pull image.sourcefind.cn:5000/dcu/admin/base/custom:glm-ft-v1.1
```
### 容器启动
模型推理容器启动命令参考如下,用户根据需要修改:
```
# 自定义容器名
# 当前工程所在路径
docker run -it --name= -v :/work -w /work --device=/dev/kfd --device=/dev/dri --security-opt seccomp=unconfined --cap-add=SYS_PTRACE --shm-size=16G --group-add 39 image.sourcefind.cn:5000/dcu/admin/base/custom:glm-ft-v1.1 /bin/bash
```
### 编译方法
```
mkdir build
cd build
cmake -DSM=62 -DCMAKE_BUILD_TYPE=Release -DBUILD_MULTI_GPU=ON -DCMAKE_CXX_COMPILER=nvcc ..
make
#编译到100%时如果“Linking CUDA executable ../../bin/test_logprob_kernels”报错则执行如下命令
cd tests/unittests
nvcc CMakeFiles/test_logprob_kernels.dir/test_logprob_kernels.cu.o -o ../../bin/test_logprob_kernels -L/usr/local/mpi/lib -Wl,-rpath,/usr/local/mpi/lib -lcublas -lcublasLt -lcudart ../../lib/liblogprob_kernels.a ../../lib/libmemory_utils.a -L"/opt/dtk-23.04/cuda/targets/x86_64-linux/lib/stubs" -L"/opt/dtk-23.04/cuda/targets/x86_64-linux/lib" -lcudart -lrt -lpthread -ldl
```
## 数据集
无
## 推理
### 原版模型下载与转换
从[这里](https://docs.google.com/forms/d/e/1FAIpQLSehr5Dh_i3TwACmFFi8QEgIVNYGmSPwV0GueIcsUev0NEfUug/viewform?usp=sf_link)下载GLM-130B的模型,确保所有60个块都已完全下载,然后使用以下命令将它们合并到单个存档文件中并解压缩它:
```
cat glm-130b-sat.tar.part_* > glm-130b-sat.tar
tar xvf glm-130b-sat.tar
```
模型转换
```
cd /work/build
python ../examples/cpp/glm/glm_weight_convt.py -i /home/glm-130b-sat/49300/ -o /home/glm-130b-sat-ft-model/
```
### 运行示例程序
生成gemm_config.in文件
```
# ./bin/gpt_gemm
./bin/gpt_gemm 1 1 128 96 128 49152 150528 1 8
```
修改../examples/cpp/glm/glm_config.ini配置文件
执行glm_example执行命令
```
mpirun -n 8 --allow-run-as-root ./bin/glm_example
```
此example程序会读取../examples/cpp/glm/start_ids.csv文件中的id作为输入token,生成的结果tokenid会保存在./out内,可以执行如下命令进行解析out结果:
```
python ../examples/pytorch/glm/glm_tokenize.py
```
## Result
## 精度
无
## 应用场景
### 算法类别
`对话问答`
### 热点应用行业
`医疗,科研,金融,教育`
## 源码仓库及问题反馈
https://developer.sourcefind.cn/codes/modelzoo/glm130b_fastertransformer
## 参考资料
[THUDM/GLM-130B: GLM-130B: An Open Bilingual Pre-Trained Model (ICLR 2023) (github.com)](https://github.com/THUDM/GLM-130B)
[THUDM/FasterTransformer: Transformer related optimization, including BERT, GPT (github.com)](https://github.com/THUDM/FasterTransformer)
