# GLM-4V
**GLM-4V-9B** 具备 1120 * 1120 高分辨率下的中英双语多轮对话能力,在中英文综合能力、感知推理、文字识别、图表理解等多方面多模态评测中,GLM-4V-9B 表现出超越 GPT-4-turbo-2024-04-09、Gemini 1.0 Pro、Qwen-VL-Max 和 Claude 3 Opus 的卓越性能。
## 论文
- [GLM: General Language Model Pretraining with Autoregressive Blank Infilling](https://arxiv.org/abs/2103.10360)
## 模型结构
GLM-4-9B 是智谱 AI 推出的最新一代预训练模型 GLM-4 系列中的开源版本。
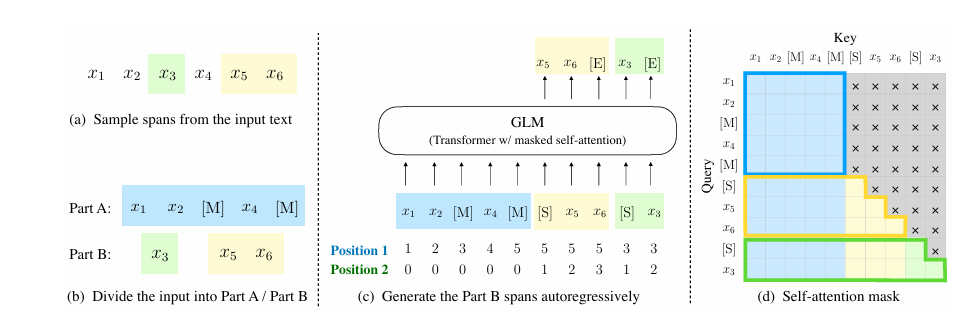
## 算法原理
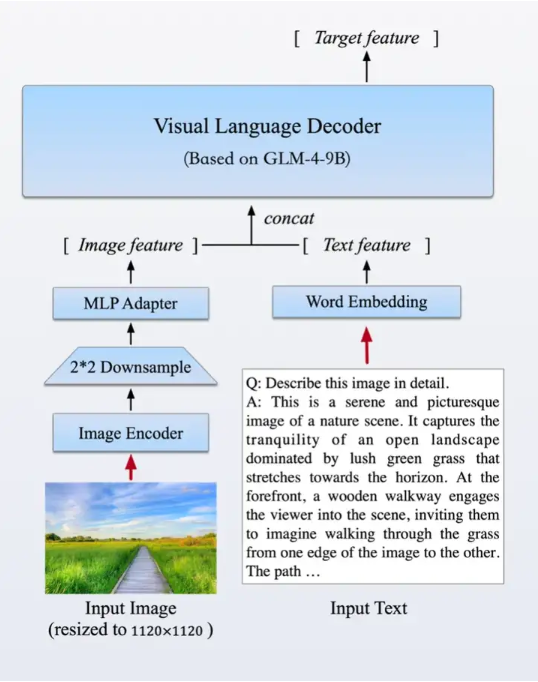
在强化文本能力的同时,我们首次推出了基于GLM基座的开源多模态模型GLM-4V-9B。这一模型采用了与CogVLM2相似的架构设计,能够处理高达1120 x 1120分辨率的输入,并通过降采样技术有效减少了token的开销。为了减小部署与计算开销,GLM-4V-9B没有引入额外的视觉专家模块,采用了直接混合文本和图片数据的方式进行训练,在保持文本性能的同时提升多模态能力。
## 环境配置
### Docker(方法一)
[光源](https://www.sourcefind.cn/#/service-details)拉取docker镜像的地址与使用步骤
```
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.1.0-ubuntu22.04-dtk23.10.1-py310
docker run -it -v /path/your_code_data/:/path/your_code_data/ -v /opt/hyhal/:/opt/hyhal/:ro --shm-size=64G --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name glm-4v bash
cd /path/your_code_data/
pip install -r requirements.txt -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
```
### Dockerfile(方法二)
```
cd /path/your_code_data/docker
docker build --no-cache -t glm-4v:latest .
docker run --shm-size=64G --name glm-4v -v /opt/hyhal:/opt/hyhal:ro --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video -v /path/your_code_data/:/path/your_code_data/ -it glm-4v bash
```
### Anaconda(方法三)
关于本项目DCU显卡所需的特殊深度学习库可从[光合](https://developer.hpccube.com/tool/)开发者社区下载安装。
```
DTK驱动:dtk23.10
python:python3.10
torch:2.1
torchvision: 0.16.0
```
`Tips:以上dtk驱动、python、paddle等DCU相关工具版本需要严格一一对应`
关于本项目DCU显卡所需的特殊深度学习库可从[光合](https://developer.hpccube.com/tool/)开发者社区下载安装。
```
conda create -n glm-4v python=3.10
conda activate glm-4v
cd /path/your_code_data/
pip install -r requirements.txt -i http://mirrors.aliyun.com/pypi/simple
```
## 数据集
迷你数据集 [coco测试数据集](./data/train.json)
[coco图像描述完整数据集](https://modelscope.cn/datasets/modelscope/coco_2014_caption/summary?spm=a2c6h.12873639.article-detail.17.70117774diTYiv)
本仓库提供测试数据集用于微调代码测试,需要可自行下载。预训练需要准备你的训练数据,需要将所有样本放到一个列表中并存入json文件中。自定义数据集支持json和jsonl样式。glm-4v-9b支持多轮对话,但总的对话轮次中需包含一张图片,支持传入本地路径或URL。以下是自定义数据集的示例:。用于正常训练的完整数据集请按此目录结构进行制备:
```
{"query": "55555", "response": "66666", "images": ["image_path"]}
{"query": "eeeee", "response": "fffff", "history": [], "images": ["image_path"]}
{"query": "EEEEE", "response": "FFFFF", "history": [["AAAAA", "BBBBB"], ["CCCCC", "DDDDD"]], "images": ["image_path"]}
```
## 训练
微调需要安装swift,具体操作如下:
```
cd swift-main
pip install -e .
```
训练需在对应的训练脚本中修改以下参数,其他参数可自行修改:
```
--model_id_or_path # or 修改为本地模型地址
--dataset # 训练集文件夹
--output_dir # 训练输出文件夹
```
### 单卡训练
```
sh lora_finetune_single.sh
```
### 多卡训练
```
sh lora_finetune_multi.sh
```
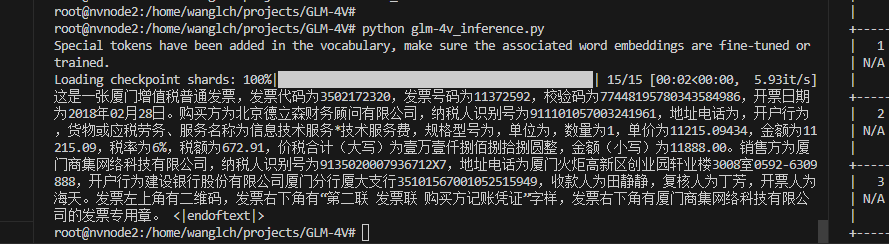
## 推理
若要执行推理需要将本仓库修改后的[visual.py](visual.py)替换模型文件中的**visual.py**文件。
### 单机单卡
`tokenizer = AutoTokenizer.from_pretrained("/home/wanglch/projects/GLM-4V/glm-4v-9b", trust_remote_code=True)`
`model = AutoModelForCausalLM.from_pretrained(
"/home/wanglch/projects/GLM-4V/glm-4v-9b",
torch_dtype=torch.float16,
low_cpu_mem_usage=True,
trust_remote_code=True
).to(device).eval()`
```
python glm-4v_inference.py
```
## result
### OCR
### 精度
测试数据: [迷你coco图像描述数据集](./data/train.json) ,使用的加速卡:A800/K100。
| device | train_loss | eval_loss |eval_loss |
| :------: | :------: | :------: | :------: |
| A800*2 | 2.493 | 4.25 | 0.302 |
| K100*2 | 2.495 | 4.25 | 0.295 |
## 应用场景
### 算法类别
`ocr`
### 热点应用行业
`金融,教育,政府,科研,制造,能源,交通`
## 预训练权重
- [THUDM/glm-4v-9b](https://huggingface.co/THUDM/glm-4v-9b)
- [ZhipuAI/glm-4v-9b](https://modelscope.cn/models/ZhipuAI/glm-4-9b-chat-1m)
## 源码仓库及问题反馈
- http://developer.hpccube.com/codes/modelzoo/glm-4v-9b_pytorch.git
## 参考资料
- [GLM: General Language Model Pretraining with Autoregressive Blank Infilling](https://arxiv.org/abs/2103.10360)
- [GLM4v github](https://github.com/THUDM/GLM-4)
- [swift github](https://github.com/modelscope/swift/blob/main/docs/source/Multi-Modal/glm4v%E6%9C%80%E4%BD%B3%E5%AE%9E%E8%B7%B5.md)