# MiniCPM-V Best Practice
Using minicpm-v-3b-chat as an example, if you want to use the updated version of the MiniCPM-V multimodal model (v2), you can switch `--model_type minicpm-v-3b-chat` to `--model_type minicpm-v-v2-chat`.
## Table of Contents
- [Environment Setup](#environment-setup)
- [Inference](#inference)
- [Fine-tuning](#fine-tuning)
- [Inference After Fine-tuning](#inference-after-fine-tuning)
## Environment Setup
```shell
pip install 'ms-swift[llm]' -U
```
Model Link:
- minicpm-v-3b-chat: [https://modelscope.cn/models/OpenBMB/MiniCPM-V/summary](https://modelscope.cn/models/OpenBMB/MiniCPM-V/summary)
- minicpm-v-v2-chat: [https://modelscope.cn/models/OpenBMB/MiniCPM-V-2/summary](https://modelscope.cn/models/OpenBMB/MiniCPM-V-2/summary)
## Inference
Inference for [minicpm-v-3b-chat](https://modelscope.cn/models/OpenBMB/MiniCPM-V/summary):
```shell
# Experimental environment: A10, 3090, V100, ...
# 10GB GPU memory
CUDA_VISIBLE_DEVICES=0 swift infer --model_type minicpm-v-3b-chat
```
Output: (supports local path or URL input)
```python
"""
<<< Describe this image
Input a media path or URL <<< http://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/cat.png
This image depicts a black and white cat sitting on the floor. The cat looks small, possibly a kitten. Its eyes are wide open, seeming to be observing the surroundings.
--------------------------------------------------
<<< clear
<<< How many sheep are in the image?
Input a media path or URL <<< http://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/animal.png
There are four sheep in the image.
--------------------------------------------------
<<< clear
<<< What is the calculation result?
Input a media path or URL <<< http://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/math.png
The calculation result is 1452 + 4530 = 5982.
--------------------------------------------------
<<< clear
<<< Write a poem based on the image content
Input a media path or URL <<< http://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/poem.png
On the tranquil lake surface, a small boat slowly sails by.
"""
```
Sample images:
cat:
 animal:
animal:
 math:
math:
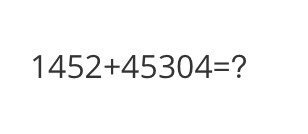 poem:
poem:
 **Single Sample Inference**
```python
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
from swift.llm import (
get_model_tokenizer, get_template, inference, ModelType,
get_default_template_type, inference_stream
)
from swift.utils import seed_everything
import torch
model_type = ModelType.minicpm_v_3b_chat
template_type = get_default_template_type(model_type)
print(f'template_type: {template_type}')
model, tokenizer = get_model_tokenizer(model_type, torch.float16,
model_kwargs={'device_map': 'auto'})
model.generation_config.max_new_tokens = 256
template = get_template(template_type, tokenizer)
seed_everything(42)
images = ['http://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/road.png']
query = 'How far is it from each city?'
response, history = inference(model, template, query, images=images)
print(f'query: {query}')
print(f'response: {response}')
# Streaming
query = 'Which is the farthest city?'
gen = inference_stream(model, template, query, history, images=images)
print_idx = 0
print(f'query: {query}\nresponse: ', end='')
for response, history in gen:
delta = response[print_idx:]
print(delta, end='', flush=True)
print_idx = len(response)
print()
print(f'history: {history}')
"""
query: How far is it from each city?
response: The distance from Guangzhou to Shenzhen is 293 kilometers, while the distance from Shenzhen to Guangzhou is 14 kilometers.
query: Which is the farthest city?
response: The farthest city is Shenzhen. It is located between Guangzhou and Shenzhen, 293 kilometers away from Guangzhou and 14 kilometers away from Shenzhen.
history: [['How far is it from each city?', ' The distance from Guangzhou to Shenzhen is 293 kilometers, while the distance from Shenzhen to Guangzhou is 14 kilometers.'], ['Which is the farthest city?', ' The farthest city is Shenzhen. It is located between Guangzhou and Shenzhen, 293 kilometers away from Guangzhou and 14 kilometers away from Shenzhen.']]
"""
```
Sample image:
road:
**Single Sample Inference**
```python
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
from swift.llm import (
get_model_tokenizer, get_template, inference, ModelType,
get_default_template_type, inference_stream
)
from swift.utils import seed_everything
import torch
model_type = ModelType.minicpm_v_3b_chat
template_type = get_default_template_type(model_type)
print(f'template_type: {template_type}')
model, tokenizer = get_model_tokenizer(model_type, torch.float16,
model_kwargs={'device_map': 'auto'})
model.generation_config.max_new_tokens = 256
template = get_template(template_type, tokenizer)
seed_everything(42)
images = ['http://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/road.png']
query = 'How far is it from each city?'
response, history = inference(model, template, query, images=images)
print(f'query: {query}')
print(f'response: {response}')
# Streaming
query = 'Which is the farthest city?'
gen = inference_stream(model, template, query, history, images=images)
print_idx = 0
print(f'query: {query}\nresponse: ', end='')
for response, history in gen:
delta = response[print_idx:]
print(delta, end='', flush=True)
print_idx = len(response)
print()
print(f'history: {history}')
"""
query: How far is it from each city?
response: The distance from Guangzhou to Shenzhen is 293 kilometers, while the distance from Shenzhen to Guangzhou is 14 kilometers.
query: Which is the farthest city?
response: The farthest city is Shenzhen. It is located between Guangzhou and Shenzhen, 293 kilometers away from Guangzhou and 14 kilometers away from Shenzhen.
history: [['How far is it from each city?', ' The distance from Guangzhou to Shenzhen is 293 kilometers, while the distance from Shenzhen to Guangzhou is 14 kilometers.'], ['Which is the farthest city?', ' The farthest city is Shenzhen. It is located between Guangzhou and Shenzhen, 293 kilometers away from Guangzhou and 14 kilometers away from Shenzhen.']]
"""
```
Sample image:
road:
 ## Fine-tuning
Fine-tuning multimodal large models usually uses **custom datasets**. Here is a demo that can be run directly:
(By default, only the qkv part of LLM is fine-tuned using LoRA. If you want to fine-tune all linear parts including the vision model, you can specify `--lora_target_modules ALL`. Full parameter fine-tuning is also supported.)
```shell
# Experimental environment: A10, 3090, V100, ...
# 10GB GPU memory
CUDA_VISIBLE_DEVICES=0 swift sft \
--model_type minicpm-v-3b-chat \
--dataset coco-en-2-mini \
```
[Custom datasets](../LLM/Customization.md#-Recommended-Command-line-arguments) support json and jsonl formats. Here is an example of a custom dataset:
(Supports multi-turn conversations, but the total round of conversations can only contain one image. Supports local path or URL input.)
```jsonl
{"query": "55555", "response": "66666", "images": ["image_path"]}
{"query": "eeeee", "response": "fffff", "history": [], "images": ["image_path"]}
{"query": "EEEEE", "response": "FFFFF", "history": [["AAAAA", "BBBBB"], ["CCCCC", "DDDDD"]], "images": ["image_path"]}
```
## Inference After Fine-tuning
Direct inference:
```shell
CUDA_VISIBLE_DEVICES=0 swift infer \
--ckpt_dir output/minicpm-v-3b-chat/vx-xxx/checkpoint-xxx \
--load_dataset_config true \
```
**merge-lora** and inference:
```shell
CUDA_VISIBLE_DEVICES=0 swift export \
--ckpt_dir output/minicpm-v-3b-chat/vx-xxx/checkpoint-xxx \
--merge_lora true
CUDA_VISIBLE_DEVICES=0 swift infer \
--ckpt_dir output/minicpm-v-3b-chat/vx-xxx/checkpoint-xxx-merged \
--load_dataset_config true
```
## Fine-tuning
Fine-tuning multimodal large models usually uses **custom datasets**. Here is a demo that can be run directly:
(By default, only the qkv part of LLM is fine-tuned using LoRA. If you want to fine-tune all linear parts including the vision model, you can specify `--lora_target_modules ALL`. Full parameter fine-tuning is also supported.)
```shell
# Experimental environment: A10, 3090, V100, ...
# 10GB GPU memory
CUDA_VISIBLE_DEVICES=0 swift sft \
--model_type minicpm-v-3b-chat \
--dataset coco-en-2-mini \
```
[Custom datasets](../LLM/Customization.md#-Recommended-Command-line-arguments) support json and jsonl formats. Here is an example of a custom dataset:
(Supports multi-turn conversations, but the total round of conversations can only contain one image. Supports local path or URL input.)
```jsonl
{"query": "55555", "response": "66666", "images": ["image_path"]}
{"query": "eeeee", "response": "fffff", "history": [], "images": ["image_path"]}
{"query": "EEEEE", "response": "FFFFF", "history": [["AAAAA", "BBBBB"], ["CCCCC", "DDDDD"]], "images": ["image_path"]}
```
## Inference After Fine-tuning
Direct inference:
```shell
CUDA_VISIBLE_DEVICES=0 swift infer \
--ckpt_dir output/minicpm-v-3b-chat/vx-xxx/checkpoint-xxx \
--load_dataset_config true \
```
**merge-lora** and inference:
```shell
CUDA_VISIBLE_DEVICES=0 swift export \
--ckpt_dir output/minicpm-v-3b-chat/vx-xxx/checkpoint-xxx \
--merge_lora true
CUDA_VISIBLE_DEVICES=0 swift infer \
--ckpt_dir output/minicpm-v-3b-chat/vx-xxx/checkpoint-xxx-merged \
--load_dataset_config true
```