# Llava Best Practice
The document corresponds to the following models
| model | model_type |
|-------|------------|
| [llava-v1.6-mistral-7b](https://modelscope.cn/models/AI-ModelScope/llava-v1.6-mistral-7b/summary) | llava1_6-mistral-7b-instruct |
| [llava-v1.6-34b](https://www.modelscope.cn/models/AI-ModelScope/llava-v1.6-34b/summary) | llava1_6-yi-34b-instruct |
|[llama3-llava-next-8b](https://modelscope.cn/models/AI-ModelScope/llama3-llava-next-8b/summary)|llama3-llava-next-8b|
|[llava-next-72b](https://modelscope.cn/models/AI-ModelScope/llava-next-72b/summary)|llava-next-72b|
|[llava-next-110b](https://modelscope.cn/models/AI-ModelScope/llava-next-110b/summary)|llava-next-110b|
The following practices take `llava-v1.6-mistral-7b` as an example. You can also switch to other models by specifying the `--model_type`.
## Table of Contents
- [Environment Setup](#environment-setup)
- [Inference](#inference)
- [Fine-tuning](#fine-tuning)
- [Inference after Fine-tuning](#inference-after-fine-tuning)
## Environment Setup
```shell
git clone https://github.com/modelscope/swift.git
cd swift
pip install -e '.[llm]'
```
## Inference
```shell
# Experimental environment: A100
# 20GB GPU memory
CUDA_VISIBLE_DEVICES=0 swift infer --model_type llava1_6-mistral-7b-instruct
# 70GB GPU memory
CUDA_VISIBLE_DEVICES=0 swift infer --model_type llava1_6-yi-34b-instruct
# 4*20GB GPU memory
CUDA_VISIBLE_DEVICES=0,1,2,3 swift infer --model_type llava1_6-yi-34b-instruct
```
Output: (supports passing in local path or URL)
```python
"""
<<< Describe this image.
Input a media path or URL <<< http://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/cat.png
The image shows a close-up of a kitten with a soft, blurred background that suggests a natural, outdoor setting. The kitten has a mix of white and gray fur with darker stripes, typical of a tabby pattern. Its eyes are wide open, with a striking blue color that contrasts with the kitten's fur. The kitten's nose is small and pink, and its whiskers are long and white, adding to the kitten's cute and innocent appearance. The lighting in the image is soft and diffused, creating a gentle and warm atmosphere. The focus is sharp on the kitten's face, while the rest of the image is slightly out of focus, which draws attention to the kitten's features.
--------------------------------------------------
<<< How many sheep are in the picture?
Input a media path or URL <<< http://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/animal.png
There are four sheep in the picture.
--------------------------------------------------
<<< What is the calculation result?
Input a media path or URL <<< http://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/math.png
The calculation result is 14352 + 45304 = 145304.
--------------------------------------------------
<<< Write a poem based on the content of the picture.
Input a media path or URL <<< http://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/poem.png
In the quiet of the night,
A solitary boat takes flight,
Across the water's gentle swell,
Underneath the stars that softly fell.
The boat, a vessel of the night,
Carries but one, a lone delight,
A solitary figure, lost in thought,
In the tranquil calm, they find a wraith.
The stars above, like diamonds bright,
Reflect upon the water's surface light,
Creating a path for the boat's journey,
Guiding through the night with a gentle purity.
The boat, a silent sentinel,
In the stillness, it gently swells,
A vessel of peace and calm,
In the quiet of the night, it carries on.
The figure on board, a soul at ease,
In the serene embrace of nature's peace,
They sail through the night,
Under the watchful eyes of the stars' light.
The boat, a symbol of solitude,
In the vast expanse of the universe's beauty,
A lone journey, a solitary quest,
In the quiet of the night, it finds its rest.
"""
```
Example images are as follows:
cat:
 animal:
animal:
 math:
math:
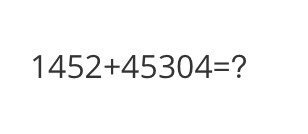 poem:
poem:
 **Single Sample Inference**
```python
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
from swift.llm import (
get_model_tokenizer, get_template, inference, ModelType,
get_default_template_type, inference_stream
)
from swift.utils import seed_everything
import torch
model_type = 'llava1_6-mistral-7b-instruct'
template_type = get_default_template_type(model_type)
print(f'template_type: {template_type}')
model, tokenizer = get_model_tokenizer(model_type, torch.float16,
model_kwargs={'device_map': 'auto'})
model.generation_config.max_new_tokens = 256
template = get_template(template_type, tokenizer)
seed_everything(42)
images = ['http://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/road.png']
query = 'How far is it from each city?'
response, _ = inference(model, template, query, images=images)
print(f'query: {query}')
print(f'response: {response}')
# Streaming
query = 'Which city is the farthest?'
gen = inference_stream(model, template, query, images=images)
print_idx = 0
print(f'query: {query}\nresponse: ', end='')
for response, _ in gen:
delta = response[print_idx:]
print(delta, end='', flush=True)
print_idx = len(response)
print()
"""
query: How far is it from each city?
response: The image shows a road sign indicating the distances to three cities: Mata, Yangjiang, and Guangzhou. The distances are given in kilometers.
- Mata is 14 kilometers away.
- Yangjiang is 62 kilometers away.
- Guangzhou is 293 kilometers away.
Please note that these distances are as the crow flies and do not take into account the actual driving distance due to road conditions, traffic, or other factors.
query: Which city is the farthest?
response: The farthest city listed on the sign is Mata, which is 14 kilometers away.
"""
```
Example image is as follows:
road:
**Single Sample Inference**
```python
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
from swift.llm import (
get_model_tokenizer, get_template, inference, ModelType,
get_default_template_type, inference_stream
)
from swift.utils import seed_everything
import torch
model_type = 'llava1_6-mistral-7b-instruct'
template_type = get_default_template_type(model_type)
print(f'template_type: {template_type}')
model, tokenizer = get_model_tokenizer(model_type, torch.float16,
model_kwargs={'device_map': 'auto'})
model.generation_config.max_new_tokens = 256
template = get_template(template_type, tokenizer)
seed_everything(42)
images = ['http://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/road.png']
query = 'How far is it from each city?'
response, _ = inference(model, template, query, images=images)
print(f'query: {query}')
print(f'response: {response}')
# Streaming
query = 'Which city is the farthest?'
gen = inference_stream(model, template, query, images=images)
print_idx = 0
print(f'query: {query}\nresponse: ', end='')
for response, _ in gen:
delta = response[print_idx:]
print(delta, end='', flush=True)
print_idx = len(response)
print()
"""
query: How far is it from each city?
response: The image shows a road sign indicating the distances to three cities: Mata, Yangjiang, and Guangzhou. The distances are given in kilometers.
- Mata is 14 kilometers away.
- Yangjiang is 62 kilometers away.
- Guangzhou is 293 kilometers away.
Please note that these distances are as the crow flies and do not take into account the actual driving distance due to road conditions, traffic, or other factors.
query: Which city is the farthest?
response: The farthest city listed on the sign is Mata, which is 14 kilometers away.
"""
```
Example image is as follows:
road:
 ## Fine-tuning
Multimodal large model fine-tuning usually uses **custom datasets** for fine-tuning. Here is a demo that can be run directly:
LoRA fine-tuning:
(By default, only the qkv of the LLM part is fine-tuned using LoRA. If you want to fine-tune all linear layers including the vision model part, you can specify `--lora_target_modules ALL`.)
```shell
# Experimental environment: A10, 3090, V100...
# 21GB GPU memory
CUDA_VISIBLE_DEVICES=0 swift sft \
--model_type llava1_6-mistral-7b-instruct \
--dataset coco-en-2-mini \
# 2*45GB GPU memory
CUDA_VISIBLE_DEVICES=0,1 swift sft \
--model_type llava1_6-yi-34b-instruct \
--dataset coco-en-2-mini \
```
Full parameter fine-tuning:
```shell
# Experimental environment: 4 * A100
# 4 * 70 GPU memory
NPROC_PER_NODE=4 CUDA_VISIBLE_DEVICES=0,1,2,3 swift sft \
--model_type llava1_6-mistral-7b-instruct \
--dataset coco-en-2-mini \
--sft_type full \
--deepspeed default-zero2
# 8 * 50 GPU memory
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 swift sft \
--model_type llava1_6-yi-34b-instruct \
--dataset coco-en-2-mini \
--sft_type full \
```
[Custom datasets](../LLM/Customization.md#-Recommended-Command-line-arguments) support json, jsonl formats. Here is an example of a custom dataset:
(Only single-turn dialogue is supported. Each turn of dialogue must contain one image. Local paths or URLs can be passed in.)
```jsonl
{"query": "55555", "response": "66666", "images": ["image_path"]}
{"query": "eeeee", "response": "fffff", "images": ["image_path"]}
{"query": "EEEEE", "response": "FFFFF", "images": ["image_path"]}
```
## Inference after Fine-tuning
Direct inference:
```shell
model_type="llava1_6-mistral-7b-instruct"
CUDA_VISIBLE_DEVICES=0 swift infer \
--ckpt_dir output/${model_type}/vx-xxx/checkpoint-xxx \
--load_dataset_config true
```
**merge-lora** and inference:
```shell
model_type="llava1_6-mistral-7b-instruct"
CUDA_VISIBLE_DEVICES=0 swift export \
--ckpt_dir "output/${model_type}/vx-xxx/checkpoint-xxx" \
--merge_lora true
CUDA_VISIBLE_DEVICES=0 swift infer \
--ckpt_dir "output/${model_type}/vx-xxx/checkpoint-xxx-merged" \
--load_dataset_config true
```
## Fine-tuning
Multimodal large model fine-tuning usually uses **custom datasets** for fine-tuning. Here is a demo that can be run directly:
LoRA fine-tuning:
(By default, only the qkv of the LLM part is fine-tuned using LoRA. If you want to fine-tune all linear layers including the vision model part, you can specify `--lora_target_modules ALL`.)
```shell
# Experimental environment: A10, 3090, V100...
# 21GB GPU memory
CUDA_VISIBLE_DEVICES=0 swift sft \
--model_type llava1_6-mistral-7b-instruct \
--dataset coco-en-2-mini \
# 2*45GB GPU memory
CUDA_VISIBLE_DEVICES=0,1 swift sft \
--model_type llava1_6-yi-34b-instruct \
--dataset coco-en-2-mini \
```
Full parameter fine-tuning:
```shell
# Experimental environment: 4 * A100
# 4 * 70 GPU memory
NPROC_PER_NODE=4 CUDA_VISIBLE_DEVICES=0,1,2,3 swift sft \
--model_type llava1_6-mistral-7b-instruct \
--dataset coco-en-2-mini \
--sft_type full \
--deepspeed default-zero2
# 8 * 50 GPU memory
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 swift sft \
--model_type llava1_6-yi-34b-instruct \
--dataset coco-en-2-mini \
--sft_type full \
```
[Custom datasets](../LLM/Customization.md#-Recommended-Command-line-arguments) support json, jsonl formats. Here is an example of a custom dataset:
(Only single-turn dialogue is supported. Each turn of dialogue must contain one image. Local paths or URLs can be passed in.)
```jsonl
{"query": "55555", "response": "66666", "images": ["image_path"]}
{"query": "eeeee", "response": "fffff", "images": ["image_path"]}
{"query": "EEEEE", "response": "FFFFF", "images": ["image_path"]}
```
## Inference after Fine-tuning
Direct inference:
```shell
model_type="llava1_6-mistral-7b-instruct"
CUDA_VISIBLE_DEVICES=0 swift infer \
--ckpt_dir output/${model_type}/vx-xxx/checkpoint-xxx \
--load_dataset_config true
```
**merge-lora** and inference:
```shell
model_type="llava1_6-mistral-7b-instruct"
CUDA_VISIBLE_DEVICES=0 swift export \
--ckpt_dir "output/${model_type}/vx-xxx/checkpoint-xxx" \
--merge_lora true
CUDA_VISIBLE_DEVICES=0 swift infer \
--ckpt_dir "output/${model_type}/vx-xxx/checkpoint-xxx-merged" \
--load_dataset_config true
```