# CogVLM Best Practice
## Table of Contents
- [Environment Setup](#environment-setup)
- [Inference](#inference)
- [Fine-tuning](#fine-tuning)
- [Inference After Fine-tuning](#inference-after-fine-tuning)
## Environment Setup
```shell
git clone https://github.com/modelscope/swift.git
cd swift
pip install -e '.[llm]'
```
## Inference
Inference with [cogvlm-17b-chat](https://modelscope.cn/models/ZhipuAI/cogvlm-chat/summary):
```shell
# Experimental environment: A100
# 38GB GPU memory
CUDA_VISIBLE_DEVICES=0 swift infer --model_type cogvlm-17b-chat
```
Output: (supports passing local path or URL)
```python
"""
<<< Describe this image.
Input a media path or URL <<< http://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/cat.png
This image showcases a close-up of a young kitten. The kitten has a fluffy coat with a mix of white, gray, and brown colors. Its eyes are strikingly blue, and it appears to be gazing directly at the viewer. The background is blurred, emphasizing the kitten as the main subject.
--------------------------------------------------
<<< clear
<<< How many sheep are in the picture?
Input a media path or URL <<< http://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/animal.png
There are four sheep in the picture.
--------------------------------------------------
<<< clear
<<< What is the calculation result?
Input a media path or URL <<< http://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/math.png
The calculation result is '1452+45304=45456'.
--------------------------------------------------
<<< clear
<<< Write a poem based on the content of the picture.
Input a media path or URL <<< http://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/poem.png
In a world where night and day intertwine,
A boat floats gently, reflecting the moon's shine.
Fireflies dance, their glow a mesmerizing trance,
As the boat sails through a tranquil, enchanted expanse.
"""
```
Example images are shown below:
cat:
 animal:
animal:
 math:
math:
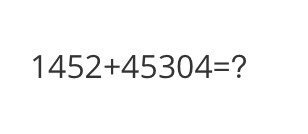 poem:
poem:
 **Single-sample inference**
```python
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
from swift.llm import (
get_model_tokenizer, get_template, inference, ModelType,
get_default_template_type, inference_stream
)
from swift.utils import seed_everything
import torch
model_type = ModelType.cogvlm_17b_chat
template_type = get_default_template_type(model_type)
print(f'template_type: {template_type}')
model, tokenizer = get_model_tokenizer(model_type, torch.float16,
model_kwargs={'device_map': 'auto'})
model.generation_config.max_new_tokens = 256
template = get_template(template_type, tokenizer)
seed_everything(42)
images = ['http://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/road.png']
query = 'How far is it from each city?'
response, _ = inference(model, template, query, images=images)
print(f'query: {query}')
print(f'response: {response}')
# Streaming
query = 'Which city is the farthest?'
images = images
gen = inference_stream(model, template, query, images=images)
print_idx = 0
print(f'query: {query}\nresponse: ', end='')
for response, _ in gen:
delta = response[print_idx:]
print(delta, end='', flush=True)
print_idx = len(response)
print()
"""
query: How far is it from each city?
response: From Mata, it is 14 km; from Yangjiang, it is 62 km; and from Guangzhou, it is 293 km.
query: Which city is the farthest?
response: Guangzhou is the farthest city with a distance of 293 km.
"""
```
Example image is shown below:
road:
**Single-sample inference**
```python
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
from swift.llm import (
get_model_tokenizer, get_template, inference, ModelType,
get_default_template_type, inference_stream
)
from swift.utils import seed_everything
import torch
model_type = ModelType.cogvlm_17b_chat
template_type = get_default_template_type(model_type)
print(f'template_type: {template_type}')
model, tokenizer = get_model_tokenizer(model_type, torch.float16,
model_kwargs={'device_map': 'auto'})
model.generation_config.max_new_tokens = 256
template = get_template(template_type, tokenizer)
seed_everything(42)
images = ['http://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/road.png']
query = 'How far is it from each city?'
response, _ = inference(model, template, query, images=images)
print(f'query: {query}')
print(f'response: {response}')
# Streaming
query = 'Which city is the farthest?'
images = images
gen = inference_stream(model, template, query, images=images)
print_idx = 0
print(f'query: {query}\nresponse: ', end='')
for response, _ in gen:
delta = response[print_idx:]
print(delta, end='', flush=True)
print_idx = len(response)
print()
"""
query: How far is it from each city?
response: From Mata, it is 14 km; from Yangjiang, it is 62 km; and from Guangzhou, it is 293 km.
query: Which city is the farthest?
response: Guangzhou is the farthest city with a distance of 293 km.
"""
```
Example image is shown below:
road:
 ## Fine-tuning
Fine-tuning multimodal large models usually uses **custom datasets**. Here is a demo that can be run directly:
(By default, lora fine-tuning is performed on the qkv of the language and vision models. If you want to fine-tune all linears, you can specify `--lora_target_modules ALL`)
```shell
# Experimental environment: A100
# 50GB GPU memory
CUDA_VISIBLE_DEVICES=0 swift sft \
--model_type cogvlm-17b-chat \
--dataset coco-en-2-mini \
```
[Custom datasets](../LLM/Customization.md#-Recommended-Command-line-arguments) support json, jsonl formats. Here is an example of a custom dataset:
(Supports multi-turn dialogue, but each conversation can only include one image. Support local file paths or URLs for input)
```jsonl
{"query": "55555", "response": "66666", "images": ["image_path"]}
{"query": "eeeee", "response": "fffff", "history": [], "images": ["image_path"]}
{"query": "EEEEE", "response": "FFFFF", "history": [["AAAAA", "BBBBB"], ["CCCCC", "DDDDD"]], "images": ["image_path"]}
```
## Inference After Fine-tuning
Direct inference:
```shell
CUDA_VISIBLE_DEVICES=0 swift infer \
--ckpt_dir output/cogvlm-17b-chat/vx-xxx/checkpoint-xxx \
--load_dataset_config true \
```
**merge-lora** and inference:
```shell
CUDA_VISIBLE_DEVICES=0 swift export \
--ckpt_dir output/cogvlm-17b-chat/vx-xxx/checkpoint-xxx \
--merge_lora true
CUDA_VISIBLE_DEVICES=0 swift infer \
--ckpt_dir output/cogvlm-17b-chat/vx-xxx/checkpoint-xxx-merged \
--load_dataset_config true
```
## Fine-tuning
Fine-tuning multimodal large models usually uses **custom datasets**. Here is a demo that can be run directly:
(By default, lora fine-tuning is performed on the qkv of the language and vision models. If you want to fine-tune all linears, you can specify `--lora_target_modules ALL`)
```shell
# Experimental environment: A100
# 50GB GPU memory
CUDA_VISIBLE_DEVICES=0 swift sft \
--model_type cogvlm-17b-chat \
--dataset coco-en-2-mini \
```
[Custom datasets](../LLM/Customization.md#-Recommended-Command-line-arguments) support json, jsonl formats. Here is an example of a custom dataset:
(Supports multi-turn dialogue, but each conversation can only include one image. Support local file paths or URLs for input)
```jsonl
{"query": "55555", "response": "66666", "images": ["image_path"]}
{"query": "eeeee", "response": "fffff", "history": [], "images": ["image_path"]}
{"query": "EEEEE", "response": "FFFFF", "history": [["AAAAA", "BBBBB"], ["CCCCC", "DDDDD"]], "images": ["image_path"]}
```
## Inference After Fine-tuning
Direct inference:
```shell
CUDA_VISIBLE_DEVICES=0 swift infer \
--ckpt_dir output/cogvlm-17b-chat/vx-xxx/checkpoint-xxx \
--load_dataset_config true \
```
**merge-lora** and inference:
```shell
CUDA_VISIBLE_DEVICES=0 swift export \
--ckpt_dir output/cogvlm-17b-chat/vx-xxx/checkpoint-xxx \
--merge_lora true
CUDA_VISIBLE_DEVICES=0 swift infer \
--ckpt_dir output/cogvlm-17b-chat/vx-xxx/checkpoint-xxx-merged \
--load_dataset_config true
```