# MiniCPM-V 最佳实践
以下内容以`minicpm-v-3b-chat`为例, 如果你想要使用更新版本的 MiniCPM-V 多模态模型(v2), 你可以将`--model_type minicpm-v-3b-chat`切换成`--model_type minicpm-v-v2-chat`.
## 目录
- [环境准备](#环境准备)
- [推理](#推理)
- [微调](#微调)
- [微调后推理](#微调后推理)
## 环境准备
```shell
pip install 'ms-swift[llm]' -U
```
模型链接:
- minicpm-v-3b-chat: [https://modelscope.cn/models/OpenBMB/MiniCPM-V/summary](https://modelscope.cn/models/OpenBMB/MiniCPM-V/summary)
- minicpm-v-v2-chat: [https://modelscope.cn/models/OpenBMB/MiniCPM-V-2/summary](https://modelscope.cn/models/OpenBMB/MiniCPM-V-2/summary)
## 推理
推理minicpm-v-3b-chat:
```shell
# Experimental environment: A10, 3090, V100, ...
# 10GB GPU memory
CUDA_VISIBLE_DEVICES=0 swift infer --model_type minicpm-v-3b-chat
```
输出: (支持传入本地路径或URL)
```python
"""
<<< 描述这张图片
Input a media path or URL <<< http://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/cat.png
该图像的特点是一只黑白相间的猫,它的眼睛睁得大大的,似乎在凝视着相机。这只猫看起来很小,可能是一只幼猫。
--------------------------------------------------
<<< clear
<<< 图中有几只羊?
Input a media path or URL <<< http://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/animal.png
图中有四只羊。
--------------------------------------------------
<<< clear
<<< 计算结果是多少
Input a media path or URL <<< http://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/math.png
计算结果为1452 + 4530 = 5982。
--------------------------------------------------
<<< clear
<<< 根据图片中的内容写首诗
Input a media path or URL <<< http://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/poem.png
在宁静的夜晚,一艘船在平静的湖面上航行。
"""
```
示例图片如下:
cat:
 animal:
animal:
 math:
math:
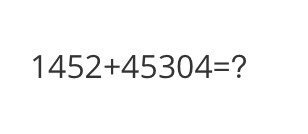 poem:
poem:
 **单样本推理**
```python
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
from swift.llm import (
get_model_tokenizer, get_template, inference, ModelType,
get_default_template_type, inference_stream
)
from swift.utils import seed_everything
import torch
model_type = ModelType.minicpm_v_3b_chat
template_type = get_default_template_type(model_type)
print(f'template_type: {template_type}')
model, tokenizer = get_model_tokenizer(model_type, torch.bfloat16,
model_kwargs={'device_map': 'auto'})
model.generation_config.max_new_tokens = 256
template = get_template(template_type, tokenizer)
seed_everything(42)
images = ['http://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/road.png']
query = '距离各城市多远?'
response, history = inference(model, template, query, images=images)
print(f'query: {query}')
print(f'response: {response}')
# 流式
query = '距离最远的城市是哪?'
gen = inference_stream(model, template, query, history, images=images)
print_idx = 0
print(f'query: {query}\nresponse: ', end='')
for response, history in gen:
delta = response[print_idx:]
print(delta, end='', flush=True)
print_idx = len(response)
print()
print(f'history: {history}')
"""
query: 距离各城市多远?
response: 广州到深圳的距离是230公里,而深圳到广州的距离是14公里。
query: 距离最远的城市是哪?
response: 距离最远的城市是深圳,它位于广州和深圳之间,距离广州230公里,距离深圳14公里。
history: [['距离各城市多远?', ' 广州到深圳的距离是230公里,而深圳到广州的距离是14公里。'], ['距离最远的城市是哪?', '距离最远的城市是深圳,它位于广州和深圳之间,距离广州230公里,距离深圳14公里。']]
"""
```
示例图片如下:
road:
**单样本推理**
```python
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
from swift.llm import (
get_model_tokenizer, get_template, inference, ModelType,
get_default_template_type, inference_stream
)
from swift.utils import seed_everything
import torch
model_type = ModelType.minicpm_v_3b_chat
template_type = get_default_template_type(model_type)
print(f'template_type: {template_type}')
model, tokenizer = get_model_tokenizer(model_type, torch.bfloat16,
model_kwargs={'device_map': 'auto'})
model.generation_config.max_new_tokens = 256
template = get_template(template_type, tokenizer)
seed_everything(42)
images = ['http://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/road.png']
query = '距离各城市多远?'
response, history = inference(model, template, query, images=images)
print(f'query: {query}')
print(f'response: {response}')
# 流式
query = '距离最远的城市是哪?'
gen = inference_stream(model, template, query, history, images=images)
print_idx = 0
print(f'query: {query}\nresponse: ', end='')
for response, history in gen:
delta = response[print_idx:]
print(delta, end='', flush=True)
print_idx = len(response)
print()
print(f'history: {history}')
"""
query: 距离各城市多远?
response: 广州到深圳的距离是230公里,而深圳到广州的距离是14公里。
query: 距离最远的城市是哪?
response: 距离最远的城市是深圳,它位于广州和深圳之间,距离广州230公里,距离深圳14公里。
history: [['距离各城市多远?', ' 广州到深圳的距离是230公里,而深圳到广州的距离是14公里。'], ['距离最远的城市是哪?', '距离最远的城市是深圳,它位于广州和深圳之间,距离广州230公里,距离深圳14公里。']]
"""
```
示例图片如下:
road:
 ## 微调
多模态大模型微调通常使用**自定义数据集**进行微调. 这里展示可直接运行的demo:
(默认只对LLM部分的qkv进行lora微调. 如果你想对所有linear含vision模型部分都进行微调, 可以指定`--lora_target_modules ALL`. 支持全参数微调.)
```shell
# Experimental environment: A10, 3090, V100, ...
# 10GB GPU memory
CUDA_VISIBLE_DEVICES=0 swift sft \
--model_type minicpm-v-3b-chat \
--dataset coco-en-2-mini \
```
[自定义数据集](../LLM/自定义与拓展.md#-推荐命令行参数的形式)支持json, jsonl样式, 以下是自定义数据集的例子:
(支持多轮对话, 但总的轮次对话只能包含一张图片, 支持传入本地路径或URL)
```jsonl
{"query": "55555", "response": "66666", "images": ["image_path"]}
{"query": "eeeee", "response": "fffff", "history": [], "images": ["image_path"]}
{"query": "EEEEE", "response": "FFFFF", "history": [["AAAAA", "BBBBB"], ["CCCCC", "DDDDD"]], "images": ["image_path"]}
```
## 微调后推理
直接推理:
```shell
CUDA_VISIBLE_DEVICES=0 swift infer \
--ckpt_dir output/minicpm-v-3b-chat/vx-xxx/checkpoint-xxx \
--load_dataset_config true \
```
**merge-lora**并推理:
```shell
CUDA_VISIBLE_DEVICES=0 swift export \
--ckpt_dir output/minicpm-v-3b-chat/vx-xxx/checkpoint-xxx \
--merge_lora true
CUDA_VISIBLE_DEVICES=0 swift infer \
--ckpt_dir output/minicpm-v-3b-chat/vx-xxx/checkpoint-xxx-merged \
--load_dataset_config true
```
## 微调
多模态大模型微调通常使用**自定义数据集**进行微调. 这里展示可直接运行的demo:
(默认只对LLM部分的qkv进行lora微调. 如果你想对所有linear含vision模型部分都进行微调, 可以指定`--lora_target_modules ALL`. 支持全参数微调.)
```shell
# Experimental environment: A10, 3090, V100, ...
# 10GB GPU memory
CUDA_VISIBLE_DEVICES=0 swift sft \
--model_type minicpm-v-3b-chat \
--dataset coco-en-2-mini \
```
[自定义数据集](../LLM/自定义与拓展.md#-推荐命令行参数的形式)支持json, jsonl样式, 以下是自定义数据集的例子:
(支持多轮对话, 但总的轮次对话只能包含一张图片, 支持传入本地路径或URL)
```jsonl
{"query": "55555", "response": "66666", "images": ["image_path"]}
{"query": "eeeee", "response": "fffff", "history": [], "images": ["image_path"]}
{"query": "EEEEE", "response": "FFFFF", "history": [["AAAAA", "BBBBB"], ["CCCCC", "DDDDD"]], "images": ["image_path"]}
```
## 微调后推理
直接推理:
```shell
CUDA_VISIBLE_DEVICES=0 swift infer \
--ckpt_dir output/minicpm-v-3b-chat/vx-xxx/checkpoint-xxx \
--load_dataset_config true \
```
**merge-lora**并推理:
```shell
CUDA_VISIBLE_DEVICES=0 swift export \
--ckpt_dir output/minicpm-v-3b-chat/vx-xxx/checkpoint-xxx \
--merge_lora true
CUDA_VISIBLE_DEVICES=0 swift infer \
--ckpt_dir output/minicpm-v-3b-chat/vx-xxx/checkpoint-xxx-merged \
--load_dataset_config true
```