
Initial commit
Showing
Too many changes to show.
To preserve performance only 707 of 707+ files are displayed.
{kind=link}

510 KB
{kind=link}
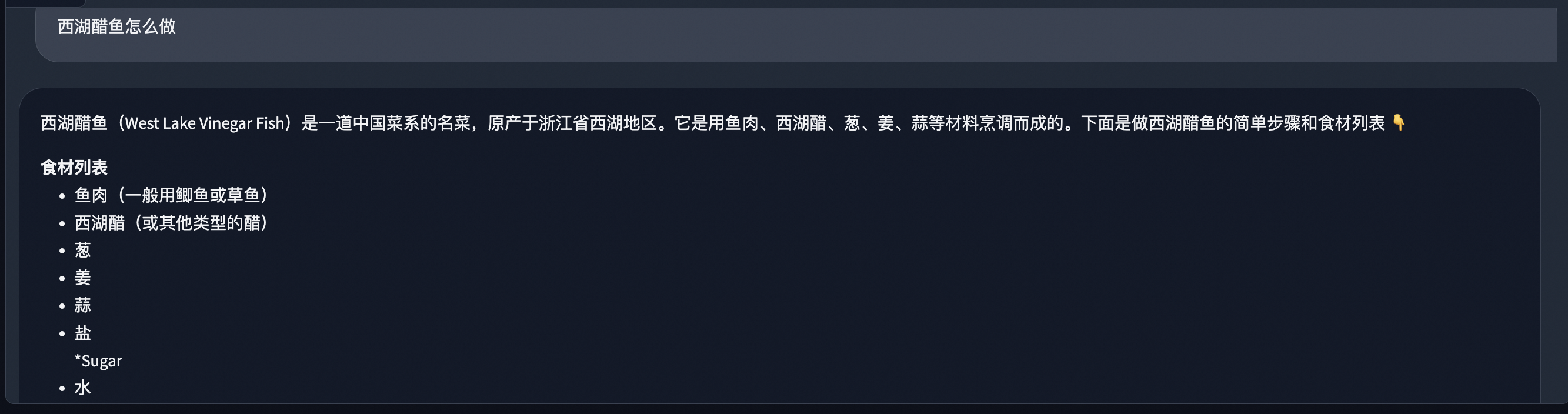
540 KB
{kind=link}
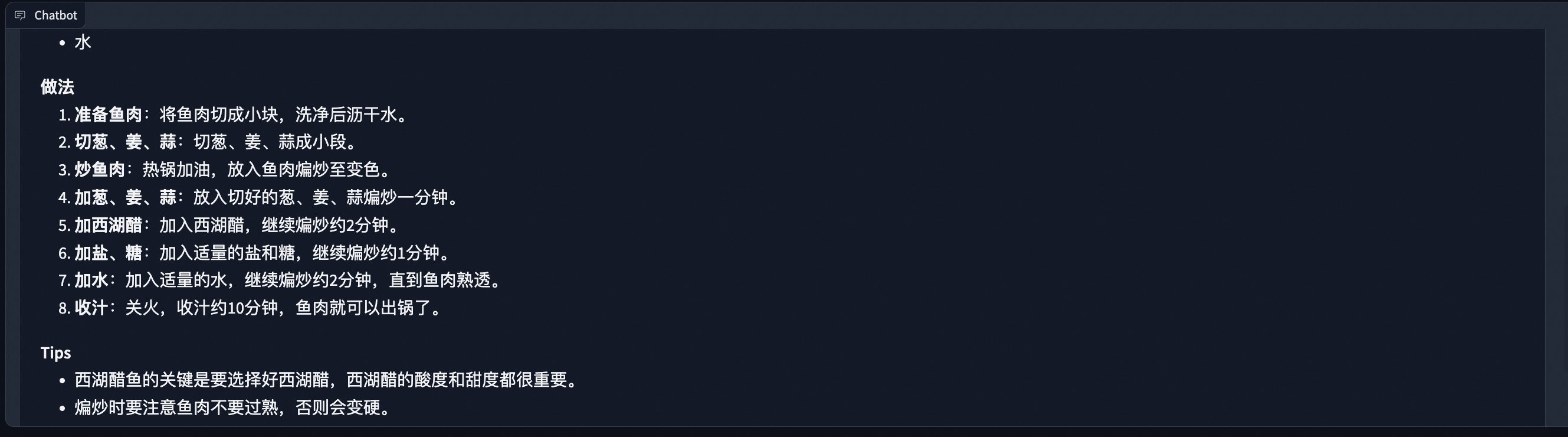
694 KB
{kind=link}

167 KB
{kind=link}

208 KB
{kind=link}
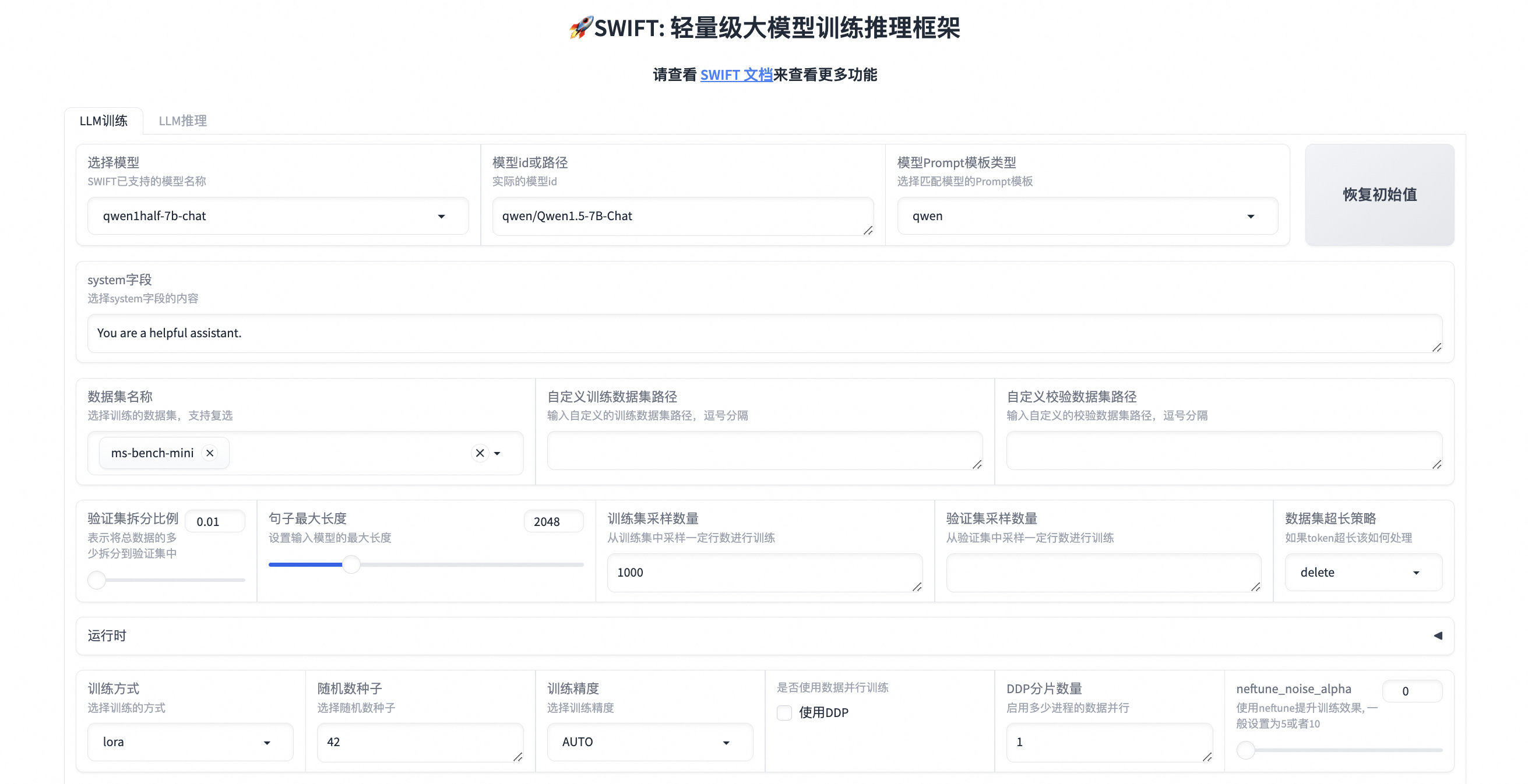
1.77 MB
{kind=link}
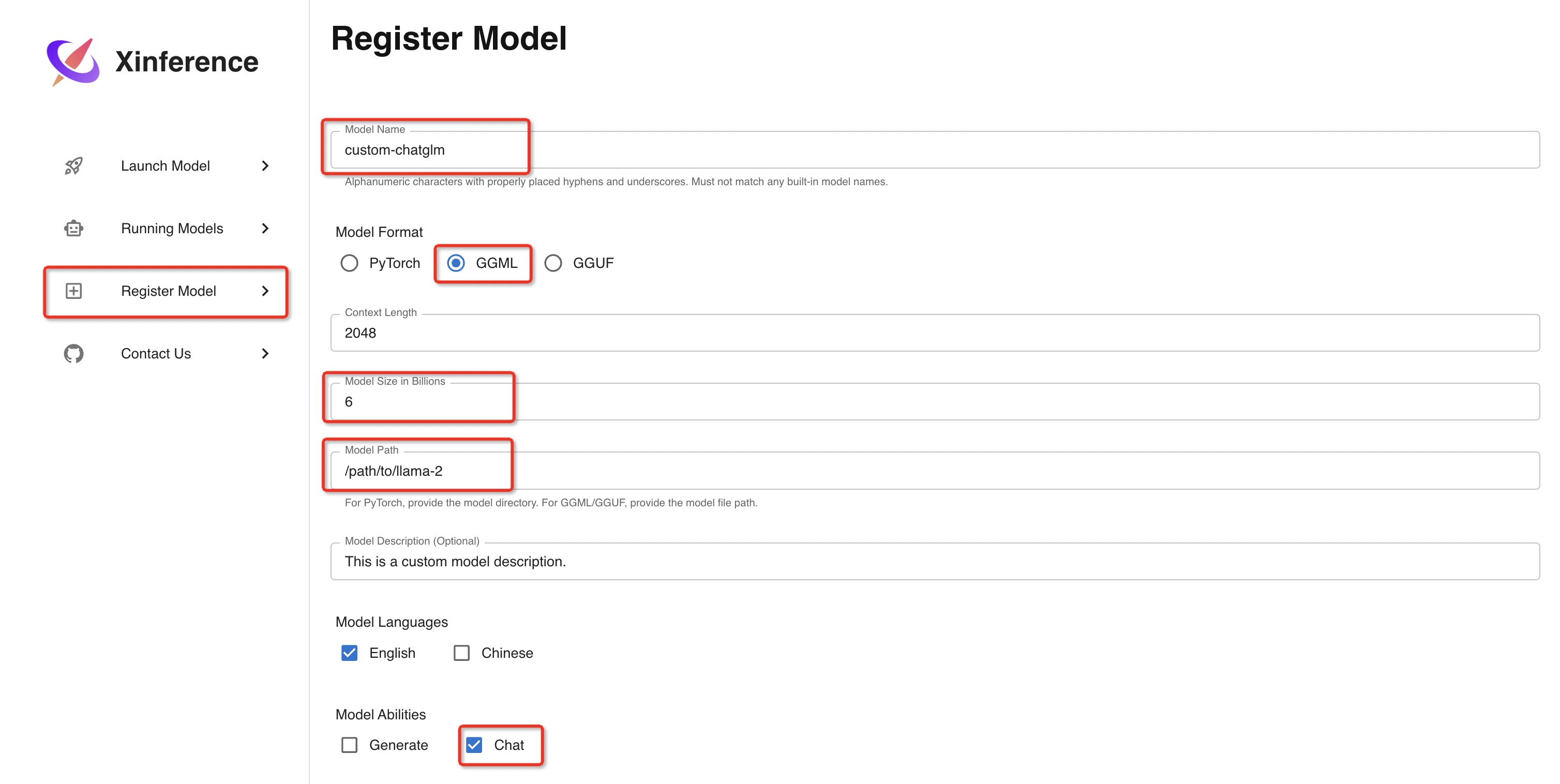
260 KB
510 KB
540 KB
694 KB
167 KB
208 KB
1.77 MB
260 KB