
Initial commit
Showing
Too many changes to show.
To preserve performance only 707 of 707+ files are displayed.
finetune_demo/finetune.py
0 → 100644
finetune_demo/inference.py
0 → 100644
glm-4v_inference.py
0 → 100644
images/GLM.png
0 → 100644
{kind=link}
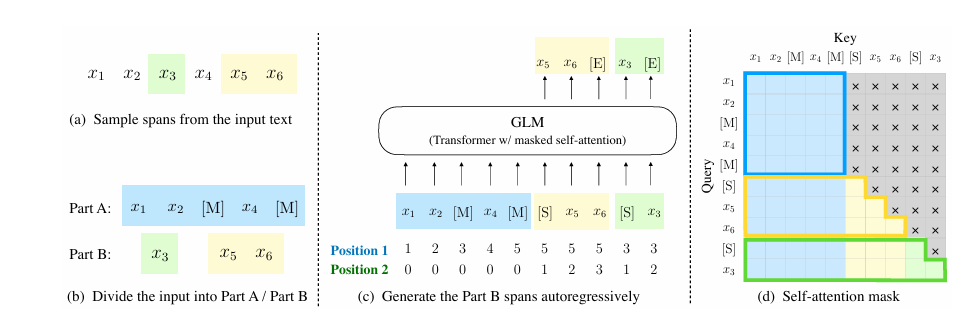
44.1 KB
images/mt.png
0 → 100644
{kind=link}
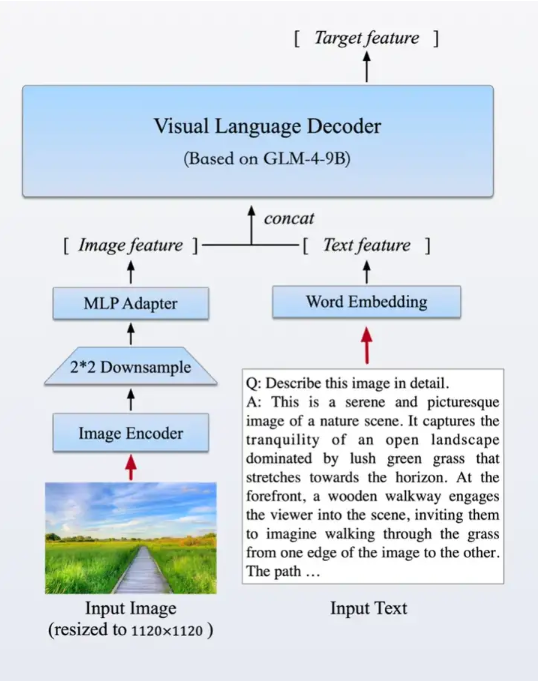
270 KB
images/result.png
0 → 100644
{kind=link}
33.5 KB
images/transformer.jpg
0 → 100644
{kind=link}
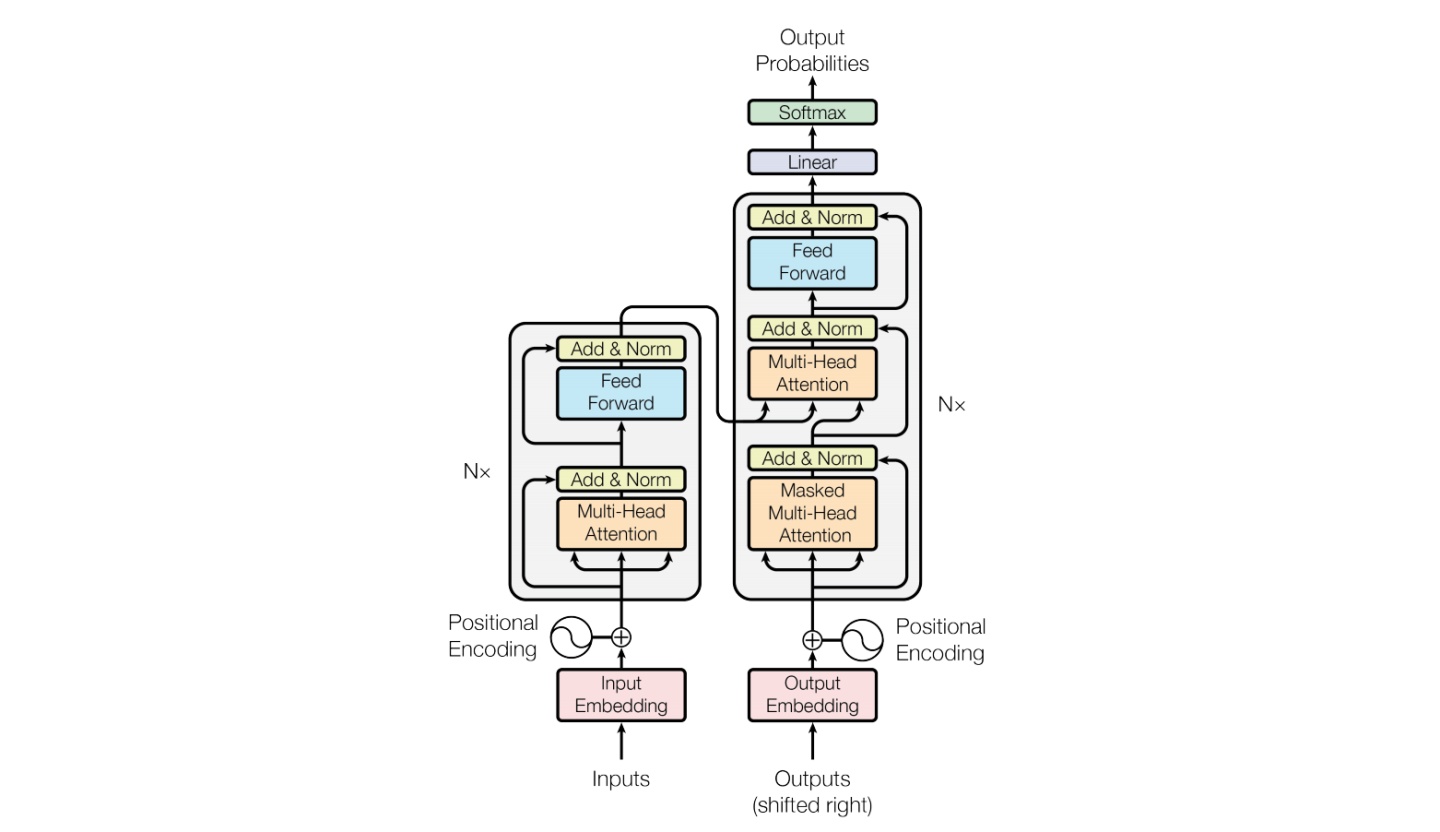
87.9 KB
images/transformer.png
0 → 100644
{kind=link}
112 KB
lora_finetune_multi.sh
0 → 100644
lora_finetune_single.sh
0 → 100644
model.properties
0 → 100644
requirements.txt
0 → 100644
| # use vllm | ||
| # vllm>=0.4.3 | ||
| torch | ||
| torchvision | ||
| transformers==4.40.0 | ||
| huggingface-hub>=0.23.1 | ||
| sentencepiece>=0.2.0 | ||
| pydantic>=2.7.1 | ||
| timm>=0.9.16 | ||
| tiktoken>=0.7.0 | ||
| accelerate>=0.30.1 | ||
| sentence_transformers>=2.7.0 | ||
| # web demo | ||
| gradio>=4.33.0 | ||
| # openai demo | ||
| openai>=1.31.1 | ||
| einops>=0.7.0 | ||
| sse-starlette>=2.1.0 | ||
| # INT4 | ||
| bitsandbytes>=0.43.1 | ||
| # PEFT model, not need if you don't use PEFT finetune model. | ||
| peft>=0.11.0 | ||
| \ No newline at end of file |
resources/WECHAT.md
0 → 100644
resources/eval_needle.jpeg
0 → 100644
{kind=link}

452 KB
resources/longbench.png
0 → 100644
{kind=link}

164 KB
resources/wechat.jpg
0 → 100644
{kind=link}

151 KB