Skip to content
GitLab
Menu
Projects
Groups
Snippets
Loading...
Help
Help
Support
Community forum
Keyboard shortcuts
?
Submit feedback
Contribute to GitLab
Sign in / Register
Toggle navigation
Menu
Open sidebar
ModelZoo
GLM-4V_pytorch
Commits
1bfbcff0
Commit
1bfbcff0
authored
Jun 13, 2024
by
wanglch
Browse files
Initial commit
parents
Pipeline
#1204
canceled with stages
Changes
707
Pipelines
1
Hide whitespace changes
Inline
Side-by-side
Showing
20 changed files
with
879 additions
and
0 deletions
+879
-0
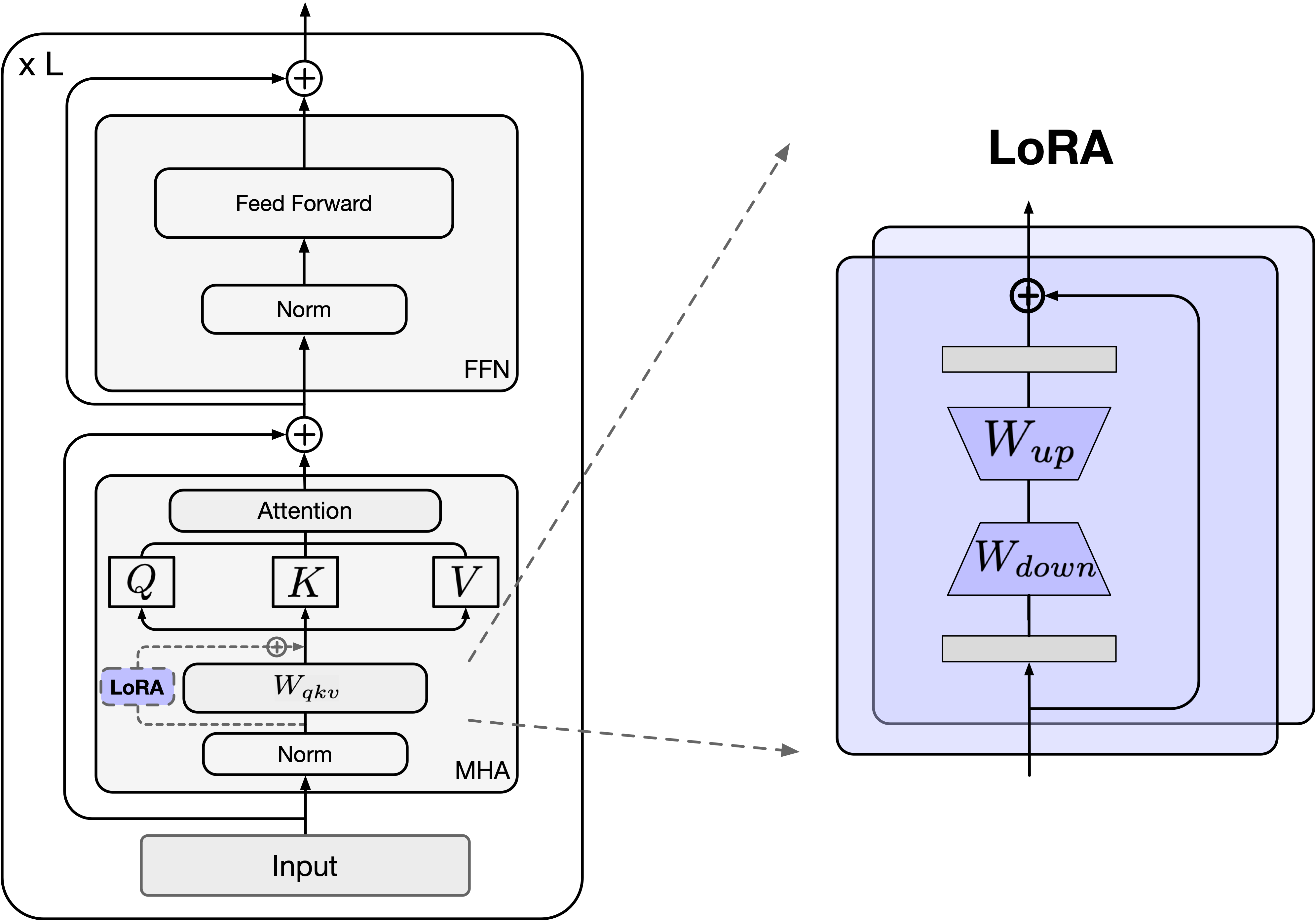
swift-main/examples/pytorch/cv/notebook/resources/images/lora.png
...in/examples/pytorch/cv/notebook/resources/images/lora.png
+0
-0
swift-main/examples/pytorch/cv/notebook/resources/images/prompt.png
.../examples/pytorch/cv/notebook/resources/images/prompt.png
+0
-0
swift-main/examples/pytorch/cv/notebook/resources/images/restuningbypass.png
.../pytorch/cv/notebook/resources/images/restuningbypass.png
+0
-0
swift-main/examples/pytorch/cv/notebook/resources/images/vit.jpg
...ain/examples/pytorch/cv/notebook/resources/images/vit.jpg
+0
-0
swift-main/examples/pytorch/cv/notebook/swift_vision.ipynb
swift-main/examples/pytorch/cv/notebook/swift_vision.ipynb
+650
-0
swift-main/examples/pytorch/llm/app.py
swift-main/examples/pytorch/llm/app.py
+16
-0
swift-main/examples/pytorch/llm/custom.py
swift-main/examples/pytorch/llm/custom.py
+93
-0
swift-main/examples/pytorch/llm/eval_example/custom_ceval/default_dev.csv
...les/pytorch/llm/eval_example/custom_ceval/default_dev.csv
+5
-0
swift-main/examples/pytorch/llm/eval_example/custom_ceval/default_val.csv
...les/pytorch/llm/eval_example/custom_ceval/default_val.csv
+4
-0
swift-main/examples/pytorch/llm/eval_example/custom_config.json
...main/examples/pytorch/llm/eval_example/custom_config.json
+14
-0
swift-main/examples/pytorch/llm/eval_example/custom_general_qa/default.jsonl
.../pytorch/llm/eval_example/custom_general_qa/default.jsonl
+3
-0
swift-main/examples/pytorch/llm/llm_dpo.py
swift-main/examples/pytorch/llm/llm_dpo.py
+7
-0
swift-main/examples/pytorch/llm/llm_infer.py
swift-main/examples/pytorch/llm/llm_infer.py
+7
-0
swift-main/examples/pytorch/llm/llm_orpo.py
swift-main/examples/pytorch/llm/llm_orpo.py
+7
-0
swift-main/examples/pytorch/llm/llm_sft.py
swift-main/examples/pytorch/llm/llm_sft.py
+7
-0
swift-main/examples/pytorch/llm/llm_simpo.py
swift-main/examples/pytorch/llm/llm_simpo.py
+7
-0
swift-main/examples/pytorch/llm/rome_example/request.json
swift-main/examples/pytorch/llm/rome_example/request.json
+12
-0
swift-main/examples/pytorch/llm/rome_infer.py
swift-main/examples/pytorch/llm/rome_infer.py
+6
-0
swift-main/examples/pytorch/llm/scripts/atom_7b_chat/lora/infer.sh
...n/examples/pytorch/llm/scripts/atom_7b_chat/lora/infer.sh
+11
-0
swift-main/examples/pytorch/llm/scripts/atom_7b_chat/lora/sft.sh
...ain/examples/pytorch/llm/scripts/atom_7b_chat/lora/sft.sh
+30
-0
No files found.
Too many changes to show.
To preserve performance only
707 of 707+
files are displayed.
Plain diff
Email patch
swift-main/examples/pytorch/cv/notebook/resources/images/lora.png
0 → 100644
View file @
1bfbcff0
421 KB
swift-main/examples/pytorch/cv/notebook/resources/images/prompt.png
0 → 100644
View file @
1bfbcff0
345 KB
swift-main/examples/pytorch/cv/notebook/resources/images/restuningbypass.png
0 → 100644
View file @
1bfbcff0
838 KB
swift-main/examples/pytorch/cv/notebook/resources/images/vit.jpg
0 → 100644
View file @
1bfbcff0
234 KB
swift-main/examples/pytorch/cv/notebook/swift_vision.ipynb
0 → 100644
View file @
1bfbcff0
{
"cells": [
{
"cell_type": "markdown",
"id": "7c12609e-3d9a-4ced-a670-4c0a358fac63",
"metadata": {},
"source": [
"# SWIFT在【基础视觉领域】的应用"
]
},
{
"cell_type": "markdown",
"id": "1a7a064e-3171-44ce-a45a-ba329998807d",
"metadata": {},
"source": [
"#### 使用样例见:https://github.com/modelscope/swift/tree/main/examples/pytorch/cv/notebook"
]
},
{
"cell_type": "markdown",
"id": "78a535eb-922f-4a83-9f08-cc4a5ebae377",
"metadata": {},
"source": [
"## 1. 图像分类任务"
]
},
{
"cell_type": "markdown",
"id": "79638268-c23f-4188-9811-2c8af15a9a40",
"metadata": {},
"source": [
"### 1.1 安装与导入包\n",
"- 安装必要的依赖安装包\n",
"```bash\n",
"pip install 'ms-swift[aigc]' -U\n",
"pip install modelscope\n",
"```\n",
"- 导入必要的依赖安装包\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "5752c15f-e449-44e3-9222-b0e1ad03767d",
"metadata": {},
"outputs": [],
"source": [
"# basic / third-party\n",
"import os\n",
"import tempfile\n",
"import torch\n",
"import torchvision\n",
"import transformers\n",
"\n",
"# SWIFT\n",
"from swift import Swift, SwiftModel, snapshot_download, push_to_hub\n",
"from swift import AdapterConfig, LoRAConfig, PromptConfig, SideConfig, ResTuningConfig\n",
"\n",
"# Modelscope\n",
"import modelscope\n",
"from modelscope.pipelines import pipeline\n",
"from modelscope.models import Model\n",
"from modelscope.utils.config import Config\n",
"from modelscope.metainfo import Trainers\n",
"from modelscope.msdatasets import MsDataset\n",
"from modelscope.trainers import build_trainer\n",
"from modelscope.utils.constant import DEFAULT_MODEL_REVISION, Invoke, ModelFile\n"
]
},
{
"cell_type": "markdown",
"id": "bc63678e-8b0b-42e3-83d4-4a1c6bdeca70",
"metadata": {
"tags": []
},
"source": [
"### 1.2 数据集\n",
"- [基础模型基准评测集 (FME Benchmark)](https://modelscope.cn/datasets/damo/foundation_model_evaluation_benchmark/dataPeview) 子集 - Oxford Flowers\n",
"\n",
"| 序号 | 数据集 | 描述 | 类别数量 | 训练集数量 | 验证集数量 | 测试集数量 | 样例 | 备注 |\n",
"|:----:|:-------------------------------------------------------------------------:|:--------:|:--------:|:----------:|:----------:|:----------:|:---------------------------------------------------------------------------------------------------------:|:--------------------------------------------------------------------------------------------:|\n",
"| 1 | [Oxford Flowers](https://www.robots.ox.ac.uk/~vgg/data/flowers/102/) | 花卉 | 102 | 1020 | 1020 | 6149 | <img decoding=\"async\" src=\"resources/images/OxfordFlowers102_image_00001.jpeg\" width=50> | [预览](https://modelscope.cn/datasets/damo/foundation_model_evaluation_benchmark/dataPeview) |\n",
"- 加载数据集"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "b6dad2a2-bd32-45e5-9f34-5df9af1a274e",
"metadata": {},
"outputs": [],
"source": [
"num_classes = 102\n",
"CLASSES = ['pink primrose', 'hard-leaved pocket orchid', 'canterbury bells', 'sweet pea', 'english marigold', 'tiger lily', 'moon orchid', 'bird of paradise', 'monkshood', 'globe thistle', 'snapdragon', \"colt's foot\", 'king protea', 'spear thistle', 'yellow iris', 'globe-flower', 'purple coneflower', 'peruvian lily', 'balloon flower', 'giant white arum lily', 'fire lily', 'pincushion flower', 'fritillary', 'red ginger', 'grape hyacinth', 'corn poppy', 'prince of wales feathers', 'stemless gentian', 'artichoke', 'sweet william', 'carnation', 'garden phlox', 'love in the mist', 'mexican aster', 'alpine sea holly', 'ruby-lipped cattleya', 'cape flower', 'great masterwort', 'siam tulip', 'lenten rose', 'barbeton daisy', 'daffodil', 'sword lily', 'poinsettia', 'bolero deep blue', 'wallflower', 'marigold', 'buttercup', 'oxeye daisy', 'common dandelion', 'petunia', 'wild pansy', 'primula', 'sunflower', 'pelargonium', 'bishop of llandaff', 'gaura', 'geranium', 'orange dahlia', 'pink-yellow dahlia?', 'cautleya spicata', 'japanese anemone', 'black-eyed susan', 'silverbush', 'californian poppy', 'osteospermum', 'spring crocus', 'bearded iris', 'windflower', 'tree poppy', 'gazania', 'azalea', 'water lily', 'rose', 'thorn apple', 'morning glory', 'passion flower', 'lotus', 'toad lily', 'anthurium', 'frangipani', 'clematis', 'hibiscus', 'columbine', 'desert-rose', 'tree mallow', 'magnolia', 'cyclamen', 'watercress', 'canna lily', 'hippeastrum', 'bee balm', 'ball moss', 'foxglove', 'bougainvillea', 'camellia', 'mallow', 'mexican petunia', 'bromelia', 'blanket flower', 'trumpet creeper', 'blackberry lily']\n",
"img_test = \"resources/images/OxfordFlowers102_image_00001.jpeg\"\n",
"train_dataset = MsDataset.load(\n",
" 'foundation_model_evaluation_benchmark',\n",
" namespace='damo',\n",
" subset_name='OxfordFlowers',\n",
" split='train')\n",
"\n",
"eval_dataset = MsDataset.load(\n",
" 'foundation_model_evaluation_benchmark',\n",
" namespace='damo',\n",
" subset_name='OxfordFlowers',\n",
" split='eval')"
]
},
{
"cell_type": "markdown",
"id": "58dda012-8315-4f4f-9170-09a16747b512",
"metadata": {},
"source": [
"### 1.3 一站式训练 [Modelscope + Swift]"
]
},
{
"cell_type": "markdown",
"id": "5dc3b8d9-59f0-43d8-8f39-04a9b7cbc354",
"metadata": {},
"source": [
"#### Vision Transformers (ViT)\n",
"\n",
"<img src=\"resources/images/vit.jpg\" width=\"800\" align=\"middle\" />"
]
},
{
"cell_type": "markdown",
"id": "077e3bdd-c051-41e4-815b-a8b80c17d5db",
"metadata": {},
"source": [
"#### Swift - ViT - Adapter\n",
"\n",
"<img src=\"resources/images/adapter.png\" width=\"500\" align=\"middle\" />"
]
},
{
"cell_type": "markdown",
"id": "ee1a70e7-30c8-43ff-864d-c648fad9187e",
"metadata": {},
"source": [
"#### 1.3.1 使用modelscope加载ViT模型"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "95bbaf3f-6364-43b1-9354-00082cc22572",
"metadata": {},
"outputs": [],
"source": [
"model_id = 'damo/cv_vitb16_classification_vision-efficient-tuning-base'\n",
"task = 'vision-efficient-tuning'\n",
"revision = 'v1.0.2'\n",
"\n",
"model_dir = snapshot_download(model_id)\n",
"cfg_dict = Config.from_file(os.path.join(model_dir, ModelFile.CONFIGURATION))\n",
"cfg_dict.model.head.num_classes = num_classes\n",
"cfg_dict.CLASSES = CLASSES\n",
"model = Model.from_pretrained(model_id, task=task, cfg_dict=cfg_dict, revision=revision)"
]
},
{
"cell_type": "markdown",
"id": "465ab9f9-f151-4d0e-bc44-88238686c885",
"metadata": {},
"source": [
"#### 1.3.2 查看模型信息"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "725f9633-c53a-4b12-bb8c-733bc5987f3a",
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"print(model)"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "3ab695b3-cfef-4288-8ab8-40b4069ef578",
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"module_keys = [key for key, _ in model.named_modules()]\n",
"print(module_keys)"
]
},
{
"cell_type": "markdown",
"id": "be0372f6-acf8-4894-8fbd-13aea414be9e",
"metadata": {},
"source": [
"#### 1.3.3 配置SwiftConfig + 模型准备"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "f626c63f-81c6-4197-ac3a-7c668c953242",
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"# model.backbone.blocks.0.mlp ~ model.backbone.blocks.11.mlp\n",
"adapter_config = AdapterConfig(\n",
" dim=768,\n",
" hidden_pos=0,\n",
" target_modules=r'.*blocks\\.\\d+\\.mlp$',\n",
" adapter_length=10\n",
")\n",
"model = Swift.prepare_model(model, config=adapter_config)"
]
},
{
"cell_type": "markdown",
"id": "2ec8ace9-6c1d-4d6c-a929-463be4870c4a",
"metadata": {},
"source": [
"#### 1.3.4 查看微调模型信息"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "bcf1b8dd-3e15-49e3-9224-748fb1c778a8",
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"print(model)\n",
"print(model.get_trainable_parameters())"
]
},
{
"cell_type": "markdown",
"id": "01d97bc2-7319-4892-8294-481a3ea8b29d",
"metadata": {},
"source": [
"#### 1.3.5 训练与评测"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "405e6923-7fa1-4303-b48e-744cedacbd7d",
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"def cfg_modify_fn(cfg):\n",
" cfg.model.head.num_classes = num_classes\n",
" cfg.model.finetune = True\n",
" cfg.CLASSES = CLASSES\n",
" cfg.train.max_epochs = 5\n",
" cfg.train.lr_scheduler.T_max = 10\n",
" return cfg\n",
"\n",
"work_dir = \"tmp/cv_swift_adapter\"\n",
"kwargs = dict(\n",
" model=model,\n",
" cfg_file=os.path.join(model_dir, 'configuration.json'),\n",
" work_dir=work_dir,\n",
" train_dataset=train_dataset,\n",
" eval_dataset=eval_dataset,\n",
" cfg_modify_fn=cfg_modify_fn,\n",
")\n",
"\n",
"trainer = build_trainer(name=Trainers.vision_efficient_tuning, default_args=kwargs)\n",
"trainer.train()\n",
"result = trainer.evaluate()\n",
"print(f'Vision-efficient-tuning-adapter train output: {result}.')\n",
"print(os.system(\"nvidia-smi\"))\n",
"torch.cuda.empty_cache()\n",
"del trainer\n",
"del model"
]
},
{
"cell_type": "markdown",
"id": "75ccf7fd-9bad-4cd8-a8da-9b257b4468c9",
"metadata": {},
"source": [
"### 1.4 Parameter-Efficient Tuners"
]
},
{
"cell_type": "markdown",
"id": "78394968-ad52-4d7c-9168-a9b9cc850a29",
"metadata": {},
"source": [
"#### Swift - ViT - Prompt\n",
"\n",
"<img src=\"resources/images/prompt.png\" width=\"500\" align=\"middle\" />"
]
},
{
"cell_type": "markdown",
"id": "94d90328-853c-43ef-af8d-fdad281d9e01",
"metadata": {},
"source": [
"#### 1.4.1 模型准备"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "d87835d3-c679-4224-84a8-e15043f09543",
"metadata": {},
"outputs": [],
"source": [
"model_id = 'damo/cv_vitb16_classification_vision-efficient-tuning-base'\n",
"task = 'vision-efficient-tuning'\n",
"revision = 'v1.0.2'\n",
"\n",
"model_dir = snapshot_download(model_id)\n",
"cfg_dict = Config.from_file(os.path.join(model_dir, ModelFile.CONFIGURATION))\n",
"cfg_dict.model.head.num_classes = num_classes\n",
"cfg_dict.CLASSES = CLASSES\n",
"model = Model.from_pretrained(model_id, task=task, cfg_dict=cfg_dict, revision=revision)\n",
"\n",
"prompt_config = PromptConfig(\n",
" dim=768,\n",
" target_modules=r'.*blocks\\.\\d+$', \n",
" embedding_pos=0, \n",
" prompt_length=10,\n",
" attach_front=False\n",
")\n",
"\n",
"model = Swift.prepare_model(model, config=prompt_config)\n",
"\n",
"print(model.get_trainable_parameters())"
]
},
{
"cell_type": "markdown",
"id": "33e87b11-0862-41aa-97e4-7f44578d6e0f",
"metadata": {},
"source": [
"#### 1.4.2 模型训练"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "76f027f7-070e-47f1-a607-37eb3d549a39",
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"def cfg_modify_fn(cfg):\n",
" cfg.model.head.num_classes = num_classes\n",
" cfg.model.finetune = True\n",
" cfg.CLASSES = CLASSES\n",
" cfg.train.max_epochs = 5\n",
" cfg.train.lr_scheduler.T_max = 10\n",
" return cfg\n",
"\n",
"work_dir = \"tmp/cv_swift_prompt\"\n",
"kwargs = dict(\n",
" model=model,\n",
" cfg_file=os.path.join(model_dir, 'configuration.json'),\n",
" work_dir=work_dir,\n",
" train_dataset=train_dataset,\n",
" eval_dataset=eval_dataset,\n",
" cfg_modify_fn=cfg_modify_fn,\n",
")\n",
"\n",
"trainer = build_trainer(name=Trainers.vision_efficient_tuning, default_args=kwargs)\n",
"trainer.train()\n",
"result = trainer.evaluate()\n",
"print(f'Vision-efficient-tuning-prompt train output: {result}.')\n",
"print(os.system(\"nvidia-smi\"))\n",
"torch.cuda.empty_cache()\n",
"del trainer\n",
"del model"
]
},
{
"cell_type": "markdown",
"id": "f02fe752-760c-4f0b-8076-d1ab4021ef52",
"metadata": {},
"source": [
"### 1.5 Memory-Efficient Tuners"
]
},
{
"cell_type": "markdown",
"id": "ca90fbfc-bbd0-40cd-9803-544136eaa0cb",
"metadata": {},
"source": [
"#### Swift - ViT - Res-Tuning\n",
"\n",
"<img src=\"resources/images/restuningbypass.png\" width=\"700\" align=\"middle\" />\n",
"\n",
"*Res-Tuning: A Flexible and Efficient Tuning Paradigm via Unbinding Tuner from Backbone*"
]
},
{
"cell_type": "markdown",
"id": "c7bef020-ebbd-4695-8b21-2df6b198c589",
"metadata": {},
"source": [
"#### 1.5.1 模型准备"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "07bd598a-ca36-4e04-a22b-e2f3f8e01af6",
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"model_id = 'damo/cv_vitb16_classification_vision-efficient-tuning-base'\n",
"task = 'vision-efficient-tuning'\n",
"revision = 'v1.0.2'\n",
"\n",
"model_dir = snapshot_download(model_id)\n",
"cfg_dict = Config.from_file(os.path.join(model_dir, ModelFile.CONFIGURATION))\n",
"cfg_dict.model.head.num_classes = num_classes\n",
"cfg_dict.CLASSES = CLASSES\n",
"model = Model.from_pretrained(model_id, task=task, cfg_dict=cfg_dict, revision=revision)\n",
"\n",
"restuning_config = ResTuningConfig(\n",
" dims=768,\n",
" root_modules=r'.*backbone.blocks.0$',\n",
" stem_modules=r'.*backbone.blocks\\.\\d+$',\n",
" target_modules=r'.*backbone.norm',\n",
" target_modules_hook='input',\n",
" tuner_cfg='res_adapter',\n",
")\n",
"\n",
"model = Swift.prepare_model(model, config=restuning_config)\n",
"\n",
"print(model.get_trainable_parameters())"
]
},
{
"cell_type": "markdown",
"id": "1bc0ac52-9d92-4eb2-b299-0896c33d78ee",
"metadata": {},
"source": [
"#### 1.5.2 模型训练"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "09ccc2f4-059b-4502-8d97-9efb169d121f",
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"def cfg_modify_fn(cfg):\n",
" cfg.model.head.num_classes = num_classes\n",
" cfg.model.finetune = True\n",
" cfg.CLASSES = CLASSES\n",
" cfg.train.max_epochs = 5\n",
" cfg.train.lr_scheduler.T_max = 10\n",
" return cfg\n",
"\n",
"work_dir = \"tmp/cv_swift_restuning\"\n",
"kwargs = dict(\n",
" model=model,\n",
" cfg_file=os.path.join(model_dir, 'configuration.json'),\n",
" work_dir=work_dir,\n",
" train_dataset=train_dataset,\n",
" eval_dataset=eval_dataset,\n",
" cfg_modify_fn=cfg_modify_fn,\n",
")\n",
"\n",
"trainer = build_trainer(name=Trainers.vision_efficient_tuning, default_args=kwargs)\n",
"trainer.train()\n",
"result = trainer.evaluate()\n",
"print(f'Vision-efficient-tuning-restuning train output: {result}.')\n",
"print(os.system(\"nvidia-smi\"))\n",
"torch.cuda.empty_cache()\n",
"del trainer\n",
"del model"
]
},
{
"cell_type": "markdown",
"id": "7ec9fda9-89bc-4dd7-8b21-f4a66cadf552",
"metadata": {},
"source": [
"### 1.6 更多基础模型及工具包使用样例"
]
},
{
"cell_type": "markdown",
"id": "c24c2d64-f050-45ff-b34f-e07c8eeb1dde",
"metadata": {},
"source": [
"#### 1.6.1 Transformers\n",
"\n",
"安装依赖包:pip install transformers"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "e36bf7a9-ef4d-4788-91bc-682d665ecff1",
"metadata": {},
"outputs": [],
"source": [
"# 创建模型\n",
"from transformers import AutoModelForImageClassification\n",
"\n",
"model_dir = snapshot_download(\"AI-ModelScope/vit-base-patch16-224\")\n",
"model = AutoModelForImageClassification.from_pretrained(model_dir)\n",
"module_keys = [key for key, _ in model.named_modules()]\n",
"print(module_keys)"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "f074f2e0-3ba9-4f2c-ae22-75f92adde979",
"metadata": {},
"outputs": [],
"source": [
"# 创建微调模型\n",
"prompt_config = PromptConfig(\n",
" dim=768,\n",
" target_modules=r'.*layer\\.\\d+$', \n",
" embedding_pos=0, \n",
" prompt_length=10, \n",
" attach_front=False \n",
")\n",
"\n",
"adapter_config = AdapterConfig(\n",
" dim=768, \n",
" hidden_pos=0, \n",
" target_modules=r'.*attention.output.dense$', \n",
" adapter_length=10 \n",
")\n",
"\n",
"model = Swift.prepare_model(model, {\"adapter_tuner\": adapter_config, \"prompt_tuner\": prompt_config})\n",
"model.get_trainable_parameters()\n",
"print(model(torch.ones(1, 3, 224, 224)).logits.shape)"
]
},
{
"cell_type": "markdown",
"id": "69a8e3cc-95ca-4576-9a57-cd06f6cac278",
"metadata": {},
"source": [
"#### 1.6.2 TIMM\n",
"\n",
"安装依赖包:pip install timm"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "4c533bd0-da55-4044-9fcc-2f39dad3b456",
"metadata": {},
"outputs": [],
"source": [
"# 创建模型\n",
"import timm\n",
"\n",
"model = timm.create_model(\"vit_base_patch16_224\", pretrained=False, num_classes=100)\n",
"module_keys = [key for key, _ in model.named_modules()]\n",
"print(module_keys)"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "3a5eb5d3-d29c-41bb-b6c4-499d795424a7",
"metadata": {},
"outputs": [],
"source": [
"# 创建模型\n",
"restuning_config = ResTuningConfig(\n",
" dims=768,\n",
" root_modules=r'.*blocks.0$',\n",
" stem_modules=r'.*blocks\\.\\d+$',\n",
" target_modules=r'norm',\n",
" tuner_cfg='res_adapter'\n",
")\n",
"\n",
"model = Swift.prepare_model(model, restuning_config)\n",
"model.get_trainable_parameters()\n",
"print(model(torch.ones(1, 3, 224, 224)).shape)"
]
},
{
"cell_type": "markdown",
"id": "416ed083-2d2b-4b63-aa17-0316fe6cd244",
"metadata": {},
"source": [
"### 1.7 更多任务"
]
},
{
"cell_type": "markdown",
"id": "2fbd8b13-2f2f-435f-94b0-8c06e1c6b618",
"metadata": {},
"source": [
"SWIFT提供的是对模型层面进行微调的能力,故当不同的任务采用相似的基础模型架构时,即可泛化到不同的任务中,如检测、分割等。"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "f2dd914a-750c-4723-b334-c1824a2e63b5",
"metadata": {},
"outputs": [],
"source": []
}
],
"metadata": {
"kernelspec": {
"display_name": "aigc_env",
"language": "python",
"name": "aigc_env"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.8.16"
}
},
"nbformat": 4,
"nbformat_minor": 5
}
swift-main/examples/pytorch/llm/app.py
0 → 100644
View file @
1bfbcff0
# Copyright (c) Alibaba, Inc. and its affiliates.
# import os
# os.environ['CUDA_VISIBLE_DEVICES'] = '0'
import
custom
from
swift.llm
import
AppUIArguments
,
ModelType
,
app_ui_main
if
__name__
==
'__main__'
:
# Please refer to the `infer.sh` for setting the parameters.
# text-generation
# args = AppUIArguments(model_type=ModelType.chatglm3_6b_base)
# or chat
args
=
AppUIArguments
(
model_type
=
ModelType
.
qwen_7b_chat_int4
)
# or load from ckpt dir
# args = AppUIArguments(ckpt_dir='xxx/vx-xxx/checkpoint-xxx')
app_ui_main
(
args
)
swift-main/examples/pytorch/llm/custom.py
0 → 100644
View file @
1bfbcff0
# Copyright (c) Alibaba, Inc. and its affiliates.
from
typing
import
Any
,
Dict
,
Optional
,
Tuple
from
datasets
import
Dataset
as
HfDataset
from
modelscope
import
AutoConfig
,
AutoModelForCausalLM
,
AutoTokenizer
,
MsDataset
from
torch
import
dtype
as
Dtype
from
transformers.utils.versions
import
require_version
from
swift.llm
import
(
LoRATM
,
Template
,
TemplateType
,
dataset_map
,
get_dataset
,
get_dataset_from_repo
,
get_model_tokenizer
,
get_template
,
print_example
,
register_dataset
,
register_model
,
register_template
)
from
swift.utils
import
get_logger
logger
=
get_logger
()
class
CustomModelType
:
tigerbot_7b
=
'tigerbot-7b'
tigerbot_13b
=
'tigerbot-13b'
tigerbot_13b_chat
=
'tigerbot-13b-chat'
class
CustomTemplateType
:
tigerbot
=
'tigerbot'
class
CustomDatasetName
:
stsb_en
=
'stsb-en'
@
register_model
(
CustomModelType
.
tigerbot_7b
,
'TigerResearch/tigerbot-7b-base-v3'
,
LoRATM
.
llama2
,
TemplateType
.
default_generation
)
@
register_model
(
CustomModelType
.
tigerbot_13b
,
'TigerResearch/tigerbot-13b-base-v2'
,
LoRATM
.
llama2
,
TemplateType
.
default_generation
)
@
register_model
(
CustomModelType
.
tigerbot_13b_chat
,
'TigerResearch/tigerbot-13b-chat-v4'
,
LoRATM
.
llama2
,
CustomTemplateType
.
tigerbot
)
def
get_tigerbot_model_tokenizer
(
model_dir
:
str
,
torch_dtype
:
Dtype
,
model_kwargs
:
Dict
[
str
,
Any
],
load_model
:
bool
=
True
,
**
kwargs
):
use_flash_attn
=
kwargs
.
pop
(
'use_flash_attn'
,
False
)
if
use_flash_attn
:
require_version
(
'transformers>=4.34'
)
logger
.
info
(
'Setting use_flash_attention_2: True'
)
model_kwargs
[
'use_flash_attention_2'
]
=
True
model_config
=
AutoConfig
.
from_pretrained
(
model_dir
,
trust_remote_code
=
True
)
model_config
.
pretraining_tp
=
1
model_config
.
torch_dtype
=
torch_dtype
logger
.
info
(
f
'model_config:
{
model_config
}
'
)
tokenizer
=
AutoTokenizer
.
from_pretrained
(
model_dir
,
trust_remote_code
=
True
)
model
=
None
if
load_model
:
model
=
AutoModelForCausalLM
.
from_pretrained
(
model_dir
,
config
=
model_config
,
torch_dtype
=
torch_dtype
,
trust_remote_code
=
True
,
**
model_kwargs
)
return
model
,
tokenizer
# Ref: https://github.com/TigerResearch/TigerBot/blob/main/infer.py
register_template
(
CustomTemplateType
.
tigerbot
,
Template
([
'{{SYSTEM}}'
],
[
'
\n\n
### Instruction:
\n
{{QUERY}}
\n\n
### Response:
\n
'
],
[],
[[
'eos_token_id'
]]))
def
_preprocess_stsb
(
dataset
:
HfDataset
)
->
HfDataset
:
prompt
=
"""Task: Based on the given two sentences, provide a similarity score between 0.0 and 5.0.
Sentence 1: {text1}
Sentence 2: {text2}
Similarity score: """
query
=
[]
response
=
[]
for
d
in
dataset
:
query
.
append
(
prompt
.
format
(
text1
=
d
[
'text1'
],
text2
=
d
[
'text2'
]))
response
.
append
(
f
"
{
d
[
'label'
]:.
1
f
}
"
)
return
HfDataset
.
from_dict
({
'query'
:
query
,
'response'
:
response
})
register_dataset
(
CustomDatasetName
.
stsb_en
,
'huangjintao/stsb'
,
None
,
_preprocess_stsb
,
get_dataset_from_repo
)
if
__name__
==
'__main__'
:
# The Shell script can view `examples/pytorch/llm/scripts/custom`.
# test dataset
train_dataset
,
val_dataset
=
get_dataset
([
CustomDatasetName
.
stsb_en
],
check_dataset_strategy
=
'warning'
)
print
(
f
'train_dataset:
{
train_dataset
}
'
)
print
(
f
'val_dataset:
{
val_dataset
}
'
)
# test model base
model
,
tokenizer
=
get_model_tokenizer
(
CustomModelType
.
tigerbot_13b
,
use_flash_attn
=
False
)
# test model chat
model
,
tokenizer
=
get_model_tokenizer
(
CustomModelType
.
tigerbot_13b_chat
,
use_flash_attn
=
False
)
# test template
template
=
get_template
(
CustomTemplateType
.
tigerbot
,
tokenizer
)
train_dataset
=
dataset_map
(
train_dataset
,
template
.
encode
)
print_example
(
train_dataset
[
0
],
tokenizer
)
swift-main/examples/pytorch/llm/eval_example/custom_ceval/default_dev.csv
0 → 100644
View file @
1bfbcff0
id,question,A,B,C,D,answer,explanation
1,要把膜蛋白脂完整地从膜上溶解下来,可以用____。,蛋白水解酶,透明质酸酶,去垢剂,糖苷水解酶,C,"1. 首先,我们需要知道如何将膜蛋白脂从膜上溶解下来。膜蛋白脂是由蛋白质和脂质组成的复合物,因此需要使用一种能够破坏脂质的物质来将其溶解。
2. 接着,我们分析选项:(A) 蛋白水解酶是一种能够水解蛋白质的酶,会破坏膜蛋白脂的结构;(B) 透明质酸酶是一种能够水解透明质酸的酶,与膜蛋白脂无关;(C) 去垢剂是一种能够破坏脂质的物质,可以将膜蛋白脂完整地从膜上溶解下来;(D) 糖苷水解酶是一种能够水解糖苷的酶,与膜蛋白脂无关。"
2,不连续聚丙烯酰胺凝胶电泳比一般电泳的分辨率高,是因为具有____。,浓缩效应,电荷效应,分子筛效应,黏度效应,A,"1. 浓缩效应是指由于凝胶孔径等的不连续性,样本物质被浓缩为一个狭窄的中间层,是不连续聚丙烯酰胺凝胶电泳分辨率高的主要原因。
2. 电荷效应和分子筛效应不是不连续聚丙烯酰胺凝胶电泳特有的效应;黏度效应与分辨率提高没有直接关系。"
swift-main/examples/pytorch/llm/eval_example/custom_ceval/default_val.csv
0 → 100644
View file @
1bfbcff0
id,question,A,B,C,D,answer,explanation
1,通常来说,组成动物蛋白质的氨基酸有____,4种,22种,20种,19种,C,1. 目前已知构成动物蛋白质的的氨基酸有20种。
2,血液内存在的下列物质中,不属于代谢终产物的是____。,尿素,尿酸,丙酮酸,二氧化碳,C,"1. 代谢终产物是指在生物体内代谢过程中产生的无法再被利用的物质,需要通过排泄等方式从体内排出。
2. 丙酮酸是糖类代谢的产物,可以被进一步代谢为能量或者合成其他物质,并非代谢终产物。"
swift-main/examples/pytorch/llm/eval_example/custom_config.json
0 → 100644
View file @
1bfbcff0
[
{
"name"
:
"custom_general_qa"
,
"pattern"
:
"general_qa"
,
"dataset"
:
"eval_example/custom_general_qa"
,
"subset_list"
:
[
"default"
]
},
{
"name"
:
"custom_ceval"
,
"pattern"
:
"ceval"
,
"dataset"
:
"eval_example/custom_ceval"
,
"subset_list"
:
[
"default"
]
}
]
swift-main/examples/pytorch/llm/eval_example/custom_general_qa/default.jsonl
0 → 100644
View file @
1bfbcff0
{"history": [], "query": "中国的首都是哪里?", "response": "中国的首都是北京"}
{"history": [], "query": "世界上最高的山是哪座山?", "response": "是珠穆朗玛峰"}
{"history": [], "query": "为什么北极见不到企鹅?", "response": "因为企鹅大多生活在南极"}
swift-main/examples/pytorch/llm/llm_dpo.py
0 → 100644
View file @
1bfbcff0
# Copyright (c) Alibaba, Inc. and its affiliates.
import
custom
from
swift.llm
import
dpo_main
if
__name__
==
'__main__'
:
output
=
dpo_main
()
swift-main/examples/pytorch/llm/llm_infer.py
0 → 100644
View file @
1bfbcff0
# Copyright (c) Alibaba, Inc. and its affiliates.
import
custom
from
swift.llm
import
infer_main
if
__name__
==
'__main__'
:
result
=
infer_main
()
swift-main/examples/pytorch/llm/llm_orpo.py
0 → 100644
View file @
1bfbcff0
# Copyright (c) Alibaba, Inc. and its affiliates.
import
custom
from
swift.llm
import
orpo_main
if
__name__
==
'__main__'
:
output
=
orpo_main
()
swift-main/examples/pytorch/llm/llm_sft.py
0 → 100644
View file @
1bfbcff0
# Copyright (c) Alibaba, Inc. and its affiliates.
import
custom
from
swift.llm
import
sft_main
if
__name__
==
'__main__'
:
output
=
sft_main
()
swift-main/examples/pytorch/llm/llm_simpo.py
0 → 100644
View file @
1bfbcff0
# Copyright (c) Alibaba, Inc. and its affiliates.
import
custom
from
swift.llm
import
simpo_main
if
__name__
==
'__main__'
:
output
=
simpo_main
()
swift-main/examples/pytorch/llm/rome_example/request.json
0 → 100644
View file @
1bfbcff0
[
{
"prompt"
:
"{} was the founder of"
,
"subject"
:
"Steve Jobs"
,
"target"
:
"Microsoft"
},
{
"prompt"
:
"{} is located in"
,
"subject"
:
"HangZhou"
,
"target"
:
"Africa"
}
]
swift-main/examples/pytorch/llm/rome_infer.py
0 → 100644
View file @
1bfbcff0
# Copyright (c) Alibaba, Inc. and its affiliates.
from
swift.llm
import
rome_main
if
__name__
==
'__main__'
:
rome_main
()
swift-main/examples/pytorch/llm/scripts/atom_7b_chat/lora/infer.sh
0 → 100644
View file @
1bfbcff0
# Experimental environment: 3090
CUDA_VISIBLE_DEVICES
=
0
\
swift infer
\
--ckpt_dir
"output/atom-7b-chat/vx-xxx/checkpoint-xxx"
\
--load_dataset_config
true
\
--max_new_tokens
2048
\
--temperature
0.1
\
--top_p
0.7
\
--repetition_penalty
1.
\
--do_sample
true
\
--merge_lora
false
\
swift-main/examples/pytorch/llm/scripts/atom_7b_chat/lora/sft.sh
0 → 100644
View file @
1bfbcff0
# Experimental environment: 3090,A10,V100...
# 20GB GPU memory
CUDA_VISIBLE_DEVICES
=
0
\
swift sft
\
--model_type
atom-7b-chat
\
--model_revision
master
\
--sft_type
lora
\
--tuner_backend
peft
\
--dtype
AUTO
\
--output_dir
output
\
--ddp_backend
nccl
\
--dataset
ms-bench
\
--num_train_epochs
3
\
--max_length
2048
\
--check_dataset_strategy
warning
\
--lora_rank
8
\
--lora_alpha
32
\
--lora_dropout_p
0.05
\
--lora_target_modules
DEFAULT
\
--gradient_checkpointing
true
\
--batch_size
1
\
--weight_decay
0.1
\
--learning_rate
1e-4
\
--gradient_accumulation_steps
16
\
--max_grad_norm
0.5
\
--warmup_ratio
0.03
\
--eval_steps
100
\
--save_steps
100
\
--save_total_limit
2
\
--logging_steps
10
\
Prev
1
…
10
11
12
13
14
15
16
17
18
…
36
Next
Write
Preview
Markdown
is supported
0%
Try again
or
attach a new file
.
Attach a file
Cancel
You are about to add
0
people
to the discussion. Proceed with caution.
Finish editing this message first!
Cancel
Please
register
or
sign in
to comment

{kind=link}
{kind=link}

{kind=link}

{kind=link}
