# GLM-4.1V
## 论文
[GLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning](https://arxiv.org/abs/2507.01006)
## 模型简介
GLM-4.1V-thinging旨在探索视觉语言模型推理能力的上限,通过引入“思考范式”并利用采样强化学习 RLCS(Reinforcement Learning with Curriculum Sampling)全面提升模型能力。在 100 亿参数的视觉语言模型中,其性能处于领先地位,在 18 项基准测试任务中与 720 亿参数的 Qwen-2.5-VL-72B 相当甚至更优。
与上一代的 CogVLM2 及 GLM-4V 系列模型相比,**GLM-4.1V-Thinking**有如下改进:
1. 系列中首个推理模型,不仅仅停留在数学领域,在多个子领域均达到世界前列的水平。
2. 支持**64k**上下长度。
3. 支持**任意长宽比**和高达**4k**的图像分辨率。
4. 提供支持**中英文双语**的开源模型版本。
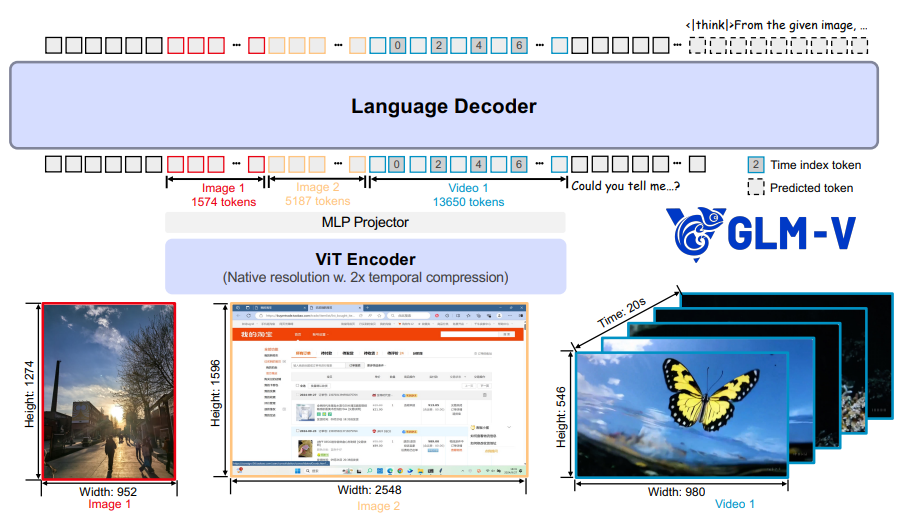
GLM-4.1V-Thinking能够将图像和视频以其原始的分辨率和宽高比进行识别。对于视频输入,会在每帧后面插入额外的时间索引标记,以增强模型的时间理解能力。GLM-4.1V-Thinking 有三部分组成:
1. 一个视觉 Transformer 编码器,用于处理和编码图像及视频;
2. 一个多层感知机投影器,用于将视觉特征与标记对齐;
3. 一个大型语言模型作为语言解码器,用于处理多模态标记并生成标记补全内容。
## 环境依赖
| 软件 | 版本 |
| :------: | :------: |
| DTK | 25.04.2 |
| python | 3.10.12 |
| torch | 2.5.1+das.opt1.dtk25042 |
| transformers | 4.53.2 |
| vllm | 0.11.0 |
推荐使用镜像:
- 挂载地址`-v`根据实际模型情况修改
```bash
docker run -it --shm-size 60g --network=host --name glm-41v --privileged --device=/dev/kfd --device=/dev/dri --device=/dev/mkfd --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -u root -v /path/your_code_data/:/path/your_code_data/ -v /opt/hyhal/:/opt/hyhal/:ro image.sourcefind.cn:5000/dcu/admin/base/custom:vllm-ubuntu22.04-dtk25.04.2-py3.10-minimax-m2 bash
```
更多镜像可前往[光源](https://sourcefind.cn/#/service-list)下载使用。
关于本项目DCU显卡所需的特殊深度学习库可从[光合](https://developer.sourcefind.cn/tool/)开发者社区下载安装。
## 数据集
[LLaMA-Factory](https://developer.sourcefind.cn/codes/OpenDAS/llama-factory)已经支持本模型的微调。以下是构建数据集的说明,这是一个使用了两张图片的数据集。你需要将数据集整理为`finetune.json`,然后根据llama-factory中的数据配置进行相关修改。
```json
[
{
"messages": [
{
"content": "Who are they?",
"role": "user"
},
{
"content": "\nUser ask me to observe the image and get the answer. I Know they are Kane and Gretzka from Bayern Munich.\nThey're Kane and Gretzka from Bayern Munich.",
"role": "assistant"
},
{
"content": "What are they doing?",
"role": "user"
},
{
"content": "\nI need to observe what this people are doing. Oh, They are celebrating on the soccer field.\nThey are celebrating on the soccer field.",
"role": "assistant"
}
],
"images": [
"mllm_demo_data/1.jpg",
"mllm_demo_data/2.jpg"
]
}
]
```
1. ` XXX ` 中的部分不会被存放为历史记录和微调。
2. `` 标签会被替换成图片信息。
## 训练
### Llama Factory 微调方法(推荐)
根据[LLaMA-Factory](https://developer.sourcefind.cn/codes/OpenDAS/llama-factory)仓库指引安装好llama-factory后,请检查下transformers版本,如果版本不等于4.53.2,需要重新安装`pip install transformers==4.53.2`
因为transformers版本与[LLaMA-Factory](https://developer.sourcefind.cn/codes/OpenDAS/llama-factory)版本不一致,启动训练前需要先增加环境变量来跳过版本检查,环境变量如下:
```
export DISABLE_VERSION_CHECK=1
```
> **Tips:**
> 单卡微调请注释掉yaml文件中的`deepspeed`参数
#### 全参微调
SFT训练脚本示例,参考`llama-factory/train_full`下对应yaml文件。
**参数修改**:
- **--model_name_or_path**: 修改为待训练模型地址,如 `/data/GLM-4.1V-9B-Thinking`
- **--dataset**: 微调训练集名称,可选数据集请参考 `llama-factory/data/dataset_info.json`
- **--template**: 将 default 修改为 `glm4v`
- **--output_dir**: 模型保存地址
其他参数如:`--learning_rate`、`--save_steps`可根据自身硬件及需求进行修改。
#### lora微调
SFT训练脚本示例,参考`llama-factory/train_lora`下对应yaml文件。
参数解释同[#全参微调](#全参微调)
## 推理
### transformers
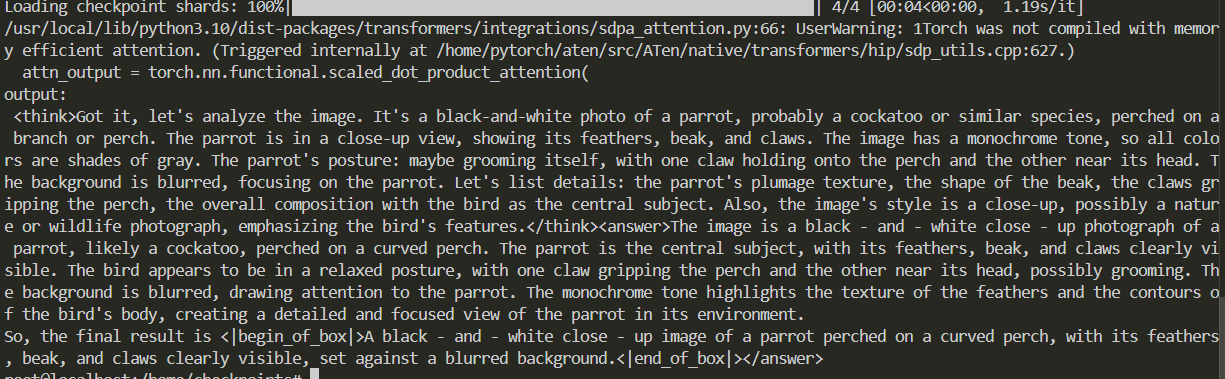
- `trans_infer_transformers.py`: 使用`transformers`库进行单次对话推理。
- `trans_infer_cli.py`: 使用`transformers`库作为推理后端的命令行交互脚本。你可以使用它进行连续对话。
```bash
# 单次推理启动命令如下
python inference/trans_infer_transformers.py
# 交互对话启动命令如下:
python inference/trans_infer_cli.py
```
### vllm
```bash
export HIP_VISIBLE_DEVICES=0
export ALLREDUCE_STREAM_WITH_COMPUTE=1
export HSA_FORCE_FINE_GRAIN_PCIE=1
## 启动服务
vllm serve THUDM/GLM-4.1V-9B-Thinking \
--limit-mm-per-prompt '{"image":32}' \
--allowed-local-media-path / \
--trust-remote-code \
--max-model-len 32768 \
--served-model-name glm-4.1v-thinking
## 访问
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "glm-4.1v-thinking",
"messages": [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {"url": "file:///home/glm-4.1v_pytorch/doc/Grayscale_8bits_palette_sample_image.png"}
},
{
"type": "text",
"text": "describe this image"
}
]
}],
"temperature": 0.7
}'
```
## 效果展示
### 精度
测试数据:[test data](https://developer.sourcefind.cn/codes/OpenDAS/llama-factory/-/blob/master/data/alpaca_en_demo.json),使用的加速卡:K100_AI。
模型:GLM-4.1V-9B-Thinking
| device | iters | train_loss |
| :------: | :------: | :------: |
| A800 | 375 | 0.5245 |
| K100_AI | 375 | 0.5264 |
## 预训练权重
| 模型名称 | 权重大小 | DCU型号 | 最低卡数需求 |下载地址|
|:-----:|:----------:|:----------:|:---------------------:|:----------:|
| GLM-4.1V-9B-Base | 9B | K100AI,BW1000 | 1 | [下载地址](https://huggingface.co/THUDM/GLM-4.1V-9B-Base) |
| GLM-4.1V-9B-Thinking | 9B | K100AI,BW1000 | 1 | [下载地址](https://huggingface.co/THUDM/GLM-4.1V-9B-Thinking) |
## 源码仓库及问题反馈
- https://developer.sourcefind.cn/codes/modelzoo/glm-4.1v_pytorch
## 参考资料
- https://github.com/THUDM/GLM-4.1V-Thinking