
First add
Showing
LICENSE
0 → 100644
README.md
0 → 100644
__init__.py
0 → 100644
ctc.py
0 → 100644
decode.py
0 → 100644
demo1.py
0 → 100644
demo2.py
0 → 100644
doc/funasr-v2.png
0 → 100644
{kind=link}
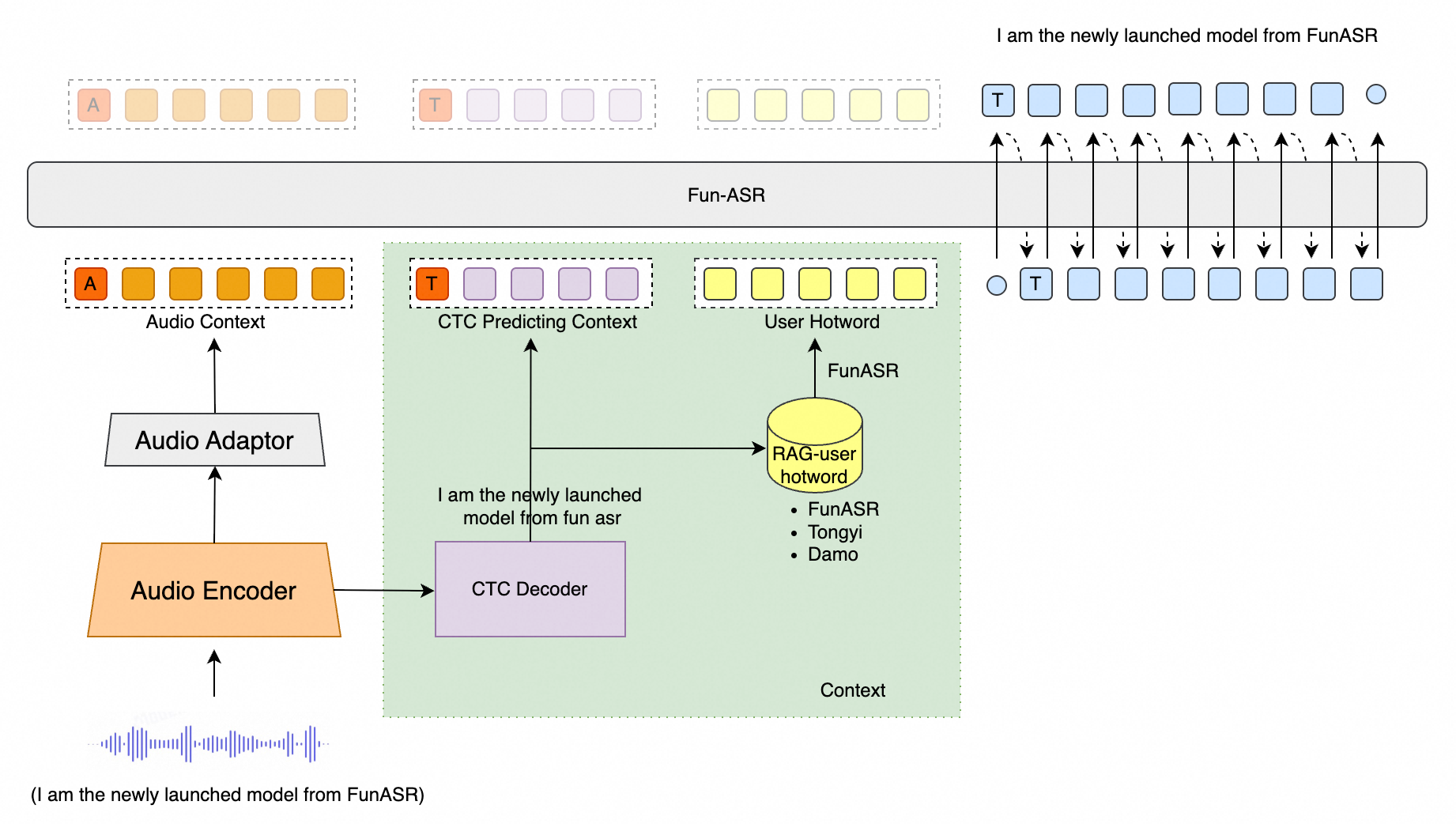
597 KB
doc/results.png
0 → 100644
{kind=link}

42.6 KB
icon.png
0 → 100644
{kind=link}
68.4 KB
model.properties
0 → 100644
model.py
0 → 100644
This diff is collapsed.
requirements.txt
0 → 100644
| transformers==4.51.0 | |||
| funasr>=1.3.0 | |||
| zhconv | |||
| whisper_normalizer | |||
| pyopenjtalk-plus | |||
| compute-wer |
tools/cn_tn.py
0 → 100644
This diff is collapsed.
tools/format5res.py
0 → 100644
tools/scp2jsonl.py
0 → 100644