
v1.0
Showing
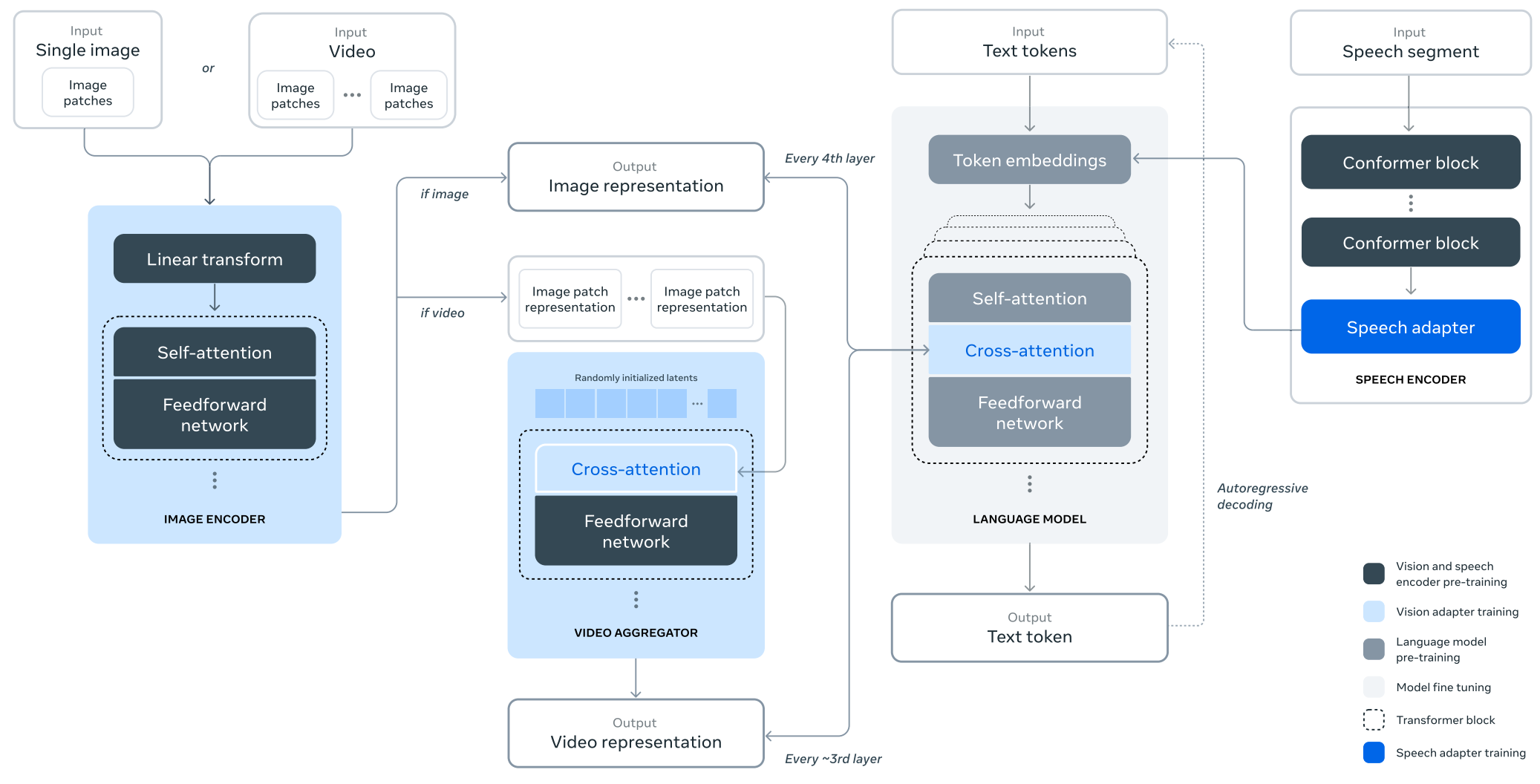
doc/structure.png
0 → 100644
{kind=link}
226 KB
model.properties
0 → 100644
pics/demo.jpeg
0 → 100644
{kind=link}

396 KB
pics/firefly_logo.png
0 → 100644
{kind=link}
251 KB
pics/gongzhonghao.jpeg
0 → 100644
{kind=link}

27.5 KB
pics/gongzhonghao.png
0 → 100644
{kind=link}
325 KB
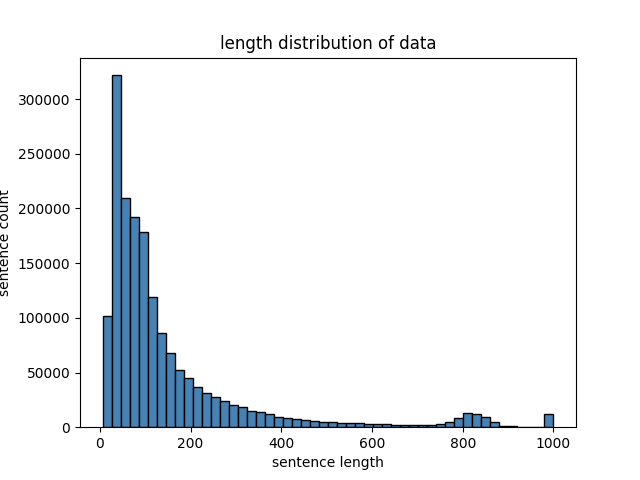
pics/len_distribution.png
0 → 100644
{kind=link}
18.4 KB
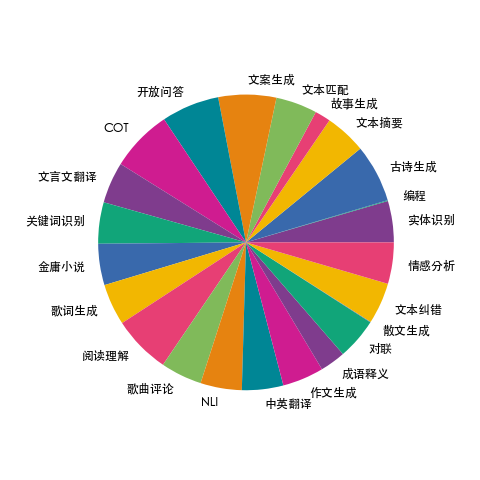
pics/task_distribution.png
0 → 100644
{kind=link}
42.2 KB
pics/train-loss-2b6-v2.png
0 → 100644
{kind=link}
77.5 KB
pics/train-loss-qlora.png
0 → 100644
{kind=link}
30.5 KB
pics/train-loss-ziya-13b.png
0 → 100644
{kind=link}
19.5 KB
pics/wechat-group.jpeg
0 → 100644
{kind=link}

162 KB
requirements.txt
0 → 100644
| # accelerate==0.21.0 | |||
| # transformers==4.37.2 | |||
| peft==0.10.0 | |||
| # bitsandbytes==0.39.0 | |||
| loguru==0.7.0 | |||
| numpy==1.26.4 | |||
| pandas==2.2.2 | |||
| # tqdm==4.62.3 | |||
| # deepspeed==0.9.5 | |||
| tensorboard | |||
| sentencepiece | |||
| transformers_stream_generator | |||
| tiktoken | |||
| einops | |||
| httpx | |||
| scipy | |||
| # torch==1.13.1 | |||
| mmengine | |||
| # xformers | |||
| astunparse==1.6.2 | |||
| # flash_attn | |||
| datasets | |||
| trl==0.7.11 | |||
| typing_extensions==4.9.0 | |||
| mpi4py |
script/chat/chat.py
0 → 100644
script/evaluate/evaluate.py
0 → 100644
script/http/post.py
0 → 100644
script/http/start_service.py
0 → 100644
script/merge_lora.py
0 → 100644
train.py
0 → 100644