
Initial commit
Showing
ds_zero3_work_dtk.sh
0 → 100644
eval/__init__.py
0 → 100644
eval/embedding_utils.py
0 → 100644
eval/evaluate.py
0 → 100644
eval/input_param.json
0 → 100644
eval/tokenizer.py
0 → 100644
finqwen_inference.py
0 → 100644
imgs/framework_1.jpg
0 → 100644
{kind=link}
222 KB
imgs/framework_2.jpg
0 → 100644
{kind=link}
131 KB
imgs/framework_3.jpg
0 → 100644
{kind=link}
111 KB
imgs/framework_4.jpg
0 → 100644
{kind=link}
150 KB
imgs/framework_5.jpg
0 → 100644
{kind=link}
128 KB
imgs/framework_6.jpg
0 → 100644
{kind=link}
55.3 KB
imgs/logo_fin_qwen.png
0 → 100644
{kind=link}
46.3 KB
imgs/result1.png
0 → 100644
{kind=link}
31.7 KB
imgs/transformer.jpg
0 → 100644
{kind=link}
87.9 KB
imgs/transformer.png
0 → 100644
{kind=link}
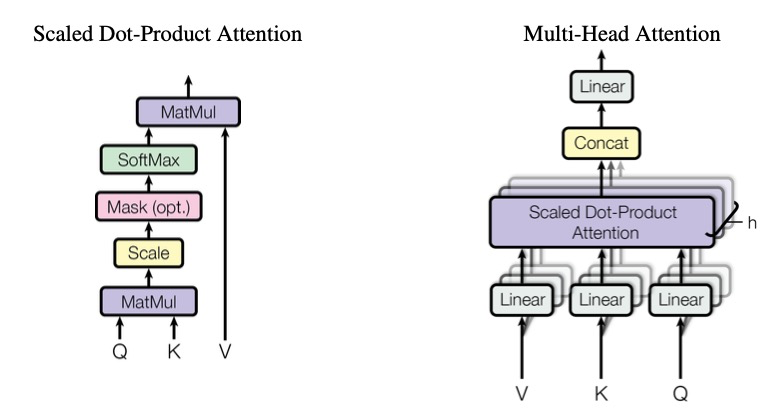
112 KB
model.properties
0 → 100644
requirements.txt
0 → 100644
| torch>=1.13.1 | |||
| transformers>=4.37.2 | |||
| datasets>=2.14.3 | |||
| accelerate>=0.21.0 | |||
| peft>=0.8.2 | |||
| trl>=0.7.6 | |||
| gradio>=3.38.0,<4.0.0 | |||
| scipy | |||
| einops | |||
| sentencepiece | |||
| protobuf | |||
| jieba | |||
| rouge-chinese | |||
| nltk | |||
| uvicorn | |||
| pydantic | |||
| fastapi | |||
| sse-starlette | |||
| matplotlib | |||
| transformers_stream_generator | |||
| modelscope |