# FinGPT-glm
## 论文
- [FinGPT: Open-Source Financial Large Language Models](https://arxiv.org/abs/2306.06031)
## 模型结构
GLM是一个开放的双语(中英)双向密集模型,使用通用语言模型(GLM)算法进行预训练。GLM是一种基于Transformer的语言模型,以自回归空白填充为训练目标。
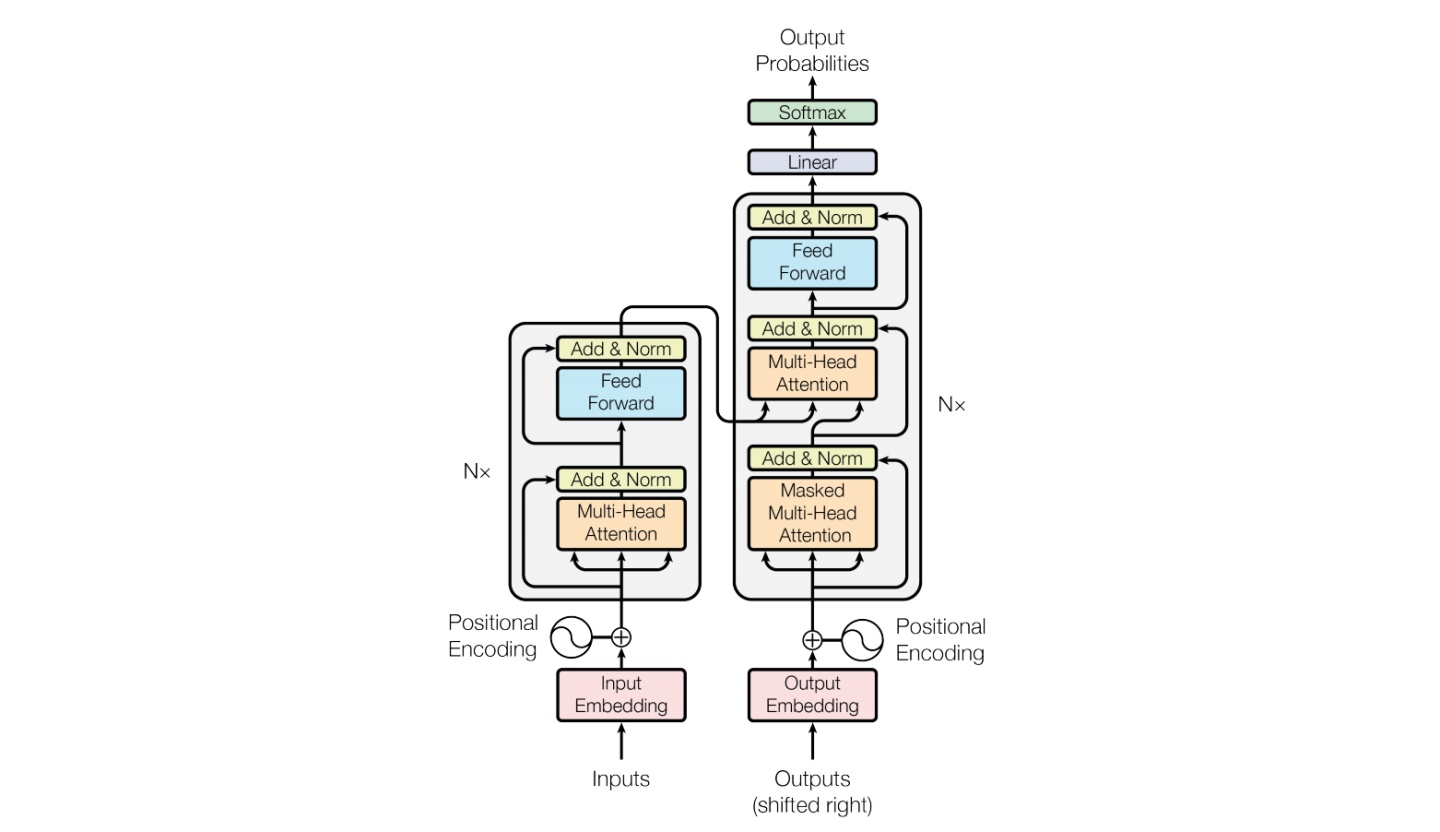
## 算法原理
模型基于 [General Language Model (GLM)](https://github.com/THUDM/GLM) 架构,GLM是一种基于Transformer的语言模型,以自回归空白填充为训练目标,同时具备自回归和自编码能力。
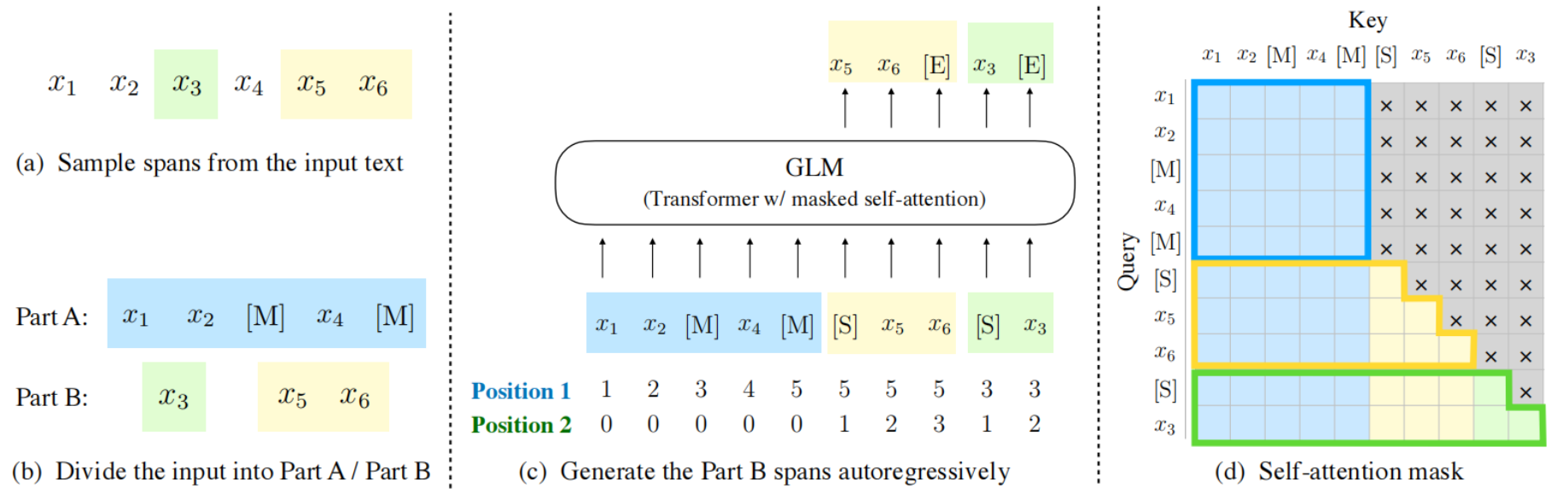
## 环境配置
### Docker(方法一)
```
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.1.0-ubuntu20.04-dtk24.04.1-py3.10
docker run -it -v /path/your_code_data/:/path/your_code_data/ -v /opt/hyhal/:/opt/hyhal/:ro --network=host --shm-size=64G --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name fingpt bash
cd /path/your_code_data/
pip install -r requirements.txt -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
```
### Dockerfile(方法二)
```
cd /path/your_code_data/docker
docker build --no-cache -t fingpt:latest .
docker run --shm-size=64G --name fingpt -v /opt/hyhal:/opt/hyhal:ro --network=host --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video -v /path/your_code_data/:/path/your_code_data/ -it fingpt bash
```
### Anaconda(方法三)
关于本项目DCU显卡所需的特殊深度学习库可从光合开发者社区下载安装:
https://developer.sourcefind.cn/tool/
```
DTK驱动:dtk24.04.1
python:python3.10
torch: 2.1.0
torchvision: 0.16.0
apex: 1.1.0
deepspped: 0.12.3
```
`Tips:以上dtk驱动、python、paddle等DCU相关工具版本需要严格一一对应`
其它非深度学习库参照requirements.txt安装:
```
cd fingpt-glm_pytorch
pip install -r requirements.txt -i http://mirrors.aliyun.com/pypi/simple
```
## 数据集
- [huggingface数据集下载地址] 网站提供12中不同任务的数据集用于训练
需要训练数据转换为必要的json格式,数据格式为:
```
{
"instruction": "描述原子的结构。",
"input": "",
"output": "原子是物质的基本单位,它由三种基本粒子组成:质子、中子和电子。质子和中子形成原子核,位于原子中心,核外的电子围绕着原子核运动。\n\n原子结构具有层次性。原子核中,质子带正电,中子不带电(中性)。原子核非常小且致密,占据了原子总质量的绝大部分。电子带负电,通常围绕核运动,形成若干层次,称为壳层或电子层。电子数量与质子数量相等,使原子呈电中性。\n\n电子在每个壳层中都呈规律分布,并且不同壳层所能容纳的电子数也不同。在最里面的壳层一般只能容纳2个电子,其次一层最多可容纳8个电子,再往外的壳层可容纳的电子数逐层递增。\n\n原子核主要受到两种相互作用力的影响:强力和电磁力。强力的作用范围非常小,主要限制在原子核内,具有极强的吸引作用,使核子(质子和中子)紧密结合在一起。电磁力的作用范围较大,主要通过核外的电子与原子核相互作用,发挥作用。\n\n这就是原子的基本结构。原子内部结构复杂多样,不同元素的原子核中质子、中子数量不同,核外电子排布分布也不同,形成了丰富多彩的化学世界。"
},
```
可以使用**data_process.py**进行数据处理
```
python data_process.py
```
训练数据目录结构如下,用于正常训练的完整数据集请按此目录结构进行制备:
```
── dataset
│ ├── dataset_new
│ ├── data-00000-of-00001.arrow
│ ├── dataset_info.json
│ └── state.json
│ └── twitter-financial-news-sentiment
│ ├── sent_dataset_meta.txt
│ ├── sent_train.csv
│ └── sent_valid.csv
│ └── dataset_new.json
│ └── dataset_new.jsonl
│
```
项目中已提供用于试验训练的迷你数据集,即脚本中的默认数据集路径[LLaMA-Factory-main/data](https://developer.sourcefind.cn/codes/modelzoo/fingpt-glm_pytorch/-/tree/main/LLaMA-Factory-main/data)
## 训练
根据实际情况在脚本中修改权重相关路径
### 单机多卡
```
bash multi_dcu_train.sh
```
### 单机单卡
```
bash single_dcu_train.sh
```
## 推理
**注:根据实际情况修改模型路径。**
```
python inference_FinGPT.py
```
## result
### 交互式推理
### 精度
测试数据:[twitter-financial-news-sentiment](../FinGPT/dataset/dataset_new.jsonl),使用的加速卡:V100S/K100。
根据测试结果情况填写表格:
| device | train_loss |eval_los |
| :------: | :------: | :------: |
| V100s | 0.371248 | 0.06542 |
| K100 | 0.371148 | 0.06536 |
## 应用场景
### 算法类别
`对话问答`
### 热点应用行业
`金融,教育,政府,科研`
## 预训练权重
可下载带有lora后缀的预训练权重,使用本人编写的**merge_model.py**文件进行模型合并。
- [huggingface预训练模型及数据集下载地址](https://huggingface.co/FinGPT)
## 源码仓库及问题反馈
- https://developer.sourcefind.cn/codes/modelzoo/fingpt-glm_pytorch
## 参考资料
- [https://github.com/AI4Finance-Foundation/FinGPT](https://github.com/AI4Finance-Foundation/FinGPT)
- [https://github.com/AI4Finance-Foundation/FinGPT/blob/master/FinGPT_Training_LoRA_with_ChatGLM2_6B_for_Beginners.ipynb](https://github.com/AI4Finance-Foundation/FinGPT/blob/master/FinGPT_Training_LoRA_with_ChatGLM2_6B_for_Beginners.ipynb)
