# falcon
## 论文
[The Falcon Series of Open Language Models](https://arxiv.org/pdf/2311.16867)
## 模型结构
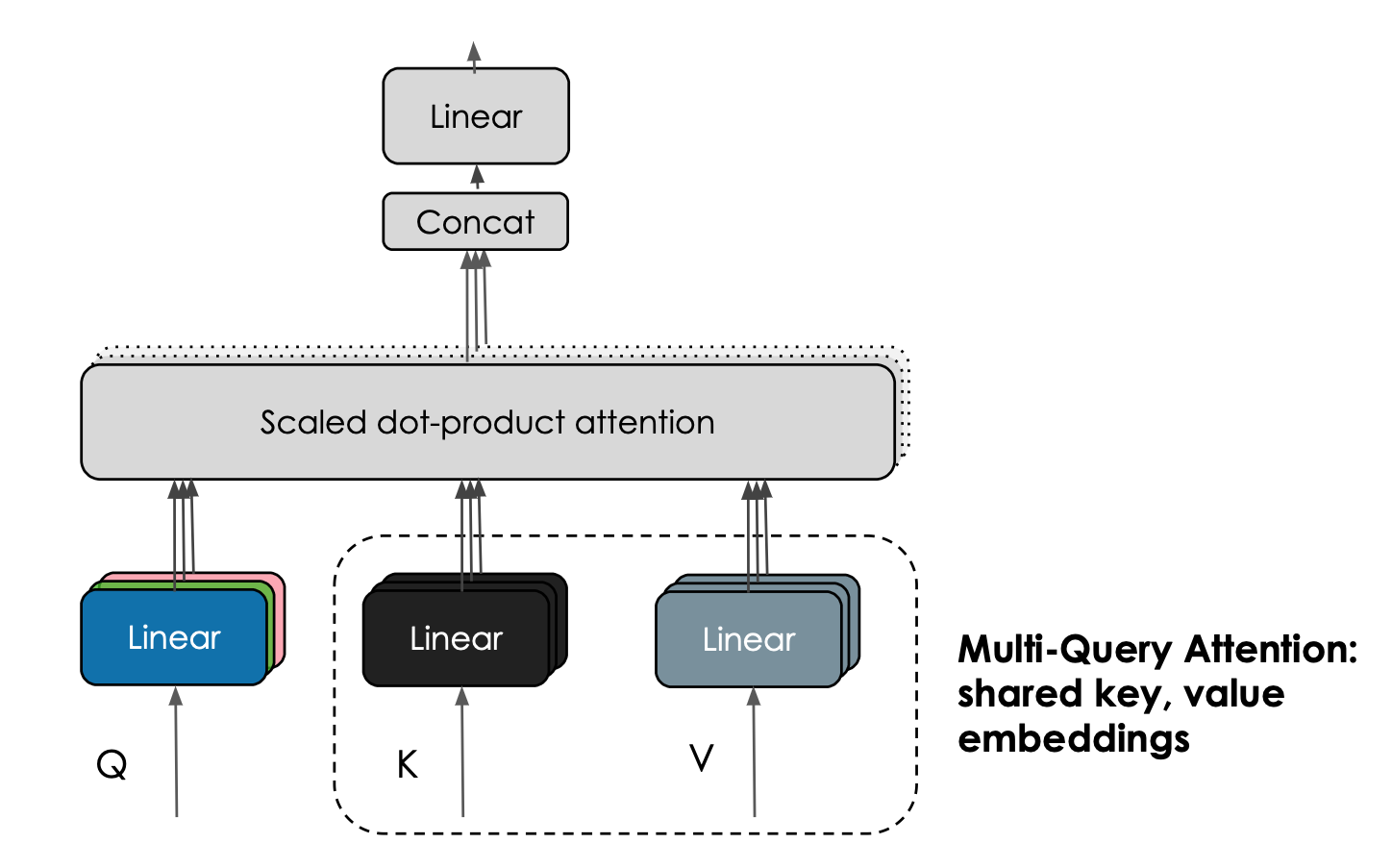
Falcon 模型的有趣的特性是其使用了 [**多查询注意力 (multiquery attention)**](https://arxiv.org/abs/1911.02150)。原始多头 (head) 注意力方案每个头都分别有一个查询 (query) 、键 (key) 以及值 (value),而多查询注意力方案改为在所有头上共享同一个键和值。
## 算法原理
Falcon-7B 和 Falcon-40B 分别基于 1.5 万亿和 1 万亿词元数据训练而得,其架构在设计时就充分考虑了推理优化。 **Falcon 模型质量较高的关键在于训练数据,其 80% 以上的训练数据来自于 [RefinedWeb](https://arxiv.org/abs/2306.01116) —— 一个新的基于 CommonCrawl 的网络数据集**。 TII 选择不去收集分散的精选数据,而是专注于扩展并提高 Web 数据的质量,通过大量的去重和严格过滤使所得语料库与其他精选的语料库质量相当。 在训练 Falcon 模型时,虽然仍然包含了一些精选数据 (例如来自 Reddit 的对话数据),但与 GPT-3 或 PaLM 等最先进的 LLM 相比,精选数据的使用量要少得多。 TII 公布了从 [RefinedWeb](https://huggingface.co/datasets/tiiuae/falcon-refinedweb) 中提取出的含有 6000 亿词元的数据集,以供社区在自己的 LLM 中使用!
## 环境配置
> Llama-Factory的安装方法请参考[README](https://developer.sourcefind.cn/codes/OpenDAS/llama-factory/-/blob/master/README.md)。
>
> -v 路径、docker_name和imageID根据实际情况修改。
### Docker(方法一)
```bash
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.1.0-ubuntu20.04-dtk24.04.2-py3.10
docker run -it -v /path/your_code_data/:/path/your_code_data/ -v /opt/hyhal/:/opt/hyhal/:ro --shm-size=80G --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name docker_name imageID bash
cd /your_code_path/falcon_pytorch
pip install -r requirements.txt
```
Tips:以上dtk驱动、python、torch、vllm等DCU相关工具版本需要严格一一对应。
### Dockerfile(方法二)
```bash
docker build -t falcon:latest .
docker run -it -v /path/your_code_data/:/path/your_code_data/ -v /opt/hyhal/:/opt/hyhal/:ro --shm-size=80G --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name docker_name imageID bash
cd /your_code_path/falcon_pytorch
pip install -r requirements.txt
```
### Anaconda(方法三)
关于本项目DCU显卡所需的特殊深度学习库可从[光合](https://developer.hpccube.com/tool/)开发者社区下载安装。
```
DTK驱动: dtk24.04.2
python: 3.10
torch: 2.1.0
llama-factory: 0.9.1.dev0
transformers: >=4.41.2
```
`Tips:以上dtk驱动、python、torch等DCU相关工具版本需要严格一一对应`
其它非深度学习库安装方式如下:
```bash
pip install -r requirements.txt
```
## 数据集
使用Llama-Factory内置数据集进行微调训练,或者根据自身需求,按照Llama-Factory需要的[格式](https://developer.sourcefind.cn/codes/OpenDAS/llama-factory/-/blob/v0.8.3/data/README_zh.md)进行数据准备。
## 训练
使用`LLaMA-Factory-0.9.1.dev0`微调
```bash
git clone http://developer.sourcefind.cn/codes/OpenDAS/llama-factory.git
cd llama-factory
pip install -e .[metrics]
# 卸载当前环境的flash_attn,都则会报错版本问题
pip uninstall flash_attn
```
### 单机单卡/单机多卡
1. 参考`falcon_pytorch/llama-factory-0.9.1.dev0/examples`下`train_full`、`train_lora`中提供的falcon样例,根据实际需求修改`model_name_or_path`、`dataset`、`learning_rate`、`cutoff_len`等参数,修改好的样例放入`llama-factory`框架的`examples`下的对应目录中即可。
```bash
# train_full 样例移动
cp llama-factory-0.9.1.dev0/examples/train_full/falcon_full_sft_ds3.yaml /path/of/llama-factory/examples/train_full/
# train_lora 样例移动
cp llama-factory-0.9.1.dev0/examples/train_lora/falcon_lora_sft.yaml /path/of/llama-factory/examples/train_lora/
```
2. 执行微调命令:
```bash
cd llama-factory
# 全参增量微调样例
# 卡数和卡号根据实际情况进行指定
HIP_VISIBLE_DEVICES=0,1,2,3 FORCE_TORCHRUN=1 llamafactory-cli train examples/train_full/falcon_full_sft_ds3.yaml
# Lora微调样例
HIP_VISIBLE_DEVICES=0,1 FORCE_TORCHRUN=1 llamafactory-cli train examples/train_lora/falcon_lora_sft.yaml
```
## 推理
使用`transformers`框架推理。
### 单机单卡
```bash
# 指定卡号
export HIP_VISIBLE_DEVICES=0,1
# 根据实际情况修改max_new_tokens参数
python inference.py --model_path /path/of/falcon --max_new_tokens xxx
```
## result
- 加速卡: K100_ai*4
- 模型:falcon-7b
### 精度
- 模型: falcon-7b
- 数据: alpaca_en_demo
- 训练模式: LoRA finetune
- 硬件:4卡,k100_ai/A800
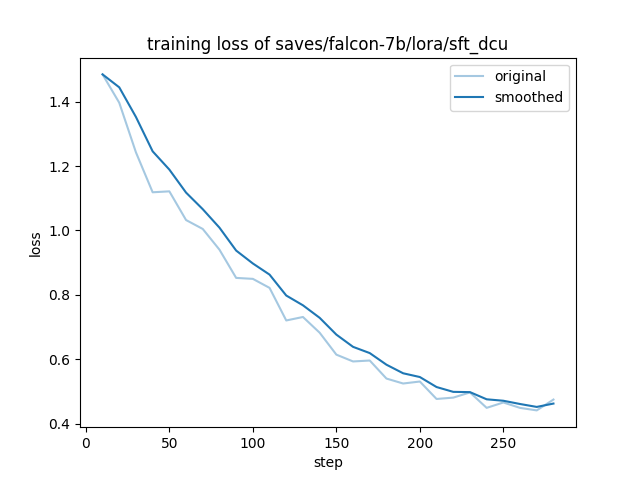
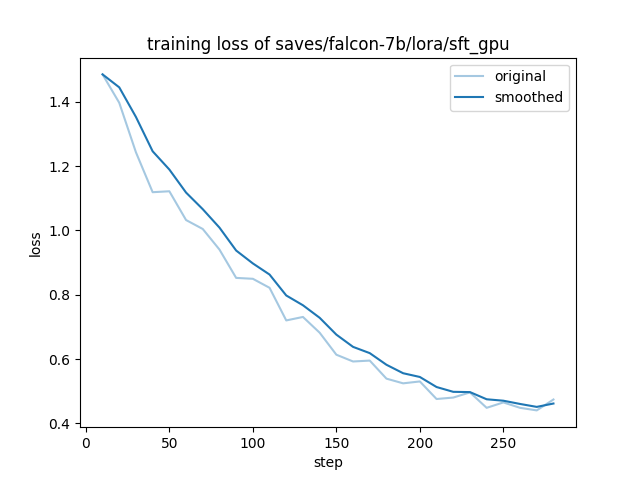
在DCU/NV上训练的收敛情况:
## 应用场景
### 算法类别
`对话问答`
### 热点应用行业
`科研,教育,政府,金融`
## 预训练权重
[AIModels / falcon-7b · 极狐GitLab](http://113.200.138.88:18080/aimodels/falcon-7b)
其他size的模型可在[SCNet](http://113.200.138.88:18080/aimodels/)进行搜索下载
## 源码仓库及问题反馈
- [yujq2 / falcon_pytorch · GitLab (sourcefind.cn)](https://developer.sourcefind.cn/codes/yujq2/falcon_pytorch)
## 参考资料
- https://github.com/hiyouga/LLaMA-Factory
- [tiiuae (Technology Innovation Institute) (huggingface.co)](https://huggingface.co/tiiuae)