# FaceChain
本项目的步骤适用于FaceChain中的数字形象生成,使用方法为网页启动微调、推理,算法论文中的其它生成效果以此类推,源算法由alibaba提供。
## 论文
`FaceChain: A Playground for Human-centric Artificial Intelligence Generated Content`
- https://arxiv.org/pdf/2308.14256.pdf
`High-resolution image ¨synthesis with latent diffusion models`
- https://arxiv.org/pdf/2112.10752.pdf
## 模型结构
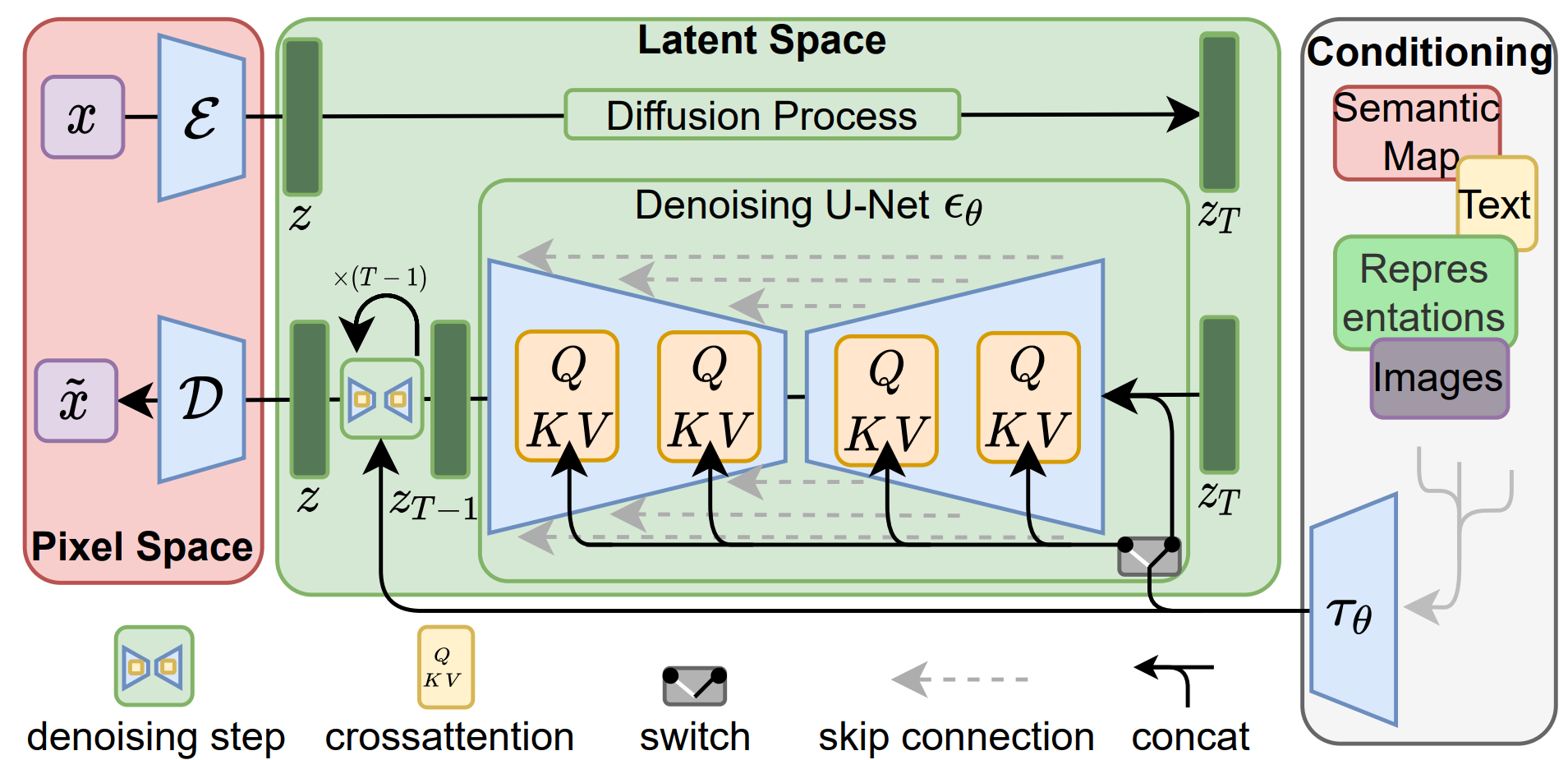
本项目的核心的算法为Stable Diffusion,算法处理过程:输入样本x,然后通过AE中的Encoder对x进行编码,输出为z,在diffusion model逐步加噪的过程中,都在z空间进行操作,最终输出z_{T},其符合均匀高斯分布,最右侧则是可以适配各类condition控制信息来指导反向生成(去噪)过程,其包括了text、image、标签、语义图,故该方案可以适配多类任务。
## 算法原理
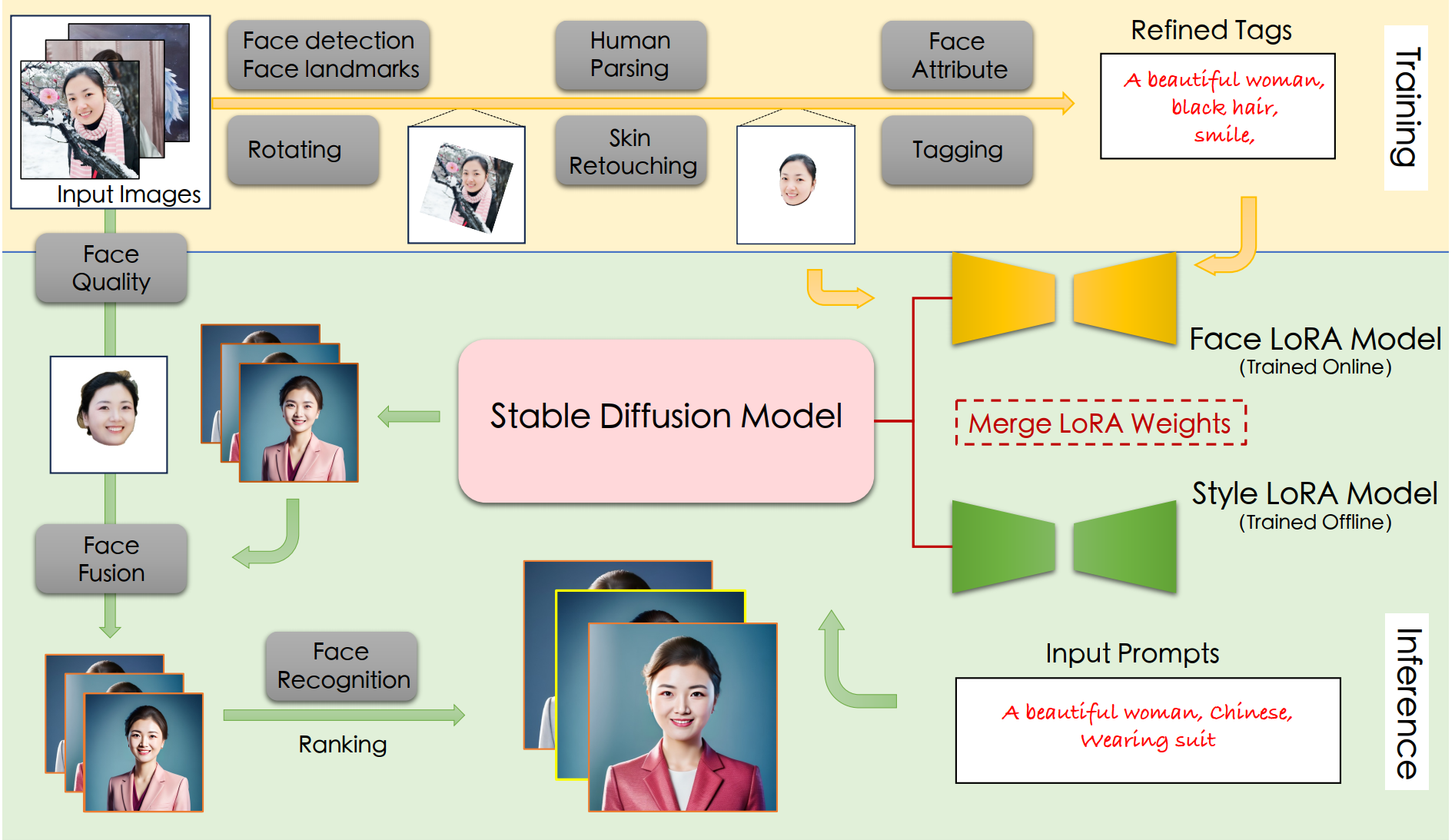
通常的文本图像生成算法生成的结果不能很好保留目标人物的人脸特征,本算法以Stable Diffusion为核心,基于一系列之前的sota算法(e.g., face detection, deep face embedding extraction, and facial attribute
recognition)组合了一种新的数字形象生成算法来解决这个问题。
## 环境配置
```
mv facechain_pytorch facechain # 去框架名后缀
算法所需权重微调、推理过程中会自动从ModelScope官网下载。
unzip resources.zip # 需要先解压resources提供写真模版
```
使用docker启动项目需要修改此脚本[`app.py`](./app.py)的最后一行,将127.0.0.1修改为0.0.0.0才能支持外部与容器通信,不用docker启动则使用默认地址127.0.0.1即可:
```
demo.queue(status_update_rate=1).launch(share=True, server_name="0.0.0.0")
```
### Docker(方法一)
```
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.1.0-centos7.6-dtk23.10-py38
# 为以上拉取的docker的镜像ID替换,本镜像为:ffa1f63239fc
docker run -it -p 7860:7860 -v $PWD/facechain:/home/facechain -v /opt/hyhal:/opt/hyhal --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name facechain bash
pip install -r requirements.txt
pip install mmcv_full-1.7.0+git36c62da.abi0.dtk2310.torch2.1-cp38-cp38-linux_x86_64.whl # dcu版mmcv,可从光合社区下载。
cp -r frpc_linux_amd64 /usr/local/lib/python3.8/site-packages/gradio/frpc_linux_amd64_v0.2
```
### Dockerfile(方法二)
```
cd facechain/docker
docker build --no-cache -t facechain:latest .
docker run -p 7860:7860 --name facechain -v /opt/hyhal:/opt/hyhal --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video -v $PWD/../../facechain:/home/facechain -it facechain bash
# 若遇到Dockerfile启动的方式安装环境需要长时间等待,可注释掉里面的pip安装,启动容器后再安装python库:pip install -r requirements.txt。
pip install mmcv_full-1.7.0+git36c62da.abi0.dtk2310.torch2.1-cp38-cp38-linux_x86_64.whl # dcu版mmcv,可从光合社区下载。
cp -r frpc_linux_amd64 /usr/local/lib/python3.8/site-packages/gradio/frpc_linux_amd64_v0.2
```
### Anaconda(方法三)
1、关于本项目DCU显卡所需的特殊深度学习库可从光合开发者社区下载安装:
- https://developer.sourcefind.cn/tool/
```
DTK驱动:dtk23.10
python:python3.8
torch:2.1.0
torchvision:0.16.0
triton==2.1.0
apex==0.1
mmcv-full==1.7.0
```
另外:`复制文件frpc_linux_amd64到python环境的目录lib/python3.8/site-packages/gradio/下,重命名为frpc_linux_amd64_v0.2。`
`Tips:以上dtk驱动、python、torch等DCU相关工具版本需要严格一一对应。`
2、其它非特殊库参照requirements.txt安装
```
pip install -r requirements.txt
```
## 数据集
本项目Style LoRA Model已经离线训练好,只需要提供人脸(>=1张)微调Face LoRA Model即可,训练数据通过网页上传。
训练数据目录结构如下:
```
facechain/
│ ├── xxx.png
│ ├── xxx.png
│ └── ...
```
`更多资料可参考源项目的README_origin.md`
## 训练
### 单机多卡
```
cd facechain
python app.py # 获取用于微调、推理的webui网页
ssh -L 7860:127.0.0.1:7860 xxx@ip -p 22 # xxx为账号,ip为跳板机地址,若服务器隔了跳板机,则需要在本地终端(如cmd)用此命令把网页推到本地才可在本地浏览器中正常查看。
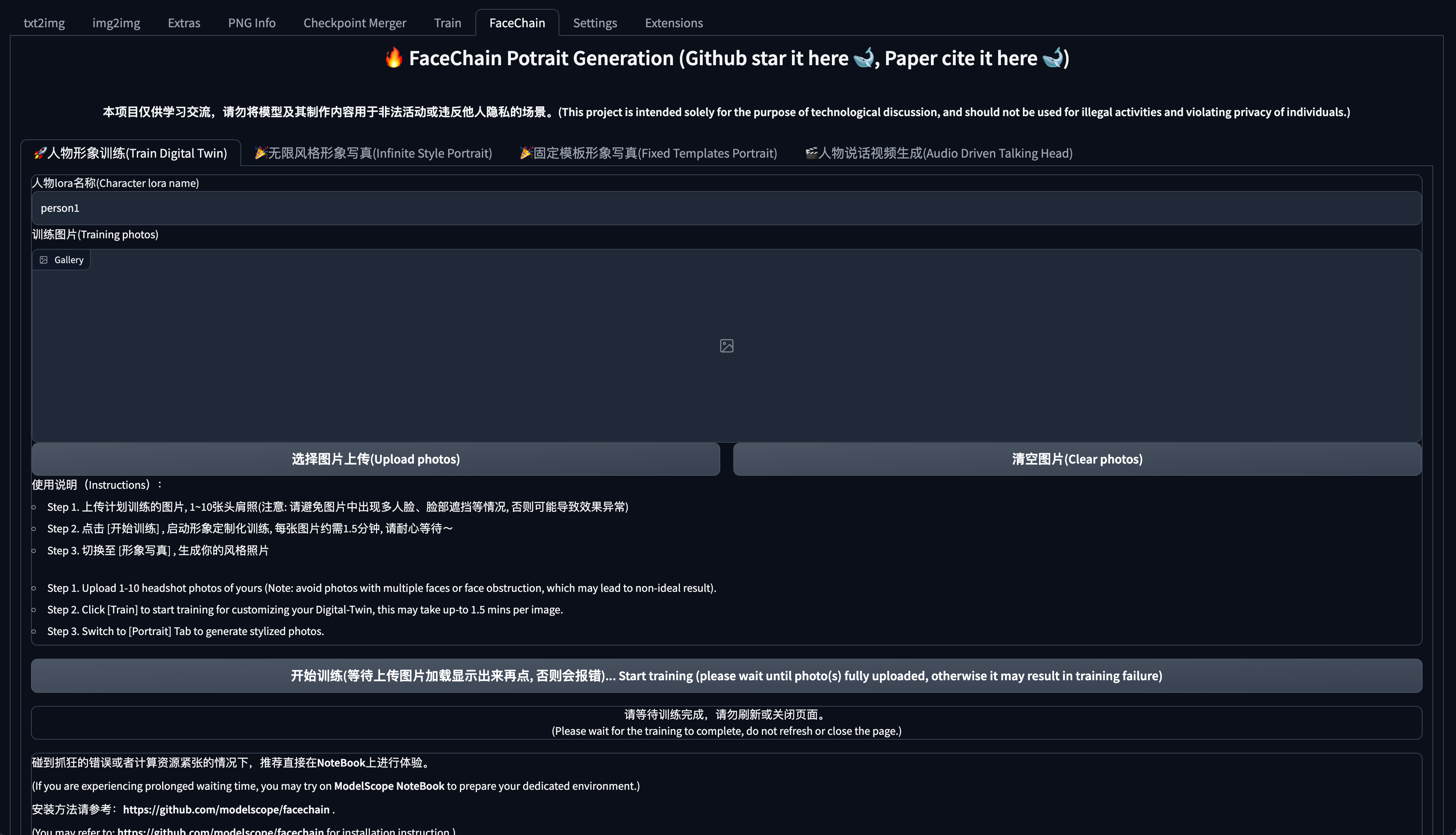
Step 1. 上传计划训练的图片, 1~10张头肩照(注意: 请避免图片中出现多人脸、脸部遮挡等情况, 否则可能导致效果异常);
Step 2. 点击 [开始训练] , 启动形象定制化训练, 每张图片约需1.5分钟;
```
webui网页如下:
## 推理
```
Step 3. 切换至 [形象写真] , 生成你的风格照片;
```
## result
输入左边图片,输出右边数字形象写真:
### 精度
测试数据:"./yangmi.jpg",推理框架:pytorch。
| device | loss |
|:---------:|:------:|
| DCU Z100L | 0.0896 |
| GPU V100S | 0.103 |
| GPU A800 | 0.104 |
## 应用场景
### 算法类别
`AIGC`
### 热点应用行业
`零售,广媒,金融,医疗,家居,医疗,环保`
## 源码仓库及问题反馈
- https://developer.sourcefind.cn/codes/modelzoo/facechain_pytorch
## 参考资料
- https://github.com/modelscope/facechain