You will need to install the following additional python dependencies. First go to the base folder of this project first: `cd /path/to/facechain/`, and then:
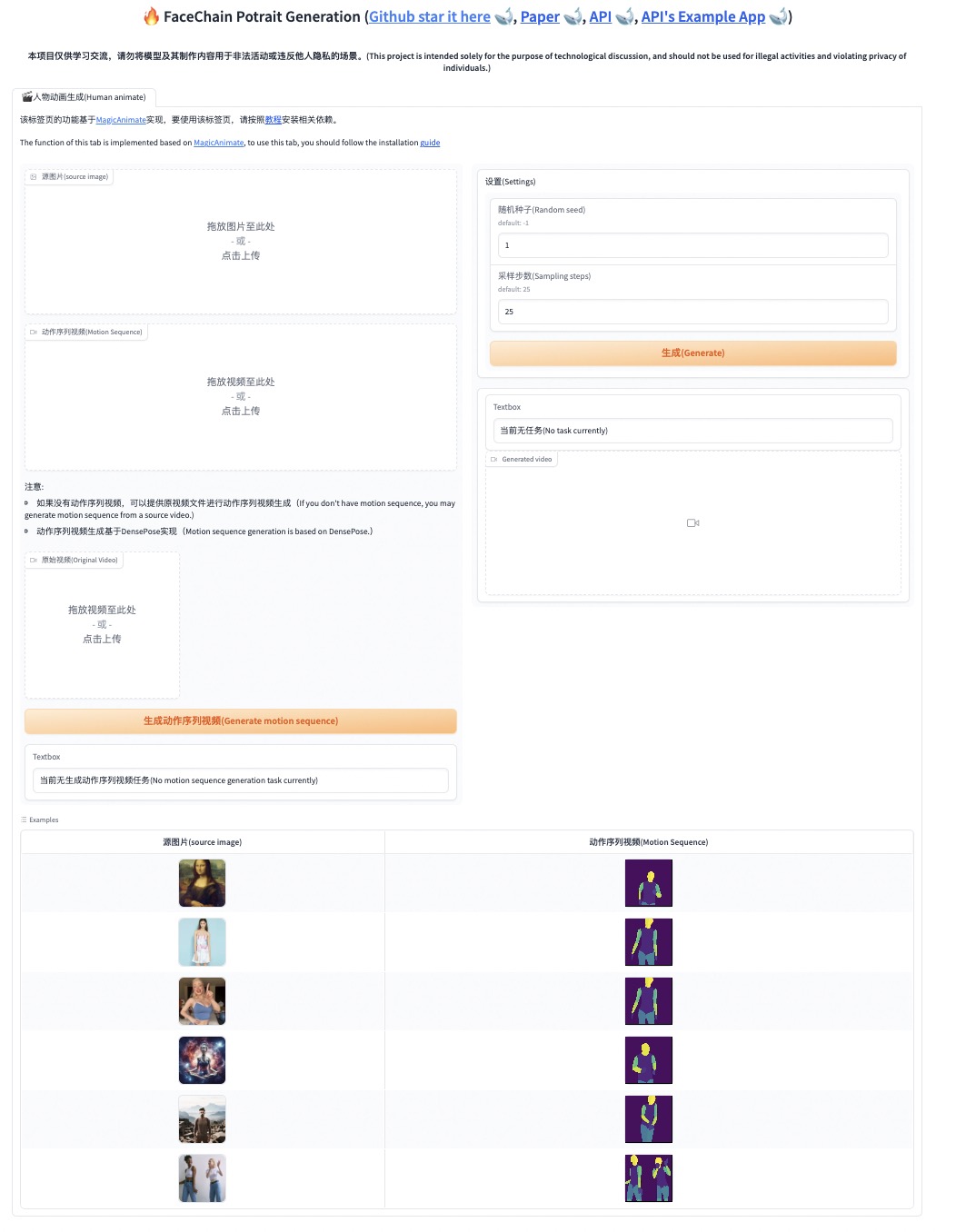
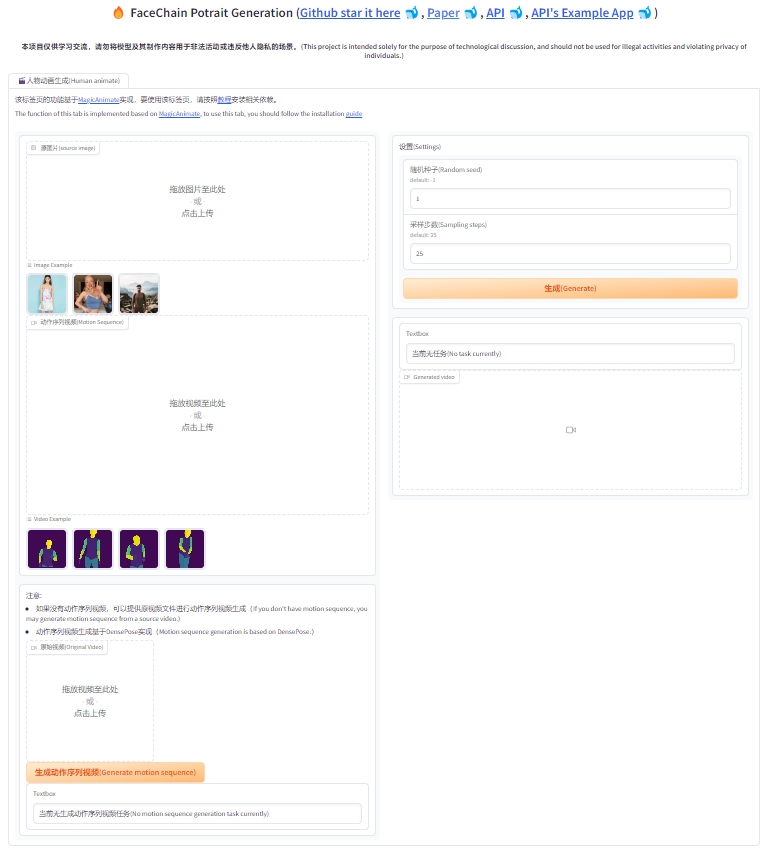
1. You should go to the base folder of this project first: `cd /path/to/facechain/`, and then run the command `python -m facechain_animate.app`.
2. You can upload a photo from your local computer or select one from previously generated images as the source image.
3. You can upload a motion sequence video from your local computer, which should be in mp4 format. Or you can upload an original video and generate motion sequence video of it.
4. In the right pane, set parameters.
5. Click the generate button and wait for the creation. The first use will download the model, please be patient. Subsequent generation usually takes about 5 minutes (based on the V100 graphics card).
6. Alternatively, you can run the command `python -m facechain_animate.magicanimate.pipelines.animation --config facechain_animate/magicanimate/configs/prompts/animation.yaml` directly in the command line. You can use `--videos_dir` and `--images_dir` to choose your motion sequence directory and source image directory for inference.
## Additional Information
1. Based on current test results, when users upload their own motion sequences, the generated videos are not particularly ideal (indicating insufficient generalization capability). The consistency is better when using motion sequences provided by the template.
2. Nevertheless, the consistency of the facial features and hand features still needs improvement. This will be an aspect that the project aims to enhance in the future, based on MagicAnimate.

{kind=link}
{kind=link}
{kind=link}

{kind=link}

{kind=link}

{kind=link}

{kind=link}

{kind=link}
