# F5-TTS
F5-TTS能根据文本内容自动生成带有情感的语音,无论是愤怒、喜悦还是悲伤,都能精准把握情感变化,难辨真伪。
## 论文
`F5-TTS: A Fairytaler that Fakes Fluent and Faithful Speech with Flow Matching`
- https://arxiv.org/pdf/2410.06885
## 模型结构
F5-TTS利用ConvNeXt V2提取文本特征、DiT(核心骨干网络)生成完整的梅尔频谱,利用预训练好的解码器把梅尔频谱解码成声音。
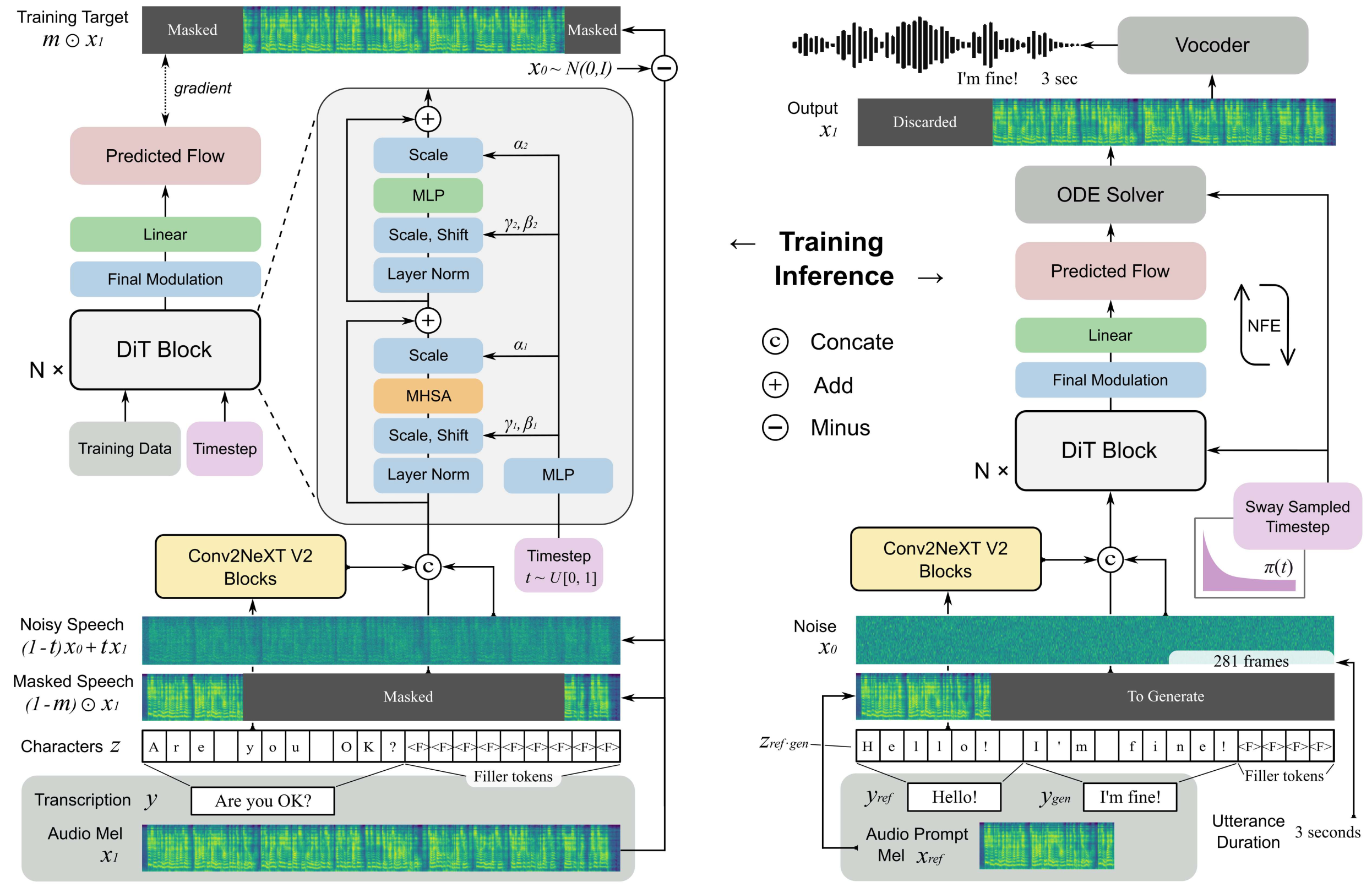
## 算法原理
从高斯噪声开始,通过扩散模型逐步生成目标音频特征,最终输出为梅尔频谱,后续通过声码器将其转换为音频波形,DiT 的并行化能力为 TTS 提供了显著的加速效果。

## 环境配置
```
mv f5-tts_pytorch F5-TTS # 去框架名后缀
```
### Docker(方法一)
```
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.3.0-ubuntu22.04-dtk24.04.2-py3.10
# 为以上拉取的docker的镜像ID替换,本镜像为:83714c19d308
docker run -it --shm-size=64G -v $PWD/F5-TTS:/home/F5-TTS -v /opt/hyhal:/opt/hyhal:ro --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name f5tts bash
cd /home/F5-TTS
pip install -e . # f5-tts==0.0.0
# 安装ffmpeg
apt update
apt-get install ffmpeg
# 解决gradio获取外网可访问的URL
cp -r frpc_linux_amd64 /usr/local/lib/python3.10/site-packages/gradio/frpc_linux_amd64_v0.2
chmod +x /usr/local/lib/python3.10/site-packages/gradio/frpc_linux_amd64_v0.2
```
### Dockerfile(方法二)
```
cd /home/F5-TTS/docker
docker build --no-cache -t f5tts:latest .
docker run --shm-size=64G --name f5tts -v /opt/hyhal:/opt/hyhal:ro --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video -v $PWD/../../F5-TTS:/home/F5-TTS -it f5tts bash
# 若遇到Dockerfile启动的方式安装环境需要长时间等待,可注释掉里面的pip安装,启动容器后再安装python库:pip install -r requirements.txt。
cd /home/F5-TTS
pip install -e . # f5-tts==0.0.0
# 安装ffmpeg
apt update
apt-get install ffmpeg
# 解决gradio获取外网可访问的URL
cp -r frpc_linux_amd64 /usr/local/lib/python3.10/site-packages/gradio/frpc_linux_amd64_v0.2
chmod +x /usr/local/lib/python3.10/site-packages/gradio/frpc_linux_amd64_v0.2
```
### Anaconda(方法三)
1、关于本项目DCU显卡所需的特殊深度学习库可从光合开发者社区下载安装:
- https://developer.sourcefind.cn/tool/
```
DTK驱动:dtk24.04.2
python:python3.10
torch:2.3.0
torchvision:0.18.1
torchaudio:2.1.2
triton:2.1.0
flash-attn:2.0.4
deepspeed:0.14.2
apex:1.3.0
xformers:0.0.25
```
`Tips:以上dtk驱动、python、torch等DCU相关工具版本需要严格一一对应。`
2、其它非特殊库参照requirements.txt安装
```
cd /home/F5-TTS
pip install -e . # f5-tts==0.0.0
# 安装ffmpeg
apt update
apt-get install ffmpeg
# 解决gradio获取外网可访问的URL
cp -r frpc_linux_amd64 /usr/local/lib/python3.10/site-packages/gradio/frpc_linux_amd64_v0.2
chmod +x /usr/local/lib/python3.10/site-packages/gradio/frpc_linux_amd64_v0.2
```
## 数据集
1、公开数据集(部分数据需要从开源官网申请账号获取):`Emilia_Dataset`、`WenetSpeech4TTS`
2、自定义数据集(参照源github issue中作者提供的制作方式进行制作):`custom dataset`
本文的使用说明仅提供推理步骤,若读者对音频数据集的制作感兴趣,可研究源项目的训练与微调说明文档[`src/f5_tts/train/README.md`](./src/f5_tts/train/README.md)。
## 训练
`暂无,敬请期待未来开放。`
参考源项目的训练与微调说明文档[`src/f5_tts/train/README.md`](./src/f5_tts/train/README.md)。
## 推理
```
# 方法一:终端命令推理
sh infer.sh
# 方法二:gradio网页推理
f5-tts_infer-gradio --share #可生成带live关键字的外网可访问url,实测gradio的生成效果听起来比终端生成效果好听一些。
```
更多资料可参考源项目的[`README_origin`](./README_origin.md)
## result
以终端命令推理示例:
`输入: `
```
ref_audio: "input.wav"
ref_text: "The content, subtitle or transcription of reference audio."
gen_text: "Some text you want TTS model generate for you."
```
`输出:`
```
tests/infer_cli_out.wav
```
### 精度
DCU与GPU精度一致,推理框架:pytorch。
## 应用场景
### 算法类别
`语音合成`
### 热点应用行业
`金融,电商,教育,制造,医疗,能源`
## 预训练权重
Hugging Face下载地址为:[SWivid/F5-TTS](https://huggingface.co/SWivid/F5-TTS/tree/main/F5TTS_Base) 、[SWivid/E2-TTS](https://huggingface.co/SWivid/E2-TTS/tree/main/E2TTS_Base)、[charactr/vocos-mel-24khz](https://huggingface.co/charactr/vocos-mel-24khz)、[openai/whisper-large-v3-turbo](https://huggingface.co/openai/whisper-large-v3-turbo)、[Qwen/Qwen2.5-3B-Instruct](https://huggingface.co/Qwen/Qwen2.5-3B-Instruct)。
本README中,推理所需预训练权重的完整目录结构如下:
```
/home/F5-TTS
├── SWivid/F5-TTS/F5TTS_Base
├── SWivid/E2-TTS/E2TTS_Base
├── charactr/vocos-mel-24khz
├── openai/whisper-large-v3-turbo
├── Qwen/Qwen2.5-3B-Instruct
...
```
## 源码仓库及问题反馈
- http://developer.sourcefind.cn/codes/modelzoo/f5-tts_pytorch.git
## 参考资料
- https://github.com/SWivid/F5-TTS.git