# EfficientConformer_pytorch
## 论文
Efficient Conformer: Progressive Downsampling and Grouped Attention for Automatic Speech Recognition
- https://arxiv.org/abs/2109.01163
## 模型结构
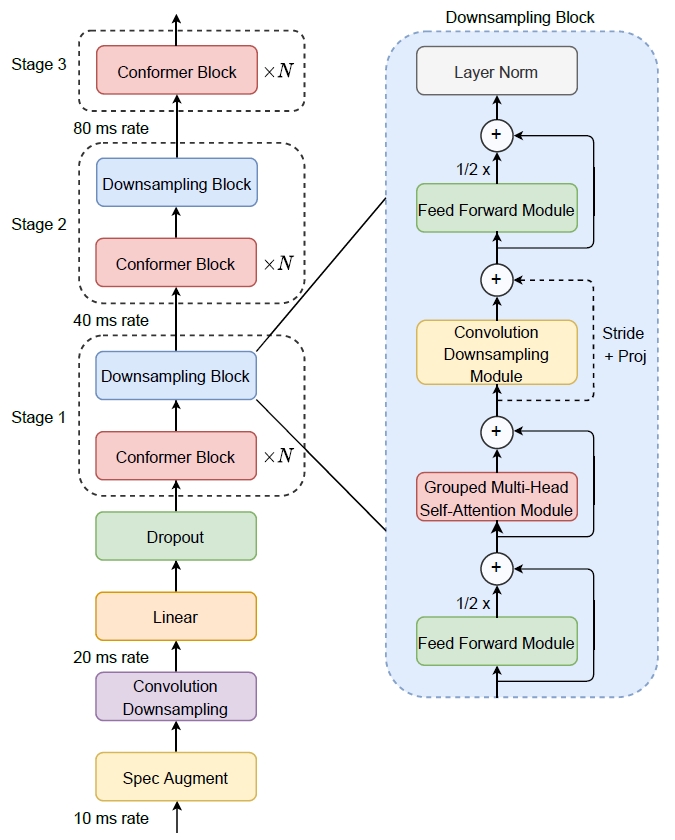
Efficient Conformer 是在Conformer的基础上提出的,其目的是在有限的计算预算下降低Conformer体系结构的复杂性,从而得到一种更为有效的体系结构。模型结构如图所示:
## 算法原理
模型在Conformer的基础上,将渐进式下采样引入到Conformer的编码器中,并提出了一种名为分组注意力的新型注意力机制,使得序列长度为n,特征维度为d,分组数为g的情况下将复杂度从 $O(n^2d)$ 降低到 $O(n^2d/g)$ 。其中分组注意力的计算方式如图所示:

## 环境配置
### Dcoker(方法一)
此处提供[光源](https://sourcefind.cn/#main-page)拉取镜像的地址与使用步骤:
```sh
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.1.0-ubuntu20.04-dtk24.04.1-py3.8
docker run -it -v /path/your_code_data/:/path/your_code_data/ -v /opt/hyhal:/opt/hyhal:ro --shm-size=32G --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name docker_name imageID bash
pip install ctcdecode
pip install warp-rnnt===0.5.0
```
### Dockerfile(方法二)
此处提供Dockerfile的使用方法:
```shell
cd ./docker
docker build --no-cache -t EfficientConformer:latest
docker run -it -v /path/your_code_data/:/path/your_code_data/ -v /opt/hyhal:/opt/hyhal:ro --shm-size=32G --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name docker_name imageID bash
```
### Anaconda(方法三)
关于本项目DCU显卡所需的特殊深度学习库可从光合开发者社区下载安装: https://developer.hpccube.com/tool/
```
DTK软件栈:dtk24,04,1
Python:3.8
touch:2.1.0
```
Tips:以上dtk软件栈、python、torch等DCU相关工具版本需要严格一一对应
## 数据集
官方代码在模型的训练和测试中使用的是LibriSpeech数据集。
- SCNet快速下载链接:
- [LibriSpeech_asr数据集下载](http://113.200.138.88:18080/aidatasets/librispeech_asr_dummy)
- 官方下载链接:
- [LibriSpeech_asr数据集官方下载](https://www.openslr.org/12)
librisspeech是大约1000小时的16kHz英语阅读演讲语料库,数据来源于LibriVox项目的有声读物,并经过仔细分割和整理,其中的音频文件以flac格式存储,语音对应的文本转炉内容以txt格式存储。
数据集的目录结构如下:
```
LibriSpeech
├── train-clean-100
│ ├── 19
│ │ ├── 19-198
│ │ │ ├── 19-198-0000.flac
│ │ │ ├── 19-198-0001.flac
│ │ │ ├── 19-198-0002.flac
│ │ │ ├── 19-198-0003.flac
│ │ │ ├── ...
│ │ │ ├── 19-198.trans.txt
│ │ └── ...
│ └── ...
├── train-clean-360
├── train-other-500
├── dev-clean
├── dev-other
├── test-clean
└── test-othe
```
## 训练
可以通过main.py的config_file参数提供一个配置文件来运行一个实验。训练checkpoint和日志将保存在配置文件中指定的文件夹中。另外,prepare_dataset和create_tokenizer参数可能需要用于第一次实验。
```shell
python main.py --config_file configs/config_file.json
```
### 监控训练
```
tensorboard --logdir callback_path
```
## 测试
可以通过选择验证/测试模式,并通过使用initial_epoch参数提供要加载的epoch或者checkpoint的名称来评估模型。gready参数用于指定是使用gredy搜索还是波束搜索解码进行求值。
## main.py 全部设置
```
-c / --config_file type=str default="configs/EfficientConformerCTCSmall.json" help="Json configuration file containing model hyperparameters"
-m / --mode type=str default="training" help="Mode : training, validation-clean, test-clean, eval_time-dev-clean, ..."
-d / --distributed action="store_true" help="Distributed data parallelization"
-i / --initial_epoch type=str default=None help="Load model from checkpoint"
--initial_epoch_lm type=str default=None help="Load language model from checkpoint"
--initial_epoch_encoder type=str default=None help="Load model encoder from encoder checkpoint"
-p / --prepare_dataset action="store_true" help="Prepare dataset before training"
-j / --num_workers type=int default=8 help="Number of data loading workers"
--create_tokenizer action="store_true" help="Create model tokenizer"
--batch_size_eval type=int default=8 help="Evaluation batch size"
--verbose_val action="store_true" help="Evaluation verbose"
--val_steps type=int default=None help="Number of validation steps"
--steps_per_epoch type=int default=None help="Number of steps per epoch"
--world_size type=int default=torch.cuda.device_count() help="Number of available GPUs"
--cpu action="store_true" help="Load model on cpu"
--show_dict action="store_true" help="Show model dict summary"
--swa action="store_true" help="Stochastic weight averaging"
--swa_epochs nargs="+" default=None help="Start epoch / end epoch for swa"
--swa_epochs_list nargs="+" default=None help="List of checkpoints epochs for swa"
--swa_type type=str default="equal" help="Stochastic weight averaging type (equal/exp)"
--parallel action="store_true" help="Parallelize model using data parallelization"
--rnnt_max_consec_dec_steps type=int default=None help="Number of maximum consecutive transducer decoder steps during inference"
--eval_loss action="store_true" help="Compute evaluation loss during evaluation"
--gready action="store_true" help="Proceed to a gready search evaluation"
--saving_period type=int default=1 help="Model saving every 'n' epochs"
--val_period type=int default=1 help="Model validation every 'n' epochs"
--profiler action="store_true" help="Enable eval time profiler"
```
## 应用场景
### 算法分类
语音识别
### 热点应用行业
语音识别、教育、医疗
## 源码仓库及问题反馈
https://developer.hpccube.com/codes/modelzoo/efficientconformer_pytorch
## 参考资料
https://github.com/burchim/EfficientConformer