
Efficient Conformer
parents
Showing
functions.py
0 → 100644
main.py
0 → 100644
media/EfficientConformer.jpg
0 → 100644
{kind=link}
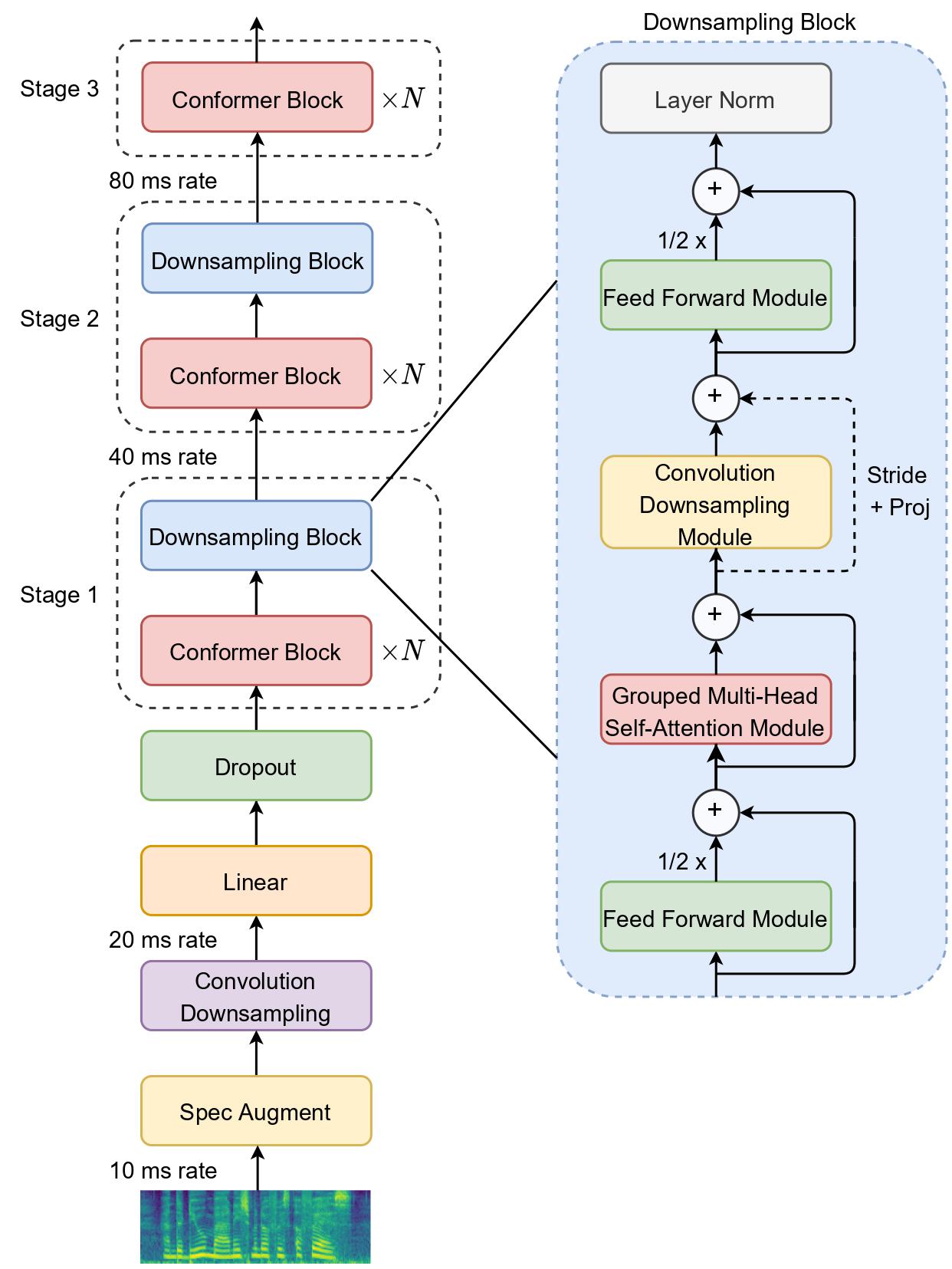
165 KB
media/logs.jpg
0 → 100644
{kind=link}
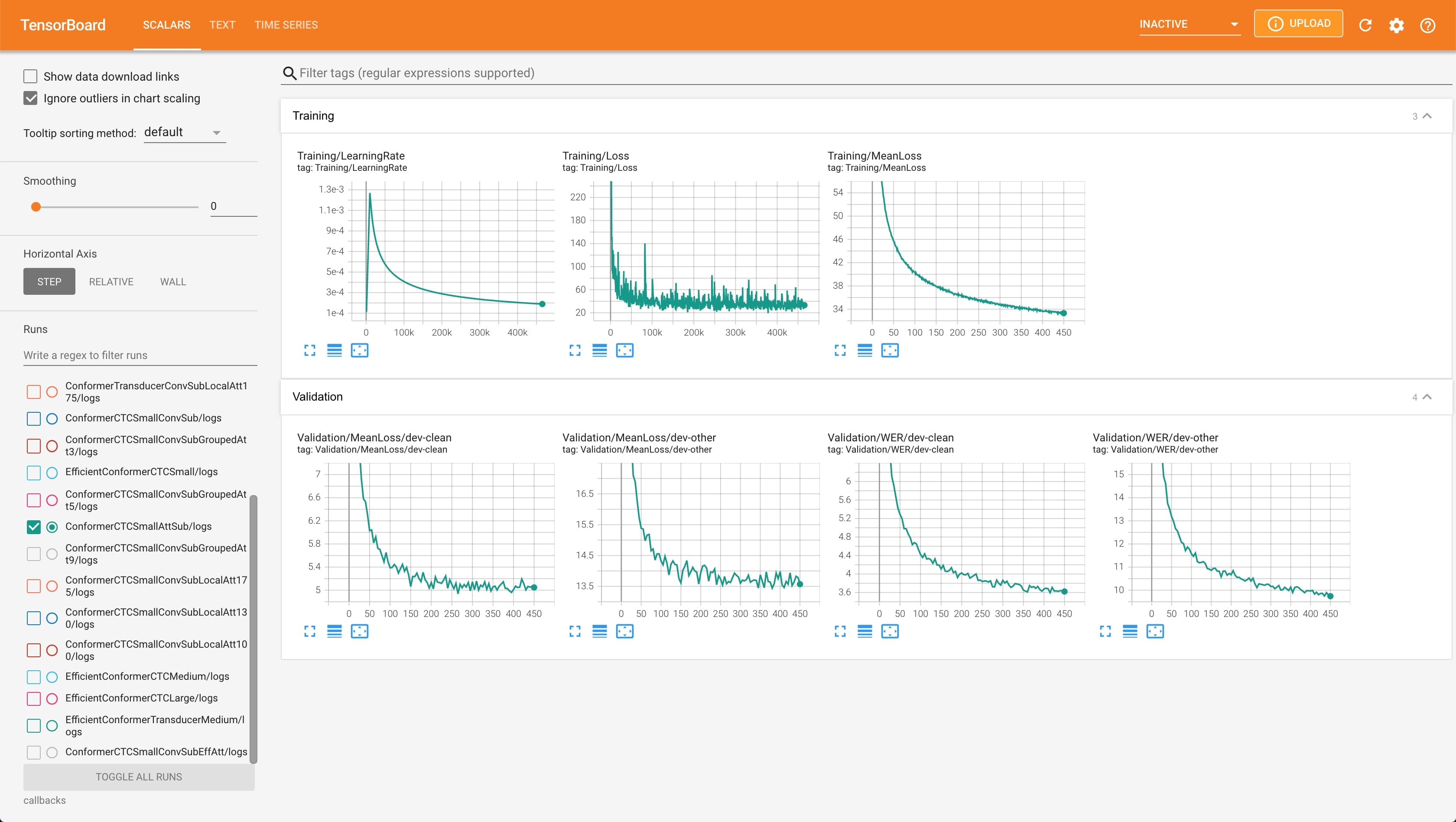
346 KB
models/__init__.py
0 → 100644
models/activations.py
0 → 100644
models/attentions.py
0 → 100644
models/blocks.py
0 → 100644
models/decoders.py
0 → 100644
models/encoders.py
0 → 100644
models/joint_networks.py
0 → 100644
models/layers.py
0 → 100644
models/lm.py
0 → 100644
models/losses.py
0 → 100644
models/model.py
0 → 100644
models/model_ctc.py
0 → 100644
models/model_s2s.py
0 → 100644
models/modules.py
0 → 100644
models/schedules.py
0 → 100644
models/transducer.py
0 → 100644