
Initial commit
Showing
images/example_consult.gif
0 → 100644
{kind=link}
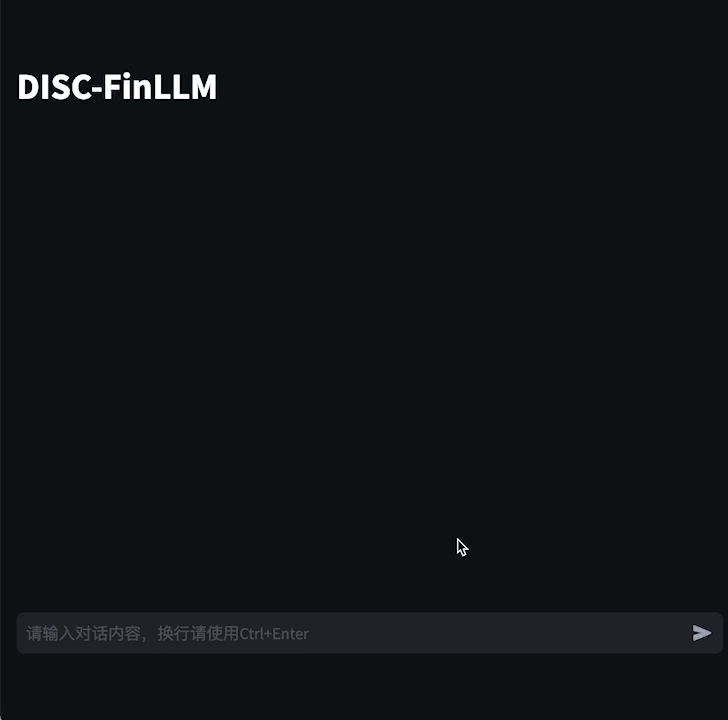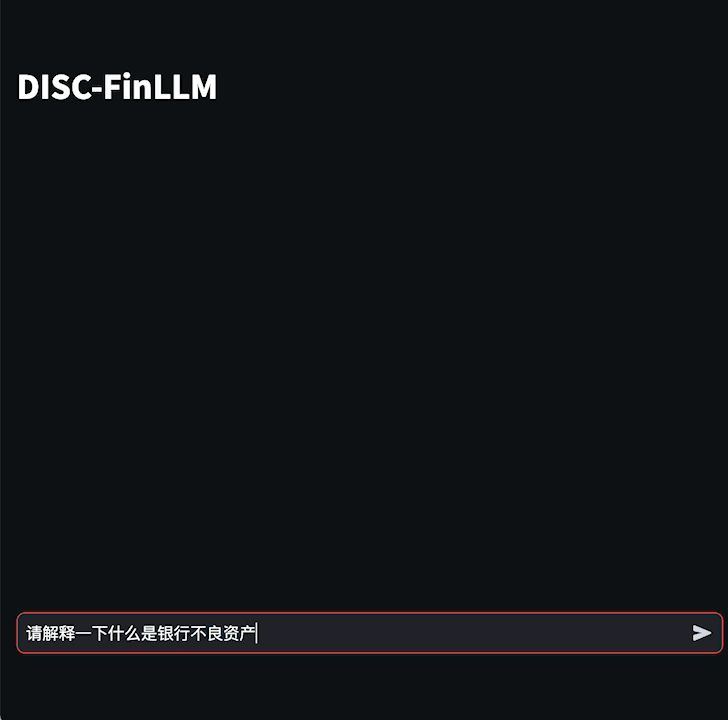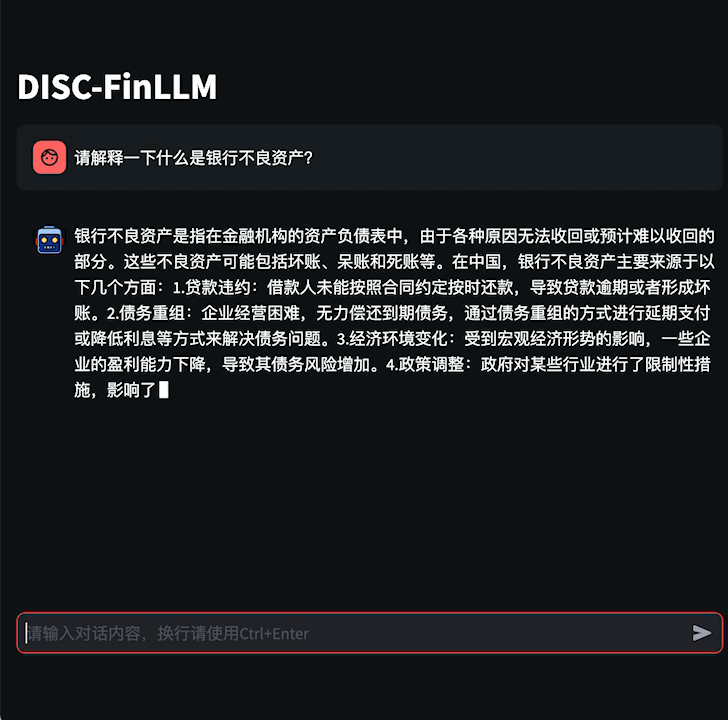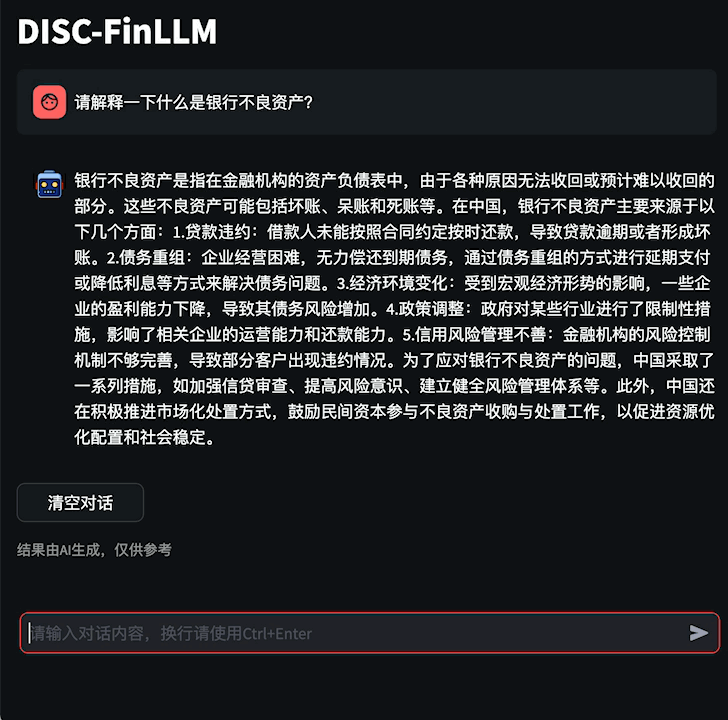
5.45 MB
images/example_retrieval.gif
0 → 100644
{kind=link}
This image diff could not be displayed because it is too large. You can view the blob instead.
images/example_task.gif
0 → 100644
{kind=link}
3.65 MB
images/example_tool.gif
0 → 100644
{kind=link}
3.55 MB
images/lora_en.png
0 → 100644
{kind=link}
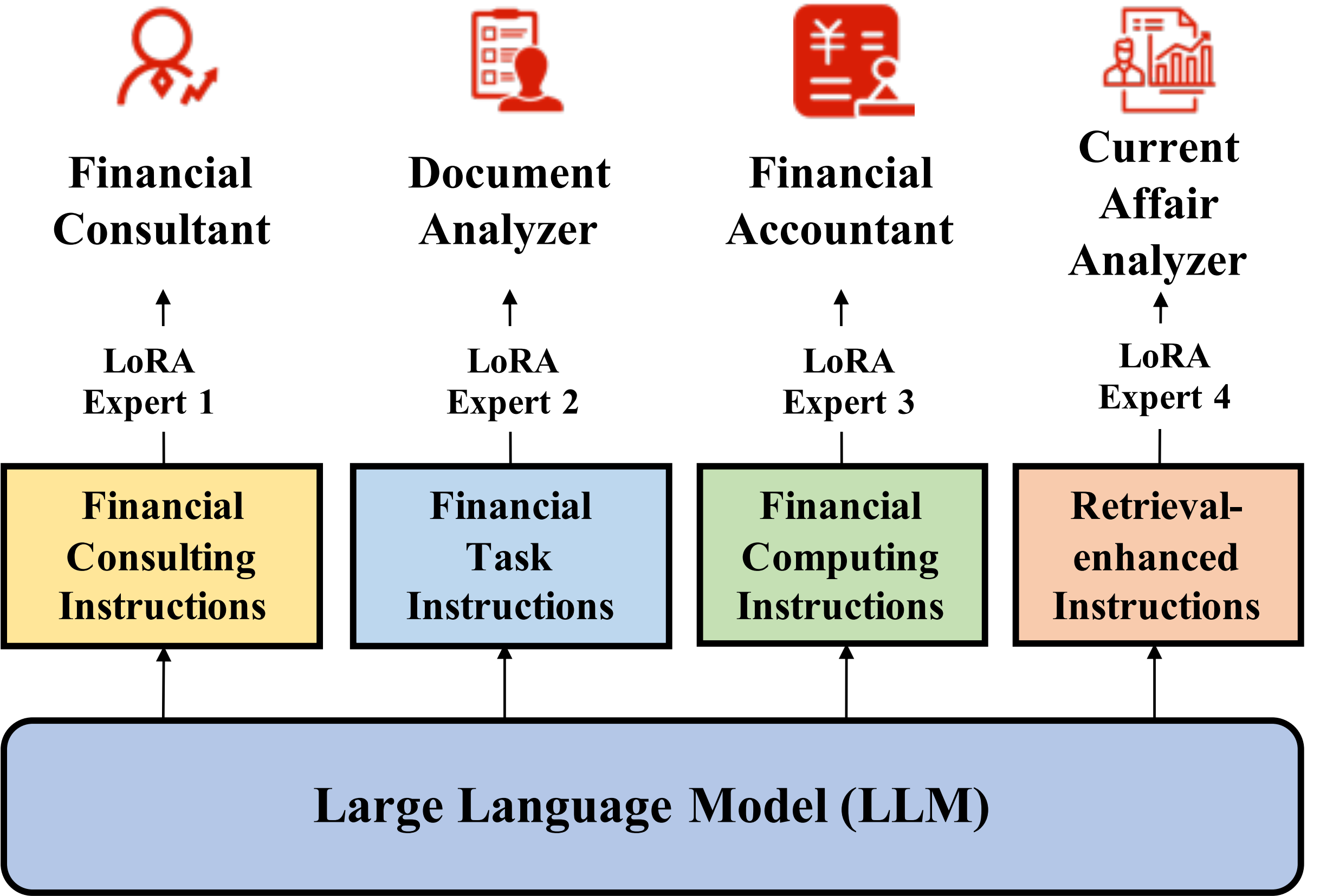
378 KB
images/lora_zh.png
0 → 100644
{kind=link}
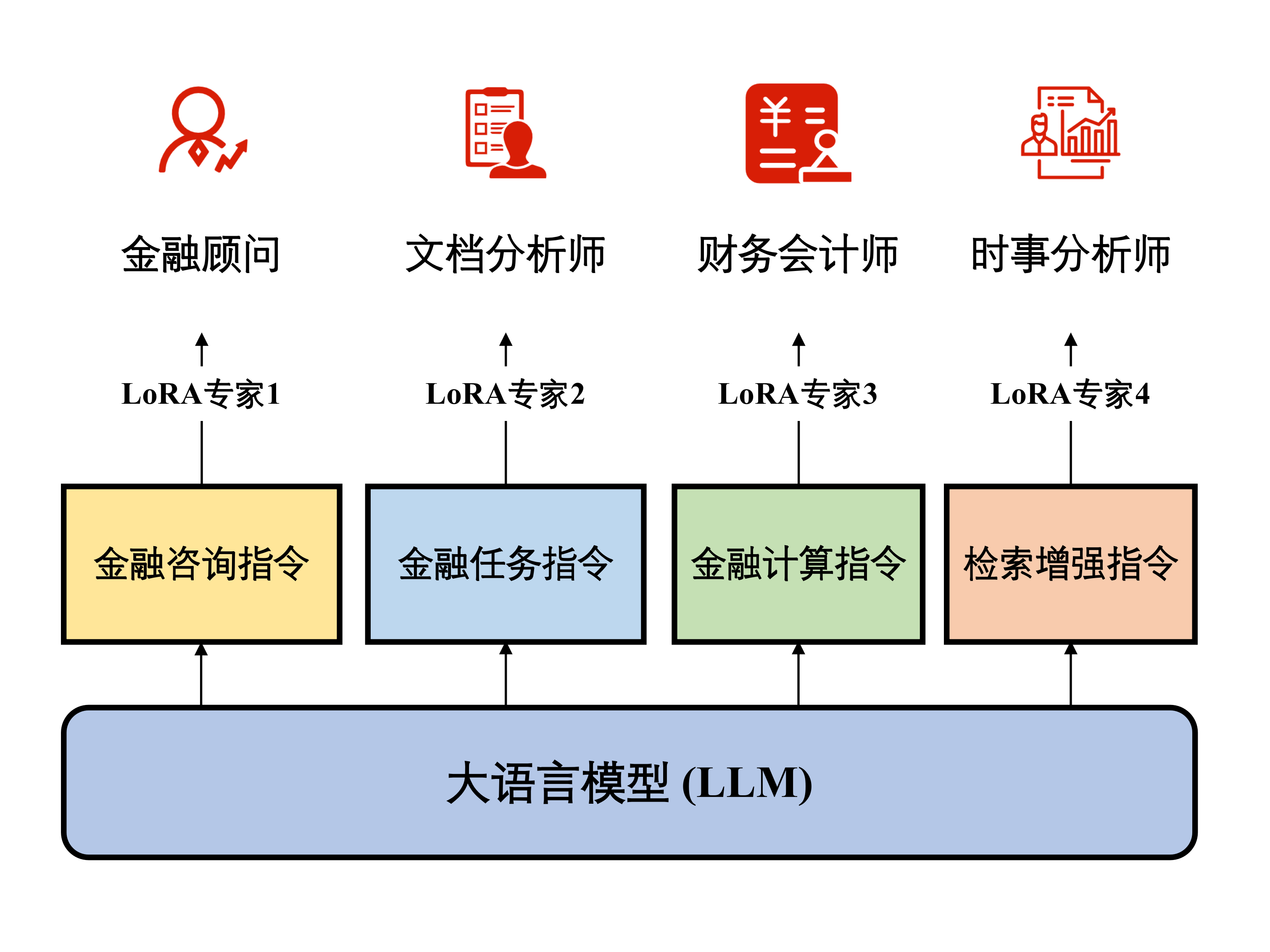
281 KB
images/model_en.png
0 → 100644
{kind=link}
6.48 MB
images/model_zh.png
0 → 100644
{kind=link}
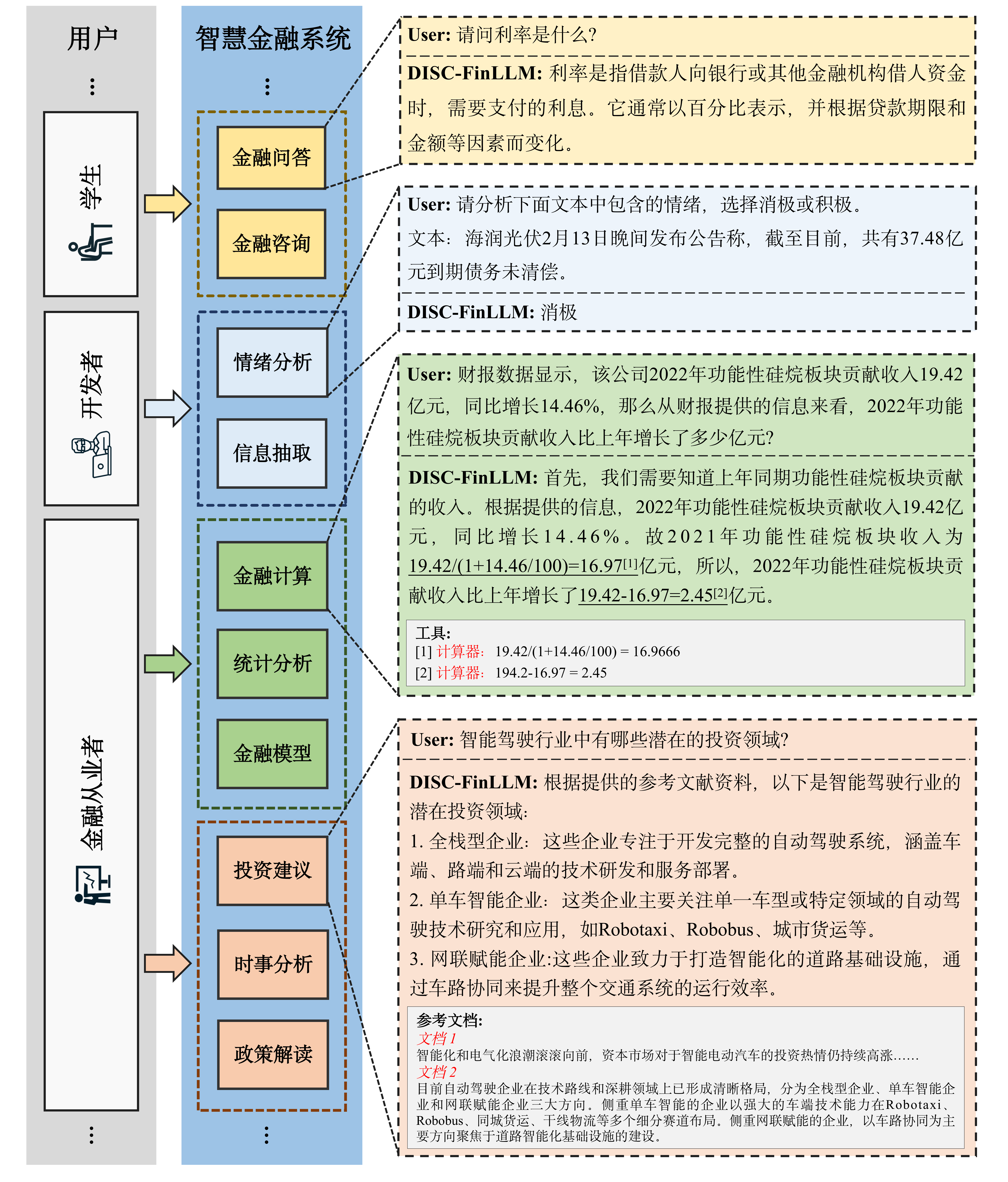
3.73 MB
images/result.png
0 → 100644
{kind=link}

187 KB
images/transformer.jpg
0 → 100644
{kind=link}

87.9 KB
images/transformer.png
0 → 100644
{kind=link}

112 KB
merge_model.py
0 → 100644
model.properties
0 → 100644
multi_dcu_train.sh
0 → 100644
requirements.txt
0 → 100644
| torch | ||
| transformers | ||
| accelerate | ||
| colorama | ||
| cpm_kernels | ||
| sentencepiece | ||
| streamlit | ||
| transformers_stream_generator | ||
| peft | ||
| trl>=0.7.6 | ||
| gradio>=3.38.0,<4.0.0 | ||
| scipy | ||
| einops | ||
| sentencepiece | ||
| protobuf | ||
| jieba | ||
| rouge-chinese | ||
| nltk | ||
| uvicorn | ||
| pydantic | ||
| fastapi | ||
| sse-starlette | ||
| \ No newline at end of file |
sft_work_dtk.sh
0 → 100644
sha_calculator.py
0 → 100644
web_demo.py
0 → 100644