# DeepSeek-V3.2
## 论文
[DeepSeek_V3.2](./doc/paper.pdf)
## 模型简介
DeepSeek-V3.2,这是一个在高计算效率与卓越推理和代理性能之间取得平衡的模型。我们的方法基于三个关键技术突破:
1. **DeepSeek 稀疏注意力(DSA):** 我们引入了 DSA,这是一种高效的注意力机制,它显著降低了计算复杂性,同时保持了模型性能,特别针对长上下文场景进行了优化。
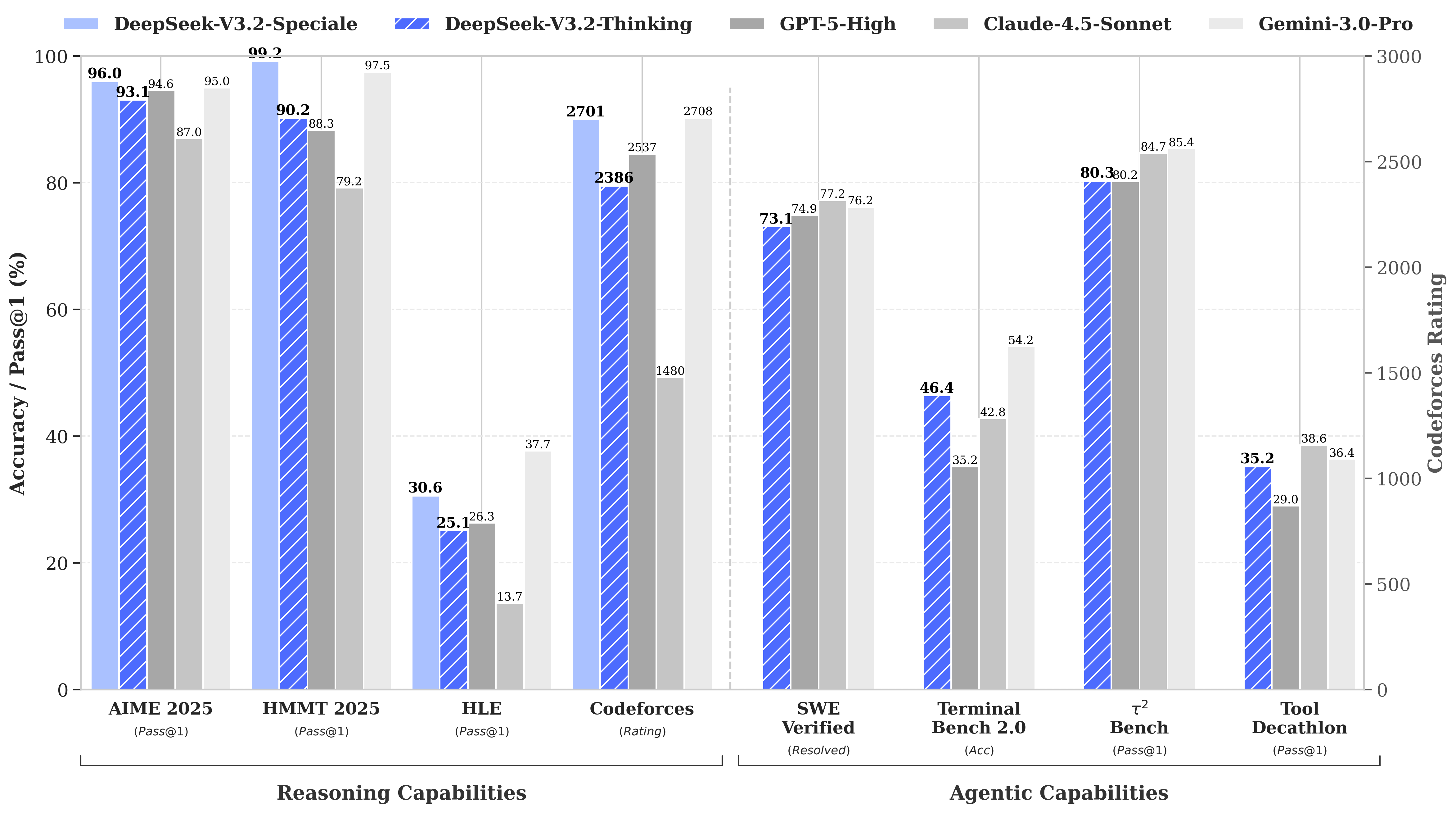
2. **可扩展的强化学习框架:** 通过实施强大的 RL 协议并扩展后训练计算,DeepSeek-V3.2 的表现与 GPT-5 相当。值得注意的是,我们的高计算变体 DeepSeek-V3.2-Speciale 超越了 GPT-5,并在推理能力上与 Gemini-3.0-Pro 相当。
+ *成就:*🥇 2025年国际数学奥林匹克竞赛(IMO)和国际信息学奥林匹克竞赛(IOI)金牌表现。
3. **大规模代理任务合成管道:** 为了将推理融入工具使用场景,我们开发了一种新颖的合成管道,系统地生成大规模训练数据。这促进了可扩展的代理后训练,提高了在复杂交互环境中的合规性和泛化能力。
## 环境依赖
| 软件 | 版本 |
| :------: | :------: |
| DTK | 25.04.1 |
| python | 3.10.12 |
| transformers | 4.56.1 |
| vllm | 0.9.2+das.opt1.dtk25042 |
| torch | 2.5.1+das.opt1.dtk25041 |
推荐使用镜像: image.sourcefind.cn:5000/dcu/admin/base/vllm:0.9.2-ubuntu22.04-dtk25.04.2-das1.7-py3.10-20251203
- 挂载地址`-v` 根据实际模型情况修改
```bash
docker run -it \
--shm-size 60g \
--network=host \
--name deepseek-v32 \
--privileged \
--device=/dev/kfd \
--device=/dev/dri \
--device=/dev/mkfd \
--group-add video \
--cap-add=SYS_PTRACE \
--security-opt seccomp=unconfined \
-u root \
-v /opt/hyhal/:/opt/hyhal/:ro \
-v /path/your_code_data/:/path/your_code_data/ \
image.sourcefind.cn:5000/dcu/admin/base/vllm:0.9.2-ubuntu22.04-dtk25.04.2-das1.7-py3.10-20251203 bash
```
更多镜像可前往[光源](https://sourcefind.cn/#/service-list)下载使用。
关于本项目DCU显卡所需的特殊深度学习库可从[光合](https://developer.sourcefind.cn/tool/)开发者社区下载安装。
**vllm下载安装方法**
```bash
wget http://112.11.119.99:18000/customized/vllm/dtk25.04.2/0.9.2%2Bdas.opt1.dtk25042/0.9.2%2Bdas.opt1.dtk25042-9f9886d8/vllm-0.9.2%2Bdas.opt1.dtk25042.20251202.g9f9886d8-cp310-cp310-manylinux_2_28_x86_64.whl
# 卸载原环境中的vllm
pip uninstall vllm
#安装新的vllm
pip install vllm-0.9.2+das.opt1.dtk25042.20251202.g9f9886d8-cp310-cp310-manylinux_2_28_x86_64.whl
```
**其他库安装方法**
```bash
pip install -r requirements.txt
```
## 数据集
无
## 训练
暂无
## 推理
### vllm
#### 多机推理
1. 将模型转换成bf16格式,转换命令如下:
```bash
# fp8转bf16
python inference/fp8_cast_bf16.py --input-fp8-hf-path /path/to/DeepSeek-V3.2 --output-bf16-hf-path /path/to/DeepSeek-V3.2-bf16
```
转换完成后,将原模型中的 `generation_config.json`, `tokenizer_config.json`, `tokenizer.json`拷贝到`/path/to/DeepSeek-V3.2-bf16`中。
拷贝config文件
```bash
cp inference/config.json /path/to/DeepSeek-V3.2-bf16
```
2. 加入环境变量
> 请注意:
> 每个节点上的环境变量都写到.sh文件中,保存后各个计算节点分别source `.sh` 文件
>
> VLLM_HOST_IP:节点本地通信口ip,尽量选择IB网卡的IP,**避免出现rccl超时问题**
>
> NCCL_SOCKET_IFNAME和GLOO_SOCKET_IFNAME:节点本地通信网口ip对应的名称
>
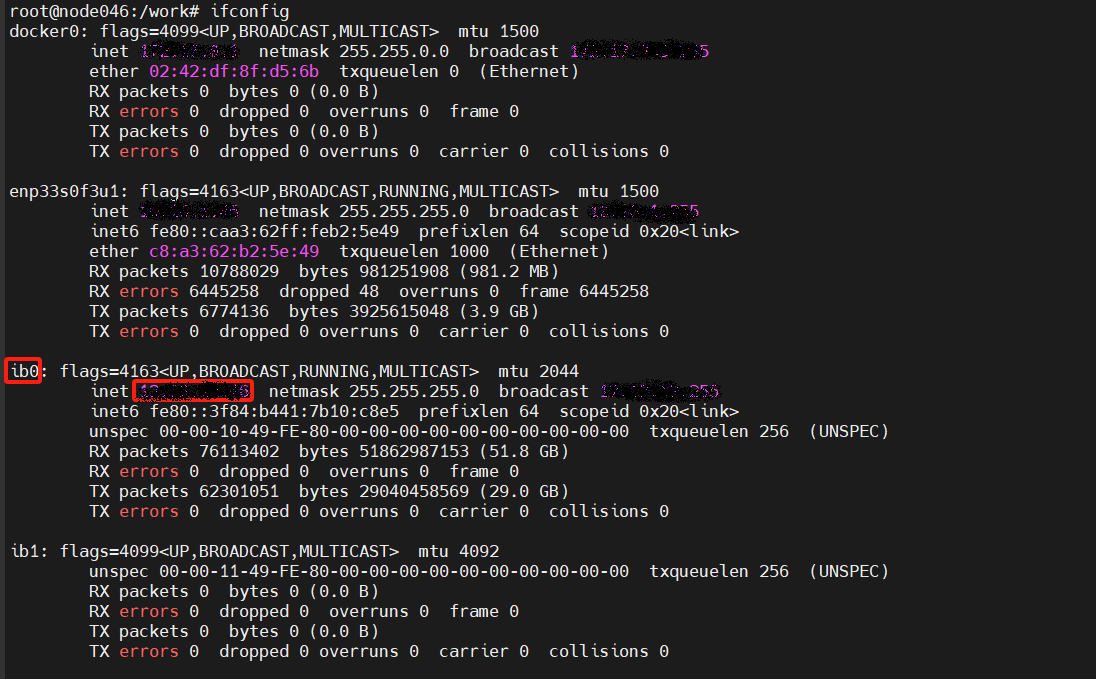
> 通信口和ip查询方法:ifconfig
>
> IB口状态查询:ibstat !!!一定要active激活状态才可用,各个节点要保持统一
```bash
export VLLM_USE_V32_ENCODE=1
export ALLREDUCE_STREAM_WITH_COMPUTE=1
export VLLM_HOST_IP=x.x.x.x # 对应计算节点的IP,建议选择IB口SOCKET_IFNAME对应IP地址
export HIP_VISIBLE_DEVICES=0,1,2,3,4,5,6,7
export HSA_FORCE_FINE_GRAIN_PCIE=1
export NCCL_SOCKET_IFNAME=ibxxxx
export GLOO_SOCKET_IFNAME=ibxxxx
export NCCL_IB_HCA=mlx5_0:1 # 根据 ibstat 查看
unset NCCL_ALGO
export NCCL_IB_DISABLE=0
export NCCL_MAX_NCHANNELS=16
export NCCL_MIN_NCHANNELS=16
export NCCL_NET_GDR_READ=1
export NCCL_DEBUG=INFO
export NCCL_MIN_P2P_NCHANNELS=16
export NCCL_NCHANNELS_PER_PEER=16
export HIP_USE_GRAPH_QUEUE_POOL=1
export VLLM_RPC_TIMEOUT=1800000
export VLLM_USE_FLASH_MLA=1
# 海光CPU绑定核,intel cpu可不加
export VLLM_NUMA_BIND=1
export VLLM_RANK0_NUMA=0
export VLLM_RANK1_NUMA=1
export VLLM_RANK2_NUMA=2
export VLLM_RANK3_NUMA=3
export VLLM_RANK4_NUMA=4
export VLLM_RANK5_NUMA=5
export VLLM_RANK6_NUMA=6
export VLLM_RANK7_NUMA=7
```
3. 启动RAY集群
> x.x.x.x 对应第一步 Master节点的 VLLM_HOST_IP
```bash
# head节点执行
ray start --head --node-ip-address=x.x.x.x --port=6379 --num-gpus=8 --num-cpus=32
# worker节点执行
ray start --address='x.x.x.x:6379' --num-gpus=8 --num-cpus=32
```
4. 启动vllm server
> intel cpu 需要加参数:`--enforce-eager`
```bash
vllm serve /path/to/DeepSeek-V3.2-bf16 \
--trust-remote-code \
--distributed-executor-backend ray \
--dtype bfloat16 \
--tensor-parallel-size 32 \
--max-model-len 32768 \
--port 8001
```
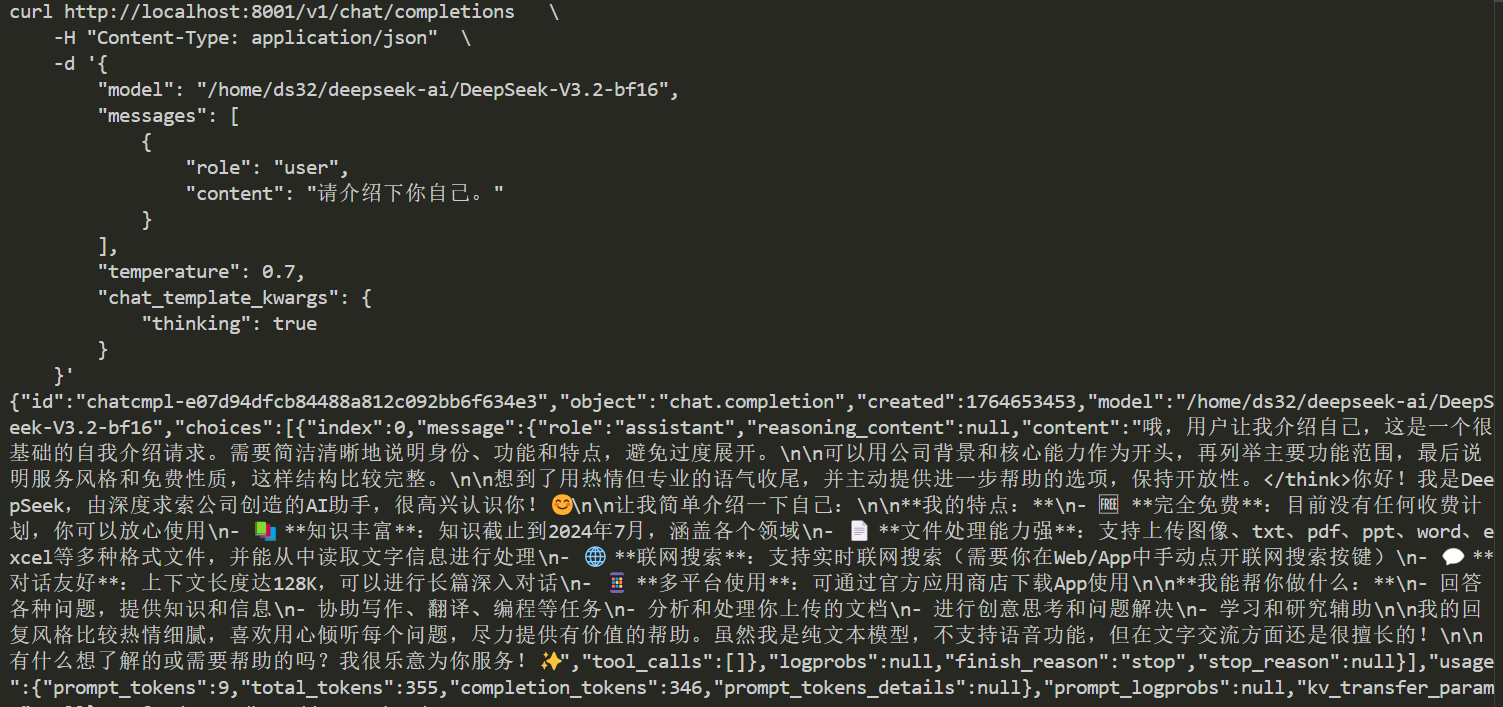
启动完成后可通过以下方式访问:
```bash
curl http://localhost:8001/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "/path/to/DeepSeek-V3.2-bf16",
"messages": [
{
"role": "user",
"content": "请介绍下你自己。"
}
],
"temperature": 1.0,
"chat_template_kwargs": {
"thinking": true
}
}'
```
## 效果展示
### 精度
DCU与GPU精度一致,推理框架:vllm。
## 预训练权重
| 模型名称 | 权重大小 | DCU型号 | 最低卡数需求 |下载地址|
|:-----:|:----------:|:----------:|:---------------------:|:----------:|
| DeepSeek-V3.2 | 685B | BW1000 | 32 | [Hugging Face](https://huggingface.co/deepseek-ai/DeepSeek-V3.2) |
| DeepSeek-V3.2-Speciale | 685B | BW1000 | 32 | [Hugging Face](https://huggingface.co/deepseek-ai/DeepSeek-V3.2-Speciale) |
## 源码仓库及问题反馈
- https://developer.sourcefind.cn/codes/modelzoo/deepseek-v3.2_vllm
## 参考资料
- https://huggingface.co/deepseek-ai/DeepSeek-V3.2