# DeepSeek-V3.2-Exp
## 论文
[DeepSeek_V3.2](./DeepSeek_V3_2.pdf)
## 模型结构
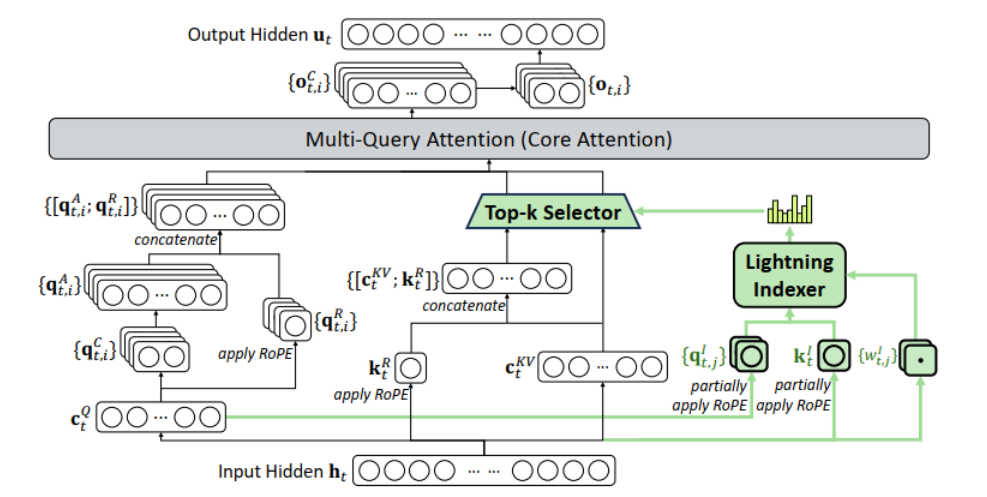
DeepSeek-V3.2-Exp模型是一个实验版本,作为迈向下一代架构的中间步骤,V3.2-Exp 在 V3.1-Terminus 的基础上引入了 DeepSeek 稀疏注意力机制--一种旨在探索和验证在长上下文场景中训练和推理效率优化的稀疏注意力机制。
这个实验版本代表了deepseek团队对更高效变压器架构的持续研究,特别关注在处理扩展文本序列时提高计算效率。
## 算法原理
DeepSeek 稀疏注意力机制(DSA)首次实现了细粒度的稀疏注意力,在保持几乎相同的模型输出质量的同时,显著提高了长上下文训练和推理效率。
## 环境配置
### 硬件需求
DCU型号:K100AI,节点数量:4台,卡数:32 张。
`-v 路径`、`docker_name`和`imageID`根据实际情况修改
### Docker(方法一)
```bash
docker pull image.sourcefind.cn:5000/dcu/admin/base/vllm:0.9.2-ubuntu22.04-dtk25.04.1-rc5-rocblas104381-0915-das1.6-py3.10-20250916-rc2-ds3.2
docker run -it --shm-size 200g --network=host --name {docker_name} --privileged --device=/dev/kfd --device=/dev/dri --device=/dev/mkfd --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -u root -v /path/your_code_data/:/path/your_code_data/ -v /opt/hyhal/:/opt/hyhal/:ro {imageID} bash
cd /your_code_path/deepseek-v3.2-exp_vllm
```
### Dockerfile(方法二)
```bash
cd docker
docker build --no-cache -t deepseek-v3.2-exp:latest .
docker run -it --shm-size 200g --network=host --name {docker_name} --privileged --device=/dev/kfd --device=/dev/dri --device=/dev/mkfd --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -u root -v /path/your_code_data/:/path/your_code_data/ -v /opt/hyhal/:/opt/hyhal/:ro {imageID} bash
cd /your_code_path/deepseek-v3.2-exp_vllm
```
### Anaconda(方法三)
关于本项目DCU显卡所需的特殊深度学习库可从[光合](https://developer.sourcefind.cn/tool/)开发者社区下载安装。
```bash
DTK: 25.04.1
python: 3.10.12
torch: 2.5.1+das.opt1.dtk25041
transformers: 4.56.1
```
`Tips:以上dtk驱动、pytorch等DCU相关工具版本需要严格一一对应`,其他包安装如下:
```bash
wget http://112.11.119.99:18000/temp/vllm-0.9.2%2Bdas.opt1.rc2.51af08a.dtk25041-cp310-cp310-linux_x86_64.whl
pip install vllm-0.9.2+das.opt1.rc2.51af08a.dtk25041-cp310-cp310-linux_x86_64.whl
```
## 数据集
无
## 训练
暂无
## 推理
样例模型:[DeepSeek-V3.2-Exp](https://huggingface.co/deepseek-ai/DeepSeek-V3.2-Exp)
首先将模型转换成bf16格式,转换命令如下:
```bash
# fp8转bf16
python inference/fp8_cast_bf16.py --input-fp8-hf-path /path/to/DeepSeek-V3.2-Exp --output-bf16-hf-path /path/to/DeepSeek-V3.2-Exp-bf16
# 拷贝config文件
cp inference/config.json /path/to/DeepSeek-V3.2-Exp-bf16
```
转换完成后,将原模型中的 `generation_config.json`, `tokenizer_config.json`, `tokenizer.json`拷贝到`/path/to/DeepSeek-V3.2-Exp-bf16`中。
### vllm推理方法
#### server 多机
1. 加入环境变量
> 请注意:
> 每个节点上的环境变量都写到.sh文件中,保存后各个计算节点分别source `.sh` 文件
>
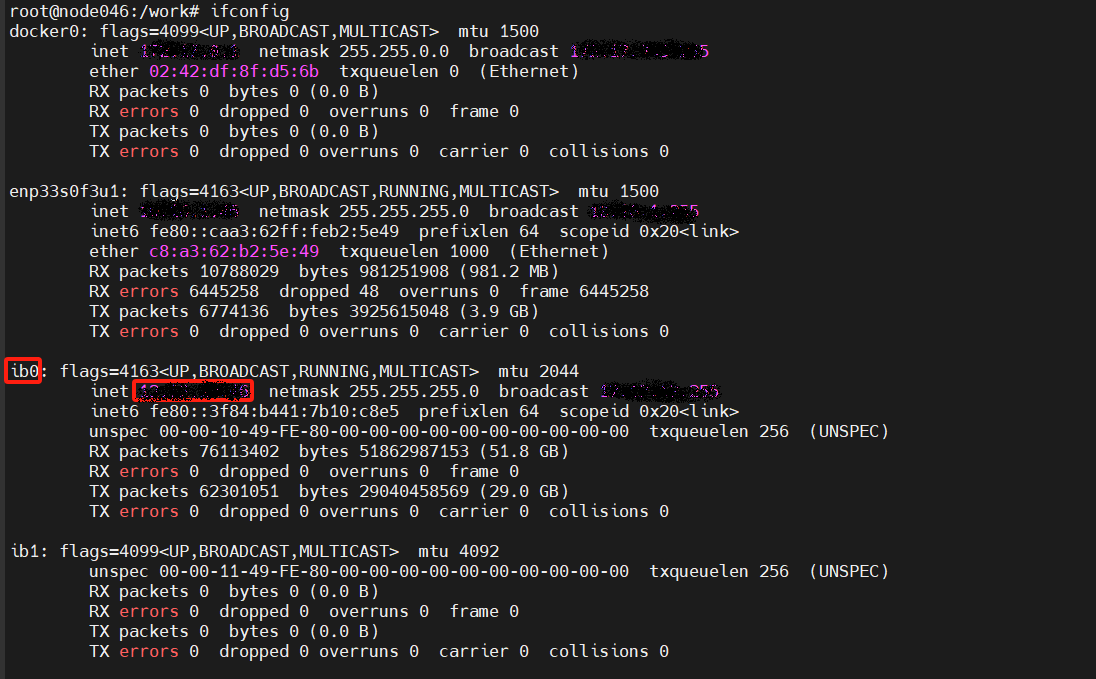
> VLLM_HOST_IP:节点本地通信口ip,尽量选择IB网卡的IP,**避免出现rccl超时问题**
>
> NCCL_SOCKET_IFNAME和GLOO_SOCKET_IFNAME:节点本地通信网口ip对应的名称
>
> 通信口和ip查询方法:ifconfig
>
> IB口状态查询:ibstat !!!一定要active激活状态才可用,各个节点要保持统一
```bash
export ALLREDUCE_STREAM_WITH_COMPUTE=1
export VLLM_HOST_IP=x.x.x.x # 对应计算节点的IP,建议选择IB口SOCKET_IFNAME对应IP地址
export HIP_VISIBLE_DEVICES=0,1,2,3,4,5,6,7
export HSA_FORCE_FINE_GRAIN_PCIE=1
export NCCL_SOCKET_IFNAME=ibxxxx
export GLOO_SOCKET_IFNAME=ibxxxx
export NCCL_IB_HCA=mlx5_0:1
unset NCCL_ALGO
export NCCL_IB_DISABLE=0
export NCCL_MAX_NCHANNELS=16
export NCCL_MIN_NCHANNELS=16
export NCCL_NET_GDR_READ=1
export NCCL_DEBUG=INFO
export NCCL_MIN_P2P_NCHANNELS=16
export NCCL_NCHANNELS_PER_PEER=16
export HIP_USE_GRAPH_QUEUE_POOL=1
export VLLM_ENABLE_MOE_FUSED_GATE=0
export VLLM_ENFORCE_EAGER_BS_THRESHOLD=44
export VLLM_RPC_TIMEOUT=1800000
export VLLM_USE_FLASH_MLA=1
# 海光CPU绑定核,intel cpu可不加
export VLLM_NUMA_BIND=1
export VLLM_RANK0_NUMA=0
export VLLM_RANK1_NUMA=1
export VLLM_RANK2_NUMA=2
export VLLM_RANK3_NUMA=3
export VLLM_RANK4_NUMA=4
export VLLM_RANK5_NUMA=5
export VLLM_RANK6_NUMA=6
export VLLM_RANK7_NUMA=7
#BW集群需要额外设置的环境变量
export NCCL_NET_GDR_LEVEL=7
export NCCL_SDMA_COPY_ENABLE=0
```
2. 启动RAY集群
> x.x.x.x 对应第一步 Master节点的 VLLM_HOST_IP
```bash
# head节点执行
ray start --head --node-ip-address=x.x.x.x --port=6379 --num-gpus=8 --num-cpus=32
# worker节点执行
ray start --address='x.x.x.x:6379' --num-gpus=8 --num-cpus=32
```
3. 启动vllm server
> intel cpu 需要加参数:`--enforce-eager`
```bash
vllm serve /path/to/DeepSeek-V3.2-Exp-bf16 \
--trust-remote-code \
--distributed-executor-backend ray \
--dtype bfloat16 \
--tensor-parallel-size 32 \
--max-model-len 32768 \
--no-enable-chunked-prefill \
--no-enable-prefix-caching \
--port 8001
```
启动完成后可通过以下方式访问:
```bash
curl http://127.0.0.1:8001/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "/path/to/DeepSeek-V3.2-Exp-bf16",
"messages": [
{
"role": "user",
"content": "请介绍下你自己。"
}
],
"max_tokens": 1024,
"temperature": 0.7,
"chat_template_kwargs": {
"thinking": false
}
}'
```
## result
### 精度
DCU与GPU精度一致,推理框架:vllm。
## 应用场景
### 算法类别
`对话问答`
### 热点应用行业
`制造,金融,教育,广媒`
## 预训练权重
- [DeepSeek-V3.2-Exp](https://huggingface.co/deepseek-ai/DeepSeek-V3.2-Exp)
- [DeepSeek-V3.2-Exp-Base](https://huggingface.co/deepseek-ai/DeepSeek-V3.2-Exp-Base)
## 源码仓库及问题反馈
- https://developer.sourcefind.cn/codes/modelzoo/deepseek-v3.2-exp_vllm
## 参考资料
- https://huggingface.co/deepseek-ai/DeepSeek-V3.2-Exp
- https://github.com/deepseek-ai/DeepSeek-V3.2-Exp