
Add deepseek-v3.2-exp
parents
Showing
Contributors.md
0 → 100644
DeepSeek_V3_2.pdf
0 → 100644
File added
LICENSE
0 → 100644
README.md
0 → 100644
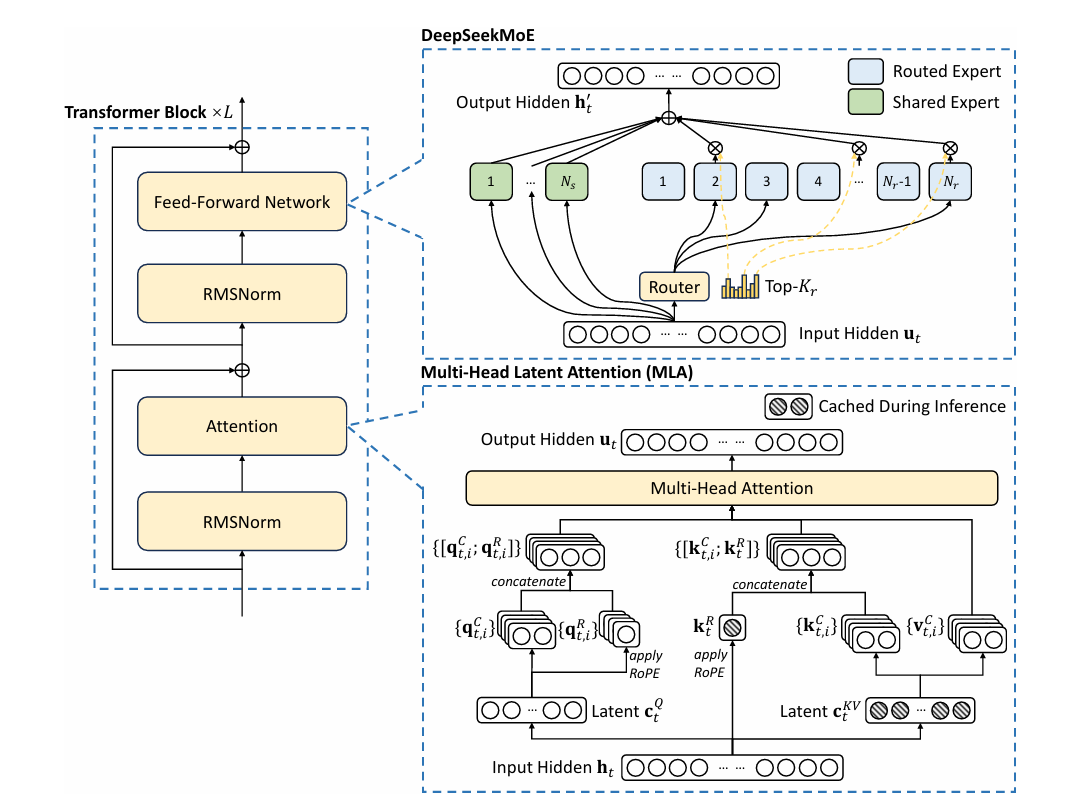
doc/arch.png
0 → 100644
{kind=link}
120 KB
doc/ip_bw.png
0 → 100644
{kind=link}
97.1 KB
doc/results-dcu.jpg
0 → 100644
{kind=link}

436 KB
doc/results-nv.png
0 → 100644
{kind=link}

198 KB
docker/Dockerfile
0 → 100644
icon.png
0 → 100644
{kind=link}
53.8 KB
inference/README.md
0 → 100644
inference/convert.py
0 → 100644
inference/fp8_cast_bf16.py
0 → 100644
inference/generate.py
0 → 100644
inference/kernel.py
0 → 100644
inference/model.py
0 → 100644
inference/requirements.txt
0 → 100644
model.properties
0 → 100644