# DeepSeek-OCR
## 论文
[DeepSeek_OCR](./DeepSeek_OCR_paper.pdf)
## 模型结构
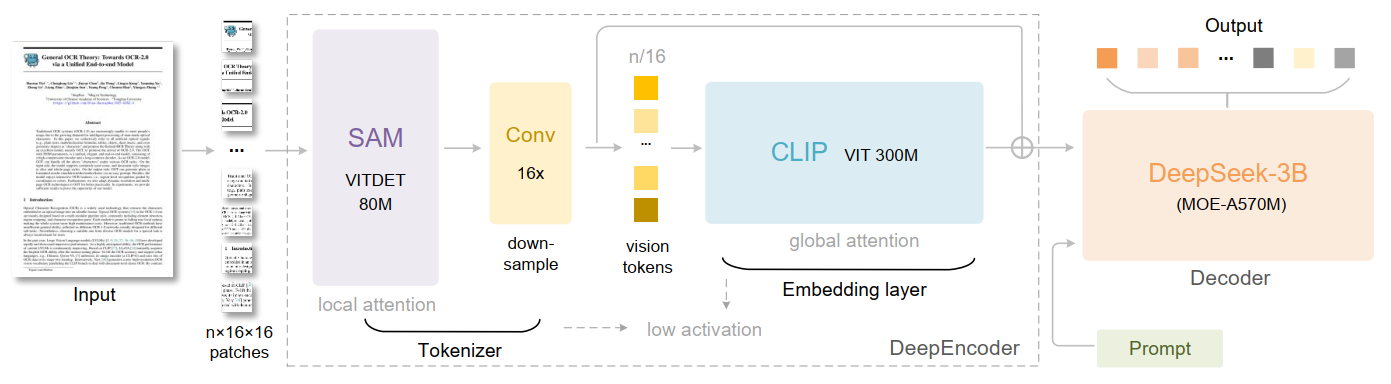
DeepSeek-OCR 由一个深度编码器和一个 DeepSeek-3B-MoE 解码器组成。深度编码器是 DeepSeek-OCR 的核心,它由三个部分构成:一个以窗口注意力为主的感知组件 SAM、一个具有密集全局注意力的用于知识的 CLIP 组件,以及一个连接它们的 16 倍token压缩器。
## 算法原理
DeepSeek 推出了全新的视觉文本压缩模型 DeepSeek-OCR。DeepSeek-OCR 基于 DeepSeek-MoE-VLM 架构,采用了混合专家(MoE)设计,在保持模型小巧的同时实现了强大的功能。
DeepSeek-OCR 的能力范围包括:
- 复杂图表解析(折线图、柱状图等数据可视化)
- 文档格式保留(标题、段落、列表等结构信息)
- 多语言处理(中英文混合识别)
- 物体定位(grounding 功能支持)
## 环境配置
### 硬件需求
DCU型号:K100AI,节点数量:1台,卡数:1张。
`-v 路径`、`docker_name`和`imageID`根据实际情况修改
### Docker(方法一)
```bash
docker pull image.sourcefind.cn:5000/dcu/admin/base/vllm:0.8.5-ubuntu22.04-dtk25.04.1-rc5-das1.6-py3.10-20250724
docker run -it --shm-size 200g --network=host --name {docker_name} --privileged --device=/dev/kfd --device=/dev/dri --device=/dev/mkfd --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -u root -v /path/your_code_data/:/path/your_code_data/ -v /opt/hyhal/:/opt/hyhal/:ro {imageID} bash
cd /your_code_path/deepseek-ocr_pytorch
```
### Dockerfile(方法二)
```bash
cd docker
docker build --no-cache -t deepseek-ocr:latest .
docker run -it --shm-size 200g --network=host --name {docker_name} --privileged --device=/dev/kfd --device=/dev/dri --device=/dev/mkfd --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -u root -v /path/your_code_data/:/path/your_code_data/ -v /opt/hyhal/:/opt/hyhal/:ro {imageID} bash
cd /your_code_path/deepseek-ocr_pytorch
```
### Anaconda(方法三)
关于本项目DCU显卡所需的特殊深度学习库可从[光合](https://developer.sourcefind.cn/tool/)开发者社区下载安装。
```bash
DTK: 25.04.1
python: 3.10.12
torch: 2.5.1+das.opt1.dtk25041
transformers: 4.46.3
vllm: 0.8.5
```
`Tips:以上dtk驱动、pytorch等DCU相关工具版本需要严格一一对应`, 其它非深度学习库参照requirements.txt安装:
```bash
pip install -r requirements.txt
```
## 数据集
暂无
## 训练
暂无
## 推理
### transformers
> 模型地址,测试图片路径,输出路径根据实际情况修改。
```bash
python DeepSeek-OCR-hf/run_dpsk_ocr.py --model_name_or_path=deepseek-ai/DeepSeek-OCR --image_path=./doc/test.png --output_path=./output
```
### vllm
> 模型地址,测试图片路径,输出路径请根据实际情况在`DeepSeek-OCR-vllm/config.py`中修改。
```bash
export VLLM_USE_V1=0
# image:流式输出
python DeepSeek-OCR-vllm/run_dpsk_ocr_image.py
# pdf
python DeepSeek-OCR-vllm/run_dpsk_ocr_pdf.py
```
## result
### 精度
DCU与GPU精度一致,推理框架:vllm。
## 应用场景
### 算法类别
OCR
### 热点应用行业
`制造,金融,交通,教育,医疗`
## 预训练权重
- [DeepSeek-OCR](https://huggingface.co/deepseek-ai/DeepSeek-OCR)
## 源码仓库及问题反馈
- https://developer.sourcefind.cn/codes/modelzoo/deepseek-ocr_pytorch
## 参考资料
- https://github.com/deepseek-ai/DeepSeek-OCR