
first commit
Showing
Evaluation/PAL-Math/run.py
0 → 100644
LICENSE-CODE
0 → 100644
LICENSE-MODEL
0 → 100644
README_ori.md
0 → 100644
assets/attention.png
0 → 100644
{kind=link}
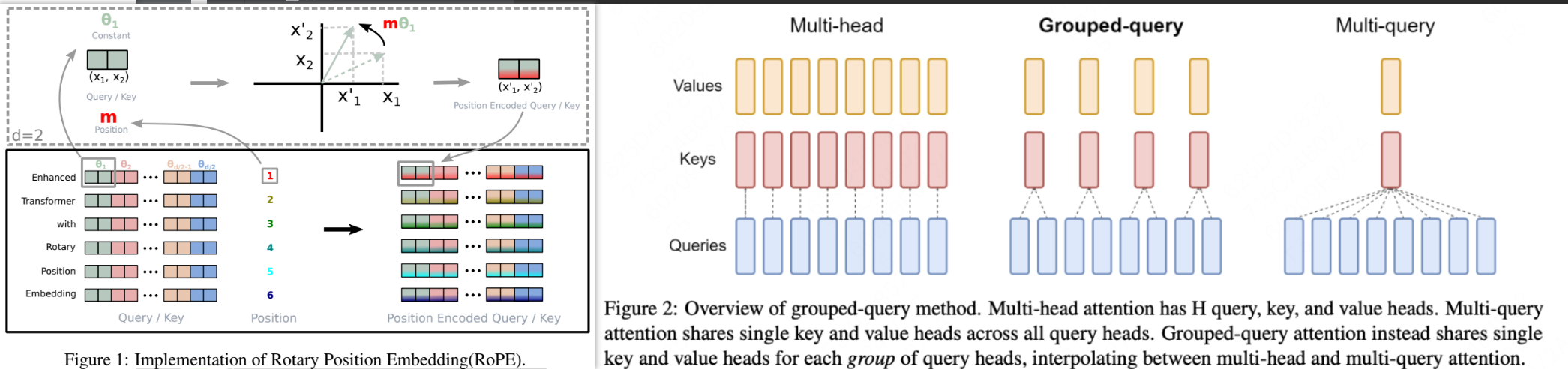
270 KB
assets/model_framework.png
0 → 100644
{kind=link}
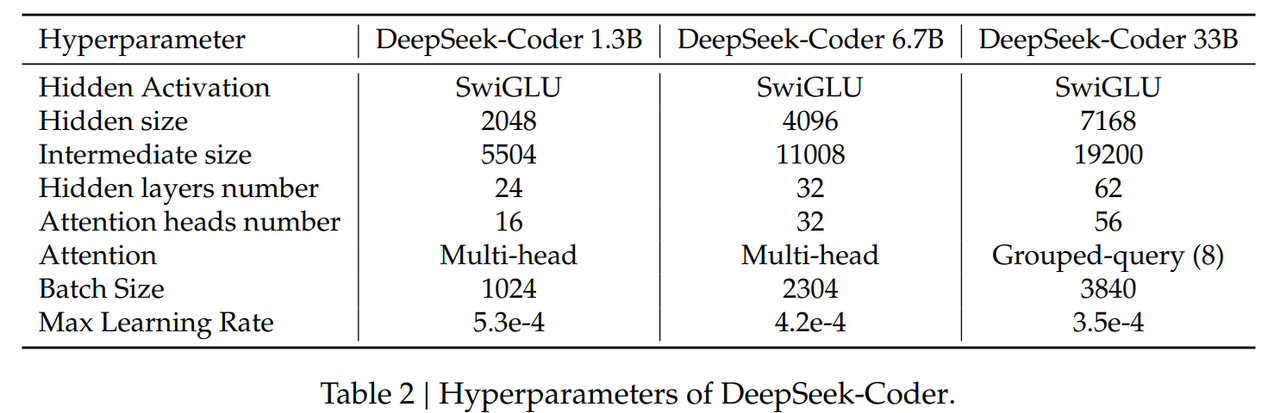
180 KB
assets/result.png
0 → 100644
{kind=link}

25 KB
demo/app.py
0 → 100644
demo/requirement.txt
0 → 100644
demo/style.css
0 → 100644
finetune/README.md
0 → 100644
model.properties
0 → 100644
pictures/DS-1000.png
0 → 100644
{kind=link}
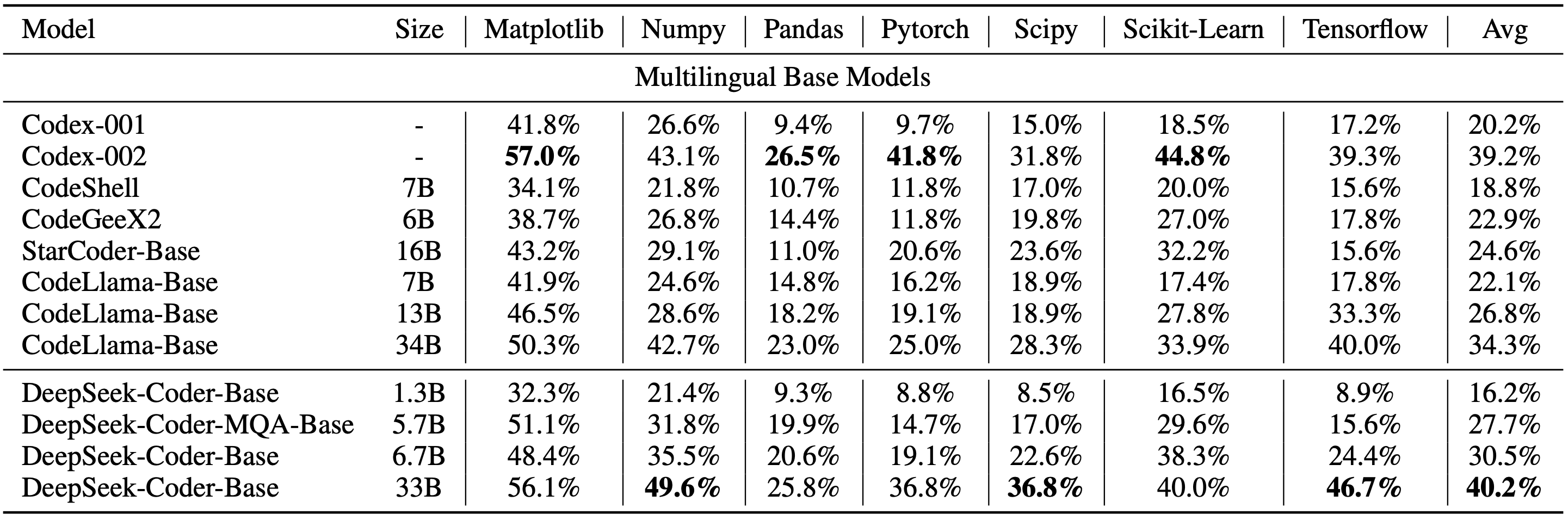
344 KB
pictures/HumanEval.png
0 → 100644
{kind=link}
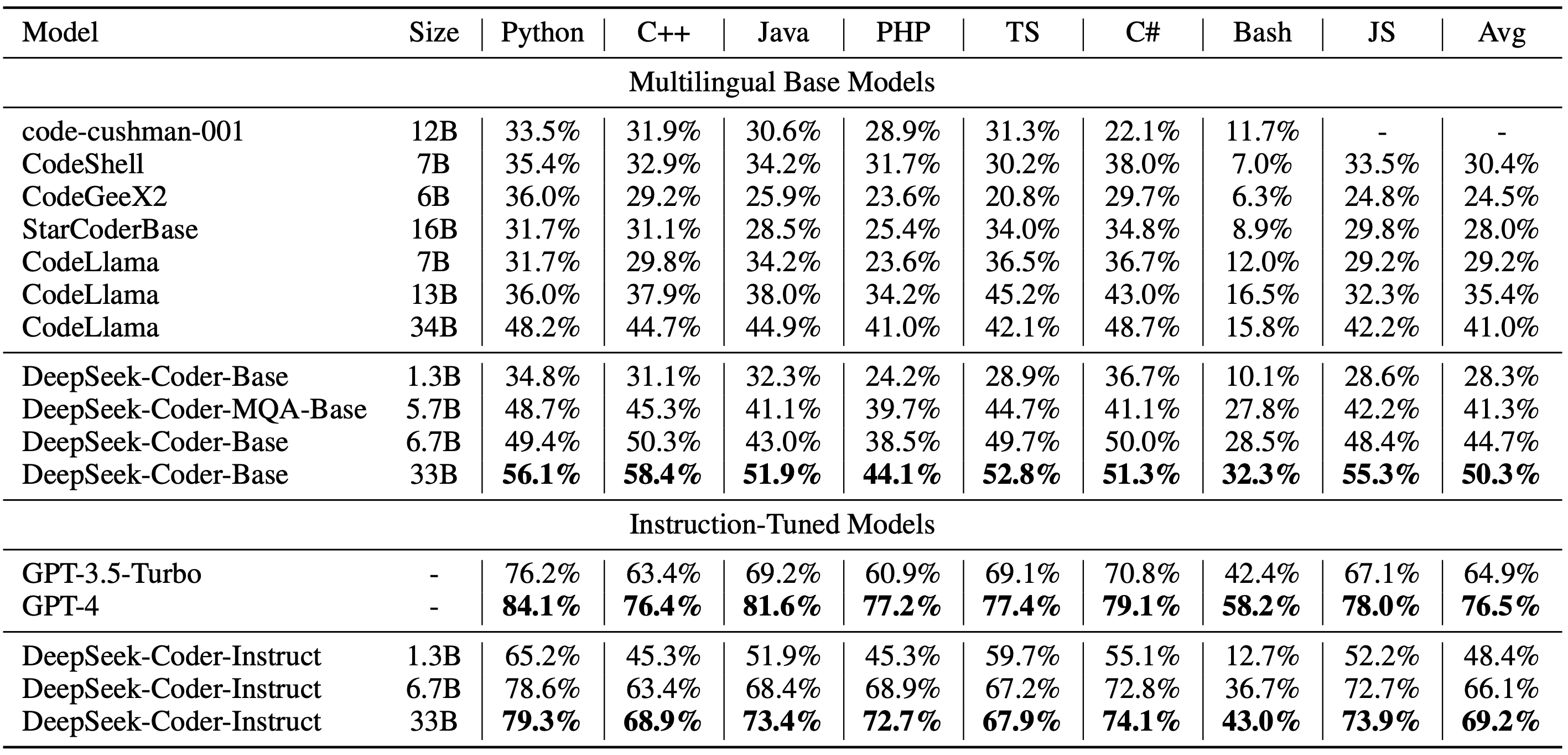
474 KB
pictures/MBPP.png
0 → 100644
{kind=link}
262 KB