# 图像分割
本示例主要通过DeepLabv3模型说明如何使用MIGraphX C++ API进行图像分割模型的推理,包括模型初始化、预处理、模型推理。
## 模型简介
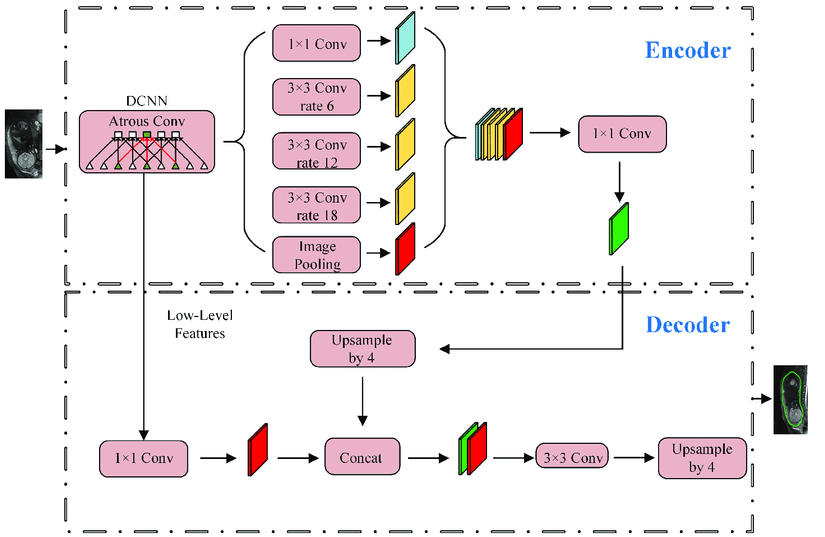
本示例采用了经典的DeepLabv3模型进行图像分割, 模型deeplabv3_resnet101.onnx文件保存在Resource/Models文件夹下。模型结构如下图所示,可以通过netron工具, 链接:https://netron.app/, 查看具体的模型结构,该模型的输入shape为[batch_size,3,513,513],输出shape为[batch_size,513,513],数据排布为NCHW。
 ## 模型初始化
在模型初始化的过程中,首先采用parse_onnx()函数根据提供的模型地址加载图像分割deeplabv3的onnx模型,保存在net中。其次,通过net.get_parameter_shapes()获取deeplabv3模型的输入属性,包含inputName和inputShape。最后,完成模型加载后使用migraphx::gpu::target{}设置编译模式为GPU模式,并使用compile()函数编译模型,完成模型的初始化过程。
其中,模型地址设置在/Resource/Configuration.xml文件中的DeepLabV3节点中。
```C++
ErrorCode DeepLabV3::Initialize(InitializationParameterOfSegmentation initParamOfSegmentationUnet){
...
// 加载模型
if(!Exists(modelPath))
{
LOG_ERROR(stdout, "%s not exist!\n", modelPath.c_str());
return MODEL_NOT_EXIST;
}
migraphx::onnx_options onnx_options;
if(initParamOfSegmentationUnet.loadMode){
onnx_options.map_input_dims["input"] = {1, 3, 513, 513};
}else{
onnx_options.map_input_dims["input"] = {3, 3, 513, 513};
}
net = migraphx::parse_onnx(modelPath,onnx_options);
LOG_INFO(stdout, "succeed to load model: %s\n", GetFileName(modelPath).c_str());
// 获取模型输入/输出节点信息
std::unordered_map inputs = net.get_inputs();
std::unordered_map outputs = net.get_outputs();
inputName = inputs.begin()->first;
inputShape = inputs.begin()->second;
outputName = outputs.begin()->first;
outputShape = outputs.begin()->second;
auto it = outputs.begin();
++it;
outputName2 = it->first;
outputShape2 = it->second;
int N = inputShape.lens()[0];
int C = inputShape.lens()[1];
int H = inputShape.lens()[2];
int W = inputShape.lens()[3];
inputSize = cv::Size(W, H);
// 设置模型为GPU模式
migraphx::target gpuTarget = migraphx::gpu::target{};
if(useInt8){
std::vector calibrateImages;
std::string folderPath = "../Resource/Images/calibrateImages/";
std::string calibrateImageExt = "*.jpg";
std::vector calibrateImagePaths;
cv::glob(folderPath + calibrateImageExt, calibrateImagePaths, false);
for(const auto& path : calibrateImagePaths){
calibrateImages.push_back(cv::imread(path, 1));
}
cv::Mat inputcalibrateBlob;
cv::dnn::blobFromImages(calibrateImages, inputcalibrateBlob, 1 / 255.0, inputSize, cv::Scalar(0, 0, 0), true, false);
std::unordered_map inputData;
inputData[inputName] = migraphx::argument{inputShape, (float *)inputcalibrateBlob.data};
std::vector> calibrationData = {inputData};
// INT8量化
migraphx::quantize_int8(net, gpuTarget, calibrationData);
}else{
migraphx::quantize_fp16(net);
}
// 编译模型
migraphx::compile_options options;
options.device_id = 0; // 设置GPU设备,默认为0号设备
if(useOffloadCopy){
options.offload_copy = true;
}else{
options.offload_copy = false;
}
net.compile(gpuTarget, options);
LOG_INFO(stdout, "succeed to compile model: %s\n", GetFileName(modelPath).c_str());
if(!useOffloadCopy){
inputBufferDevice = nullptr;
hipMalloc(&inputBufferDevice, inputShape.bytes());
modalDataMap[inputName] = migraphx::argument{inputShape, inputBufferDevice};
outputBufferDevice = nullptr;
hipMalloc(&outputBufferDevice, outputShape.bytes());
outputBufferDevice2 = nullptr;
hipMalloc(&outputBufferDevice2, outputShape2.bytes());
modalDataMap[outputName] = migraphx::argument{outputShape, outputBufferDevice};
modalDataMap[outputName2] = migraphx::argument{outputShape2, outputBufferDevice2};
outputBufferHost = nullptr; // host内存
outputBufferHost = malloc(outputShape.bytes());
outputBufferHost2 = nullptr; // host内存
outputBufferHost2 = malloc(outputShape2.bytes());
}
...
}
```
## 预处理
完成模型初始化后,需要将输入数据进行如下预处理:
1.尺度变换,将图像resize到513x513大小
2.归一化,将数据归一化到[0.0, 1.0]之间
3.数据排布,将数据从HWC转换为NCHW
本示例代码主要通过opencv实现预处理操作:
```C++
ErrorCode Unet::Segmentation(const cv::Mat &srcImage, cv::Mat &maskImage){
...
// 图像预处理并转换为NCHW
cv::Mat inputBlob;
cv::dnn::blobFromImage(srcImage, // 输入数据,支持多张图像
inputBlob, // 输出数据
1 / 255.0, // 缩放系数
inputSize, // 模型输入大小,这里为256x256
Scalar(0, 0, 0), // 均值,这里不需要减均值,所以设置为0
true, // 通道转换,B通道与R通道互换,所以为true
false);
...
}
```
1.cv::dnn::blobFromImage()函数支持多个输入图像,首先将输入图像resize到inputSize大小,然后减去均值,其次乘以缩放系数1/255.0并转换为NCHW,最终将转换好的数据保存到inputBlob作为输入数据,执行后续的模型推理。
## 推理
完成图像预处理后,就可以执行模型推理。
当useOffloadCopy==true时,首先,定义inputData表示deeplabv3模型的输入数据,inputName表示deeplabv3模型的输入节点名,采用migraphx::argument{inputShape, (float*)inputBlob.data}保存前面预处理的数据inputBlob,第一个参数表示输入数据的shape,第二个参数表示输入数据指针。其次,执行net.eval(inputData)获得模型的推理结果,使用results[0]获取输出节点的数据,就可以对输出数据执行相关后处理操作。
当useOffloadCopy==false时,首先,定义inputData表示deeplabv3模型的输入数据,并将数据拷贝到GPU中的输入内存。其次,执行net.eval(modalDataMap)执行推理,modalDataMap中保存着模型的GPU输出地址,推理的输出结果会保存在对应的输出内存中,将GPU输出数据拷贝到分配好的host输出内存后,即可获取输出节点的数据,就可以对输出数据执行相关后处理操作。
```c++
ErrorCode DeepLabV3::Segmentation(const cv::Mat &srcImage, cv::Mat &maskImage){
...
if(useOffloadCopy){
// 创建输入数据
std::unordered_map inputData;
inputData[inputName] = migraphx::argument{inputShape, (float*)inputBatchBlob.data};
// 推理
std::vector results = net.eval(inputData);
// 获取输出节点的属性
migraphx::argument result = results[0]; // 获取第一个输出节点的数据
migraphx::shape outputShape = result.get_shape(); // 输出节点的shape
std::vector outputSize = outputShape.lens(); // 每一维大小,维度顺序为(N,C,H,W)
int numberOfOutput = outputShape.elements(); // 输出节点元素的个数
float* data = (float*)result.data(); // 输出节点数据指针
}else{
migraphx::argument inputData = migraphx::argument{inputShape, (float*)inputBatchBlob.data};
// 拷贝到device输入内存
hipMemcpy(inputBufferDevice, inputData.data(), inputShape.bytes(), hipMemcpyHostToDevice);
// 推理
std::vector results = net.eval(modalDataMap);
// 获取输出节点的属性
migraphx::argument result = results[0]; // 获取第一个输出节点的数据
migraphx::shape outputShapes = result.get_shape(); // 输出节点的shape
std::vector outputSize = outputShapes.lens(); // 每一维大小,维度顺序为(N,C,H,W)
int numberOfOutput = outputShapes.elements(); // 输出节点元素的个数
// 将device输出数据拷贝到分配好的host输出内存
hipMemcpy(outputBufferHost,outputBufferDevice, outputShapes.bytes(),hipMemcpyDeviceToHost); // 直接使用事先分配好的输出内存拷贝
}
...
}
```
模型得到的推理结果并不能直接作为图像的分割结果,还需要做如下处理:
1.计算softmax值,计算不同通道同一[H,W]位置的softmax值,找出概率最高的通道。
2.保存结果,创建一个cv::Mat,根据不同的通道索引在颜色映射表取值并按行依次赋值到Mat对应位置,得到最终的分割图像。
```c++
ErrorCode DeepLabV3::Segmentation(const cv::Mat &srcImage, cv::Mat &maskImage){
...
cv::Mat outputImage(cv::Size(W, H), CV_8UC3);
// 创建颜色映射表
std::vector color_map = create_color_map();
for(int i = 0;i < H; i++){
for(int j = 0;j < W;j++){
std::vector channel_value;
for(int k = 0;k < C;k++){
channel_value.push_back(data[k*(H*W)+i*W+j]);
}
std::vector probs = softmax(channel_value);
// 找到概率最高的类别索引
int max_index = std::max_element(probs.begin(),probs.end())-probs.begin();
cv::Scalar sc = color_map[max_index];
outputImage.at(i, j)[0]= sc.val[0];
outputImage.at(i, j)[1]= sc.val[1];
outputImage.at(i, j)[2]= sc.val[2];
}
}
maskImage = outputImage.clone();
...
}
```
注:本次采用的模型权重onnx文件是通过使用PASCAL VOC 2012数据集来训练的。因此,“现实世界“图像的分割结果不完美是意料之中的。为了获得更好的结果,建议对现实世界示例数据集上的模型进行微调。
## 模型初始化
在模型初始化的过程中,首先采用parse_onnx()函数根据提供的模型地址加载图像分割deeplabv3的onnx模型,保存在net中。其次,通过net.get_parameter_shapes()获取deeplabv3模型的输入属性,包含inputName和inputShape。最后,完成模型加载后使用migraphx::gpu::target{}设置编译模式为GPU模式,并使用compile()函数编译模型,完成模型的初始化过程。
其中,模型地址设置在/Resource/Configuration.xml文件中的DeepLabV3节点中。
```C++
ErrorCode DeepLabV3::Initialize(InitializationParameterOfSegmentation initParamOfSegmentationUnet){
...
// 加载模型
if(!Exists(modelPath))
{
LOG_ERROR(stdout, "%s not exist!\n", modelPath.c_str());
return MODEL_NOT_EXIST;
}
migraphx::onnx_options onnx_options;
if(initParamOfSegmentationUnet.loadMode){
onnx_options.map_input_dims["input"] = {1, 3, 513, 513};
}else{
onnx_options.map_input_dims["input"] = {3, 3, 513, 513};
}
net = migraphx::parse_onnx(modelPath,onnx_options);
LOG_INFO(stdout, "succeed to load model: %s\n", GetFileName(modelPath).c_str());
// 获取模型输入/输出节点信息
std::unordered_map inputs = net.get_inputs();
std::unordered_map outputs = net.get_outputs();
inputName = inputs.begin()->first;
inputShape = inputs.begin()->second;
outputName = outputs.begin()->first;
outputShape = outputs.begin()->second;
auto it = outputs.begin();
++it;
outputName2 = it->first;
outputShape2 = it->second;
int N = inputShape.lens()[0];
int C = inputShape.lens()[1];
int H = inputShape.lens()[2];
int W = inputShape.lens()[3];
inputSize = cv::Size(W, H);
// 设置模型为GPU模式
migraphx::target gpuTarget = migraphx::gpu::target{};
if(useInt8){
std::vector calibrateImages;
std::string folderPath = "../Resource/Images/calibrateImages/";
std::string calibrateImageExt = "*.jpg";
std::vector calibrateImagePaths;
cv::glob(folderPath + calibrateImageExt, calibrateImagePaths, false);
for(const auto& path : calibrateImagePaths){
calibrateImages.push_back(cv::imread(path, 1));
}
cv::Mat inputcalibrateBlob;
cv::dnn::blobFromImages(calibrateImages, inputcalibrateBlob, 1 / 255.0, inputSize, cv::Scalar(0, 0, 0), true, false);
std::unordered_map inputData;
inputData[inputName] = migraphx::argument{inputShape, (float *)inputcalibrateBlob.data};
std::vector> calibrationData = {inputData};
// INT8量化
migraphx::quantize_int8(net, gpuTarget, calibrationData);
}else{
migraphx::quantize_fp16(net);
}
// 编译模型
migraphx::compile_options options;
options.device_id = 0; // 设置GPU设备,默认为0号设备
if(useOffloadCopy){
options.offload_copy = true;
}else{
options.offload_copy = false;
}
net.compile(gpuTarget, options);
LOG_INFO(stdout, "succeed to compile model: %s\n", GetFileName(modelPath).c_str());
if(!useOffloadCopy){
inputBufferDevice = nullptr;
hipMalloc(&inputBufferDevice, inputShape.bytes());
modalDataMap[inputName] = migraphx::argument{inputShape, inputBufferDevice};
outputBufferDevice = nullptr;
hipMalloc(&outputBufferDevice, outputShape.bytes());
outputBufferDevice2 = nullptr;
hipMalloc(&outputBufferDevice2, outputShape2.bytes());
modalDataMap[outputName] = migraphx::argument{outputShape, outputBufferDevice};
modalDataMap[outputName2] = migraphx::argument{outputShape2, outputBufferDevice2};
outputBufferHost = nullptr; // host内存
outputBufferHost = malloc(outputShape.bytes());
outputBufferHost2 = nullptr; // host内存
outputBufferHost2 = malloc(outputShape2.bytes());
}
...
}
```
## 预处理
完成模型初始化后,需要将输入数据进行如下预处理:
1.尺度变换,将图像resize到513x513大小
2.归一化,将数据归一化到[0.0, 1.0]之间
3.数据排布,将数据从HWC转换为NCHW
本示例代码主要通过opencv实现预处理操作:
```C++
ErrorCode Unet::Segmentation(const cv::Mat &srcImage, cv::Mat &maskImage){
...
// 图像预处理并转换为NCHW
cv::Mat inputBlob;
cv::dnn::blobFromImage(srcImage, // 输入数据,支持多张图像
inputBlob, // 输出数据
1 / 255.0, // 缩放系数
inputSize, // 模型输入大小,这里为256x256
Scalar(0, 0, 0), // 均值,这里不需要减均值,所以设置为0
true, // 通道转换,B通道与R通道互换,所以为true
false);
...
}
```
1.cv::dnn::blobFromImage()函数支持多个输入图像,首先将输入图像resize到inputSize大小,然后减去均值,其次乘以缩放系数1/255.0并转换为NCHW,最终将转换好的数据保存到inputBlob作为输入数据,执行后续的模型推理。
## 推理
完成图像预处理后,就可以执行模型推理。
当useOffloadCopy==true时,首先,定义inputData表示deeplabv3模型的输入数据,inputName表示deeplabv3模型的输入节点名,采用migraphx::argument{inputShape, (float*)inputBlob.data}保存前面预处理的数据inputBlob,第一个参数表示输入数据的shape,第二个参数表示输入数据指针。其次,执行net.eval(inputData)获得模型的推理结果,使用results[0]获取输出节点的数据,就可以对输出数据执行相关后处理操作。
当useOffloadCopy==false时,首先,定义inputData表示deeplabv3模型的输入数据,并将数据拷贝到GPU中的输入内存。其次,执行net.eval(modalDataMap)执行推理,modalDataMap中保存着模型的GPU输出地址,推理的输出结果会保存在对应的输出内存中,将GPU输出数据拷贝到分配好的host输出内存后,即可获取输出节点的数据,就可以对输出数据执行相关后处理操作。
```c++
ErrorCode DeepLabV3::Segmentation(const cv::Mat &srcImage, cv::Mat &maskImage){
...
if(useOffloadCopy){
// 创建输入数据
std::unordered_map inputData;
inputData[inputName] = migraphx::argument{inputShape, (float*)inputBatchBlob.data};
// 推理
std::vector results = net.eval(inputData);
// 获取输出节点的属性
migraphx::argument result = results[0]; // 获取第一个输出节点的数据
migraphx::shape outputShape = result.get_shape(); // 输出节点的shape
std::vector outputSize = outputShape.lens(); // 每一维大小,维度顺序为(N,C,H,W)
int numberOfOutput = outputShape.elements(); // 输出节点元素的个数
float* data = (float*)result.data(); // 输出节点数据指针
}else{
migraphx::argument inputData = migraphx::argument{inputShape, (float*)inputBatchBlob.data};
// 拷贝到device输入内存
hipMemcpy(inputBufferDevice, inputData.data(), inputShape.bytes(), hipMemcpyHostToDevice);
// 推理
std::vector results = net.eval(modalDataMap);
// 获取输出节点的属性
migraphx::argument result = results[0]; // 获取第一个输出节点的数据
migraphx::shape outputShapes = result.get_shape(); // 输出节点的shape
std::vector outputSize = outputShapes.lens(); // 每一维大小,维度顺序为(N,C,H,W)
int numberOfOutput = outputShapes.elements(); // 输出节点元素的个数
// 将device输出数据拷贝到分配好的host输出内存
hipMemcpy(outputBufferHost,outputBufferDevice, outputShapes.bytes(),hipMemcpyDeviceToHost); // 直接使用事先分配好的输出内存拷贝
}
...
}
```
模型得到的推理结果并不能直接作为图像的分割结果,还需要做如下处理:
1.计算softmax值,计算不同通道同一[H,W]位置的softmax值,找出概率最高的通道。
2.保存结果,创建一个cv::Mat,根据不同的通道索引在颜色映射表取值并按行依次赋值到Mat对应位置,得到最终的分割图像。
```c++
ErrorCode DeepLabV3::Segmentation(const cv::Mat &srcImage, cv::Mat &maskImage){
...
cv::Mat outputImage(cv::Size(W, H), CV_8UC3);
// 创建颜色映射表
std::vector color_map = create_color_map();
for(int i = 0;i < H; i++){
for(int j = 0;j < W;j++){
std::vector channel_value;
for(int k = 0;k < C;k++){
channel_value.push_back(data[k*(H*W)+i*W+j]);
}
std::vector probs = softmax(channel_value);
// 找到概率最高的类别索引
int max_index = std::max_element(probs.begin(),probs.end())-probs.begin();
cv::Scalar sc = color_map[max_index];
outputImage.at(i, j)[0]= sc.val[0];
outputImage.at(i, j)[1]= sc.val[1];
outputImage.at(i, j)[2]= sc.val[2];
}
}
maskImage = outputImage.clone();
...
}
```
注:本次采用的模型权重onnx文件是通过使用PASCAL VOC 2012数据集来训练的。因此,“现实世界“图像的分割结果不完美是意料之中的。为了获得更好的结果,建议对现实世界示例数据集上的模型进行微调。