
init
Showing
Too many changes to show.
To preserve performance only 388 of 388+ files are displayed.
.readthedocs.yml
0 → 100644
CITATION.cff
0 → 100644
Dockerfile
0 → 100644
LICENSE
0 → 100644
MANIFEST.in
0 → 100644
README.md
0 → 100644
README_ori.md
0 → 100644
README_zh-CN.md
0 → 100644
assets/ddq.png
0 → 100644
{kind=link}
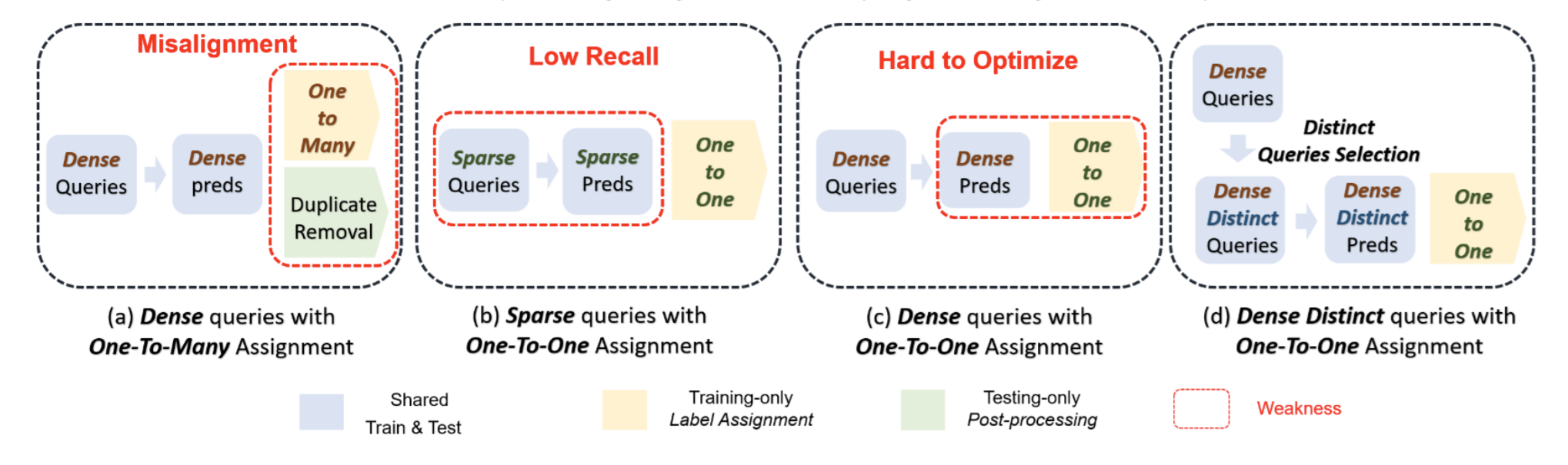
374 KB
assets/ddq_pipeline.png
0 → 100644
{kind=link}
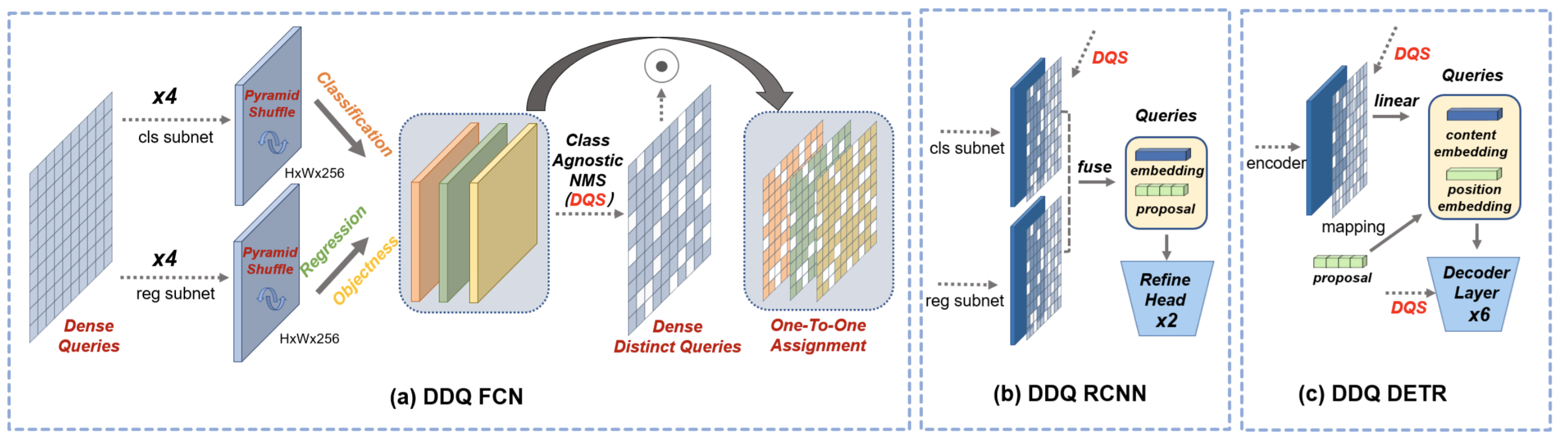
617 KB
assets/demo.jpg
0 → 100644
{kind=link}

180 KB