# DALL-E 2
## 论文
- https://arxiv.org/pdf/2204.06125
## 模型结构
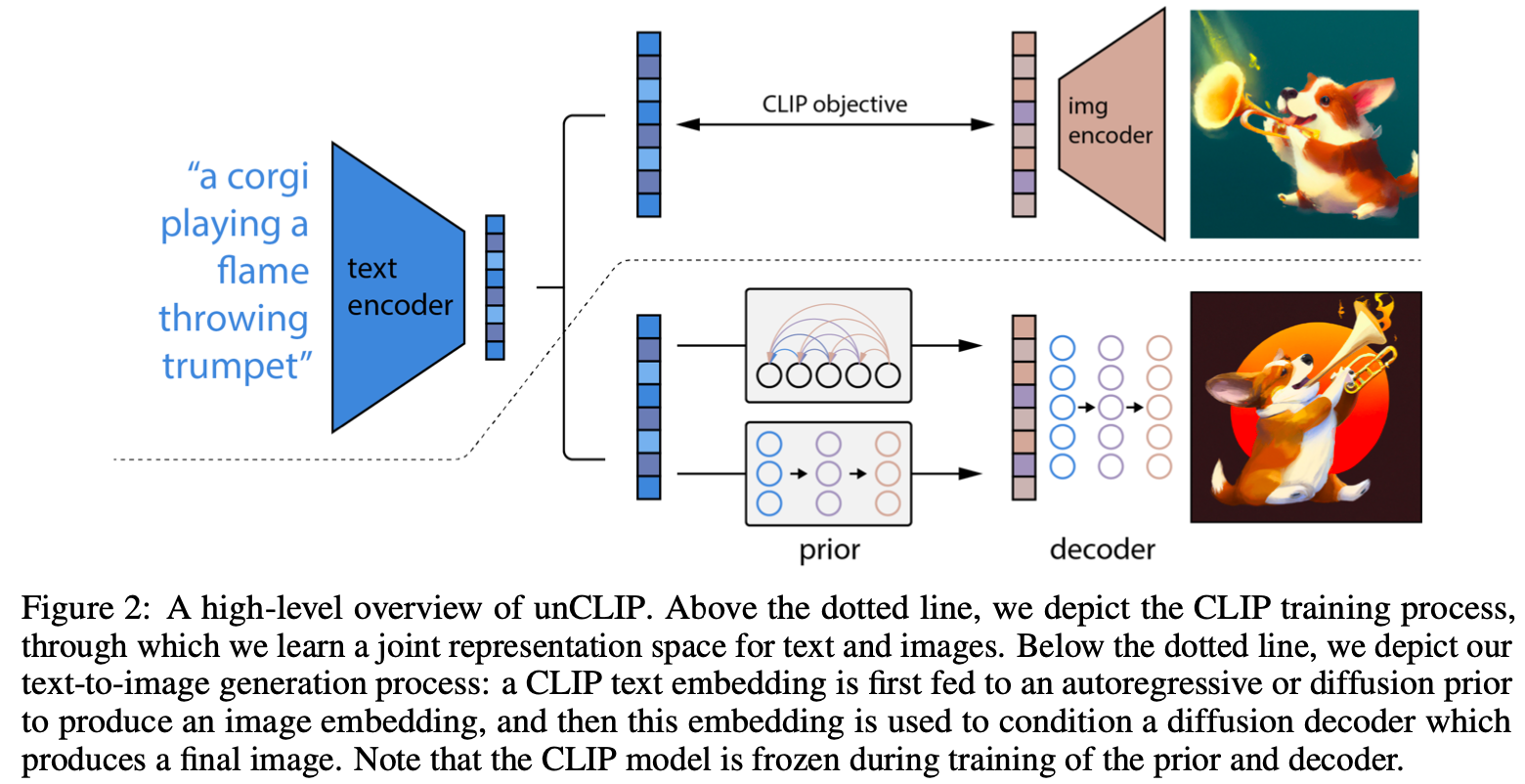
OpenAI的首篇从CLIP的image embedding生成图像的方法,实验证明这种方法生成的图像能够保留丰富的语义与风格分布。
## 算法原理
算法主要包括CLIP、Prior和Decoder三个部分,对三个部分进行分开训练:
- CLIP训练:
使用图文配对数据,基于对比损失训练CLIP的text encoder和img encoder编码器,目的是想在潜在空间中对文本和图象进行统一。也可以直接使用OpenAI预训练的CLIP模型;
- Prior训练:
Prior结构是论文的一个创新点,输入是文本通过CLIP的text encoder得到的文本特征,输出是预测的对应图像特征,训练时的Ground Truth是文本对应图像通过CLIP的image encoder得到的图像特征,论文中prior结构尝试使用了自回归和扩散模型两种结构,最后扩散模型的效果较好。
- Decoder训练:
Decoder将Prior生成的图像特征解码为高分辨率的图像,和Prior结构一样采用了扩散模型。Decoder由多个unet组成,从低分辨率生成高分辨率图像。在训练Prior和Decoder时,CLIP模型的参数是冻结的。
## 环境配置
### Docker(方法一)
从[光源](https://www.sourcefind.cn/#/service-list)中拉取docker镜像:
```
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.1.0-ubuntu20.04-dtk24.04.1-py3.10
```
创建容器并挂载目录进行开发:
```
docker run -it --name {name} --shm-size=1024G --device=/dev/kfd --device=/dev/dri/ --privileged --cap-add=SYS_PTRACE --security-opt seccomp=unconfined --ulimit memlock=-1:-1 --ipc=host --network host --group-add video -v /opt/hyhal:/opt/hyhal:ro -v {}:{} {docker_image} /bin/bash
# 修改1 {name} 需要改为自定义名称,建议命名{框架_dtk版本_使用者姓名},如果有特殊用途可在命名框架前添加命名
# 修改2 {docker_image} 需要需要创建容器的对应镜像名称,如: pytorch:1.10.0-centos7.6-dtk-23.04-py37-latest【镜像名称:tag名称】
# 修改3 -v 挂载路径到容器指定路径
pip install -r requirements.txt
```
### Dockerfile(方法二)
```
cd docker
docker build --no-cache -t dalle2_pytorch:1.0 .
docker run -it --name {name} --shm-size=1024G --device=/dev/kfd --device=/dev/dri/ --privileged --cap-add=SYS_PTRACE --security-opt seccomp=unconfined --ulimit memlock=-1:-1 --ipc=host --network host --group-add video -v /opt/hyhal:/opt/hyhal:ro -v {}:{} {docker_image} /bin/bash
pip install -r requirements.txt
```
### Anaconda(方法三)
线上节点推荐使用conda进行环境配置。
创建python=3.10的conda环境并激活
```
conda create -n dalle2 python=3.10
conda activate dalle2
```
关于本项目DCU显卡所需的特殊深度学习库可从[光合](https://developer.hpccube.com/tool/)开发者社区下载安装。
```
DTK驱动:dtk24.04.1
python:python3.10
pytorch:2.1.0
torchvision:0.16.0
```
安装其他依赖包
```
pip install -r requirements.txt
```
## 数据集
原项目中并未提供训练数据集,我们这里使用laion2B的中文数据集进行训练,数据集的准备包括以下步骤:
- 1、从huggingface下载laion2B中文数据集,下载parquet文件,里面是图片url+caption
huggingface数据地址:[https://huggingface.co/datasets/IDEA-CCNL/laion2B-multi-chinese-subset/tree/main](https://huggingface.co/datasets/IDEA-CCNL/laion2B-multi-chinese-subset/tree/main)
可以通过huggingface镜像进行下载:
```
# 安装配置huggingface镜像
pip install -U huggingface_hub
export HF_ENDPOINT=https://hf-mirror.com
# 下载数据集保存在laion2B-multi-chinese文件夹中
huggingface-cli download --repo-type dataset --resume-download IDEA-CCNL/laion2B-multi-chinese-subset --local-dir ./laion2B-multi-chinese
```
- 2、使用img2dataset项目将parquet文件转换为image+caption格式:
img2dataset项目地址:[https://github.com/rom1504/img2dataset](https://github.com/rom1504/img2dataset)
使用方法:
```
# 安装img2dataset
pip install img2dataset
# 数据集转换
img2dataset --url_list laion2B-multi-chinese --input_format "parquet"\
--url_col "URL" --caption_col "TEXT" --output_format webdataset\
--output_folder laion2B-multi-chinese-data --processes_count 16 --thread_count 128 --image_siz 256\
--save_additional_columns '["NSFW","similarity","LICENSE"]' --enable_wandb True
```
- 3、生成img_path和prompt配对的json文件
```
python create_json.py
```
整个数据集转换下来需要三天的时间,数据集有10个T,本项目提供小数据集用于快速实验:
[test-data](https://pan.baidu.com/s/1IlSb_J88cgTNkRmnG0wm_Q?pwd=1234)
[data.json](https://pan.baidu.com/s/1kpBIWOwxE8HWPXB-a4kWCA?pwd=1234)
## 训练
dalle2的三个组件CLIP、Prior和Decoder是单独训练的,CLIP可以使用OpenAI的预训练模型,这里先训练Prior,然后训练Decoder:
### Prior组件训练
```
python train_prior.py
```
### Decoder组件训练
```
python train_decoder.py
```
## 推理
下载预训练权重文件并解压:
[model.zip](https://pan.baidu.com/s/1GdDN8zt8mrqvbJELtcF3ng?pwd=1234)
[model.z01](https://pan.baidu.com/s/1hRLiDZE28jigEriFcQe0BQ?pwd=1234)
[model.z02](https://pan.baidu.com/s/1B9VnzzXBP549EIO6aAP_sw?pwd=1234)
[model.z03](https://pan.baidu.com/s/1RoTFTIkRHJw34sKpsHrT1w?pwd=1234)
[model.z04](https://pan.baidu.com/s/1UCnXLKreoNqR7lXFw291LA?pwd=1234)
可通过SCNet快速下载链接[http://113.200.138.88:18080/aimodels/dalle2_pytorch/-/tree/main](http://113.200.138.88:18080/aimodels/dalle2_pytorch/-/tree/main)进行下载
```
# 文本生成图片
python example_inference.py dream
```
## result
输入提示词为:
```
A field of flowers
5
```
模型生成图片:
## 应用场景
### 算法类别
多模态
### 热点应用行业
AIGC,设计,教育
## 源码仓库及问题反馈
[https://developer.hpccube.com/codes/modelzoo/dalle2_pytorch](https://developer.hpccube.com/codes/modelzoo/dalle2_pytorch)
## 参考资料
[https://github.com/LAION-AI/dalle2-laion](https://github.com/LAION-AI/dalle2-laion)
[https://github.com/rom1504/img2dataset](https://github.com/rom1504/img2dataset)