
dalle2_pytorch
Showing
{kind=link}

517 KB
{kind=link}

26.8 KB
examples/landscapes.png
0 → 100644
{kind=link}

258 KB
{kind=link}

908 KB
examples/variations/jeep.png
0 → 100644
{kind=link}

220 KB
{kind=link}

262 KB
gradio_inference.py
0 → 100644
icon.png
0 → 100644
{kind=link}
68.4 KB
{kind=link}

113 KB
{kind=link}

96.8 KB
{kind=link}

71.5 KB
{kind=link}

142 KB
{kind=link}

91.8 KB
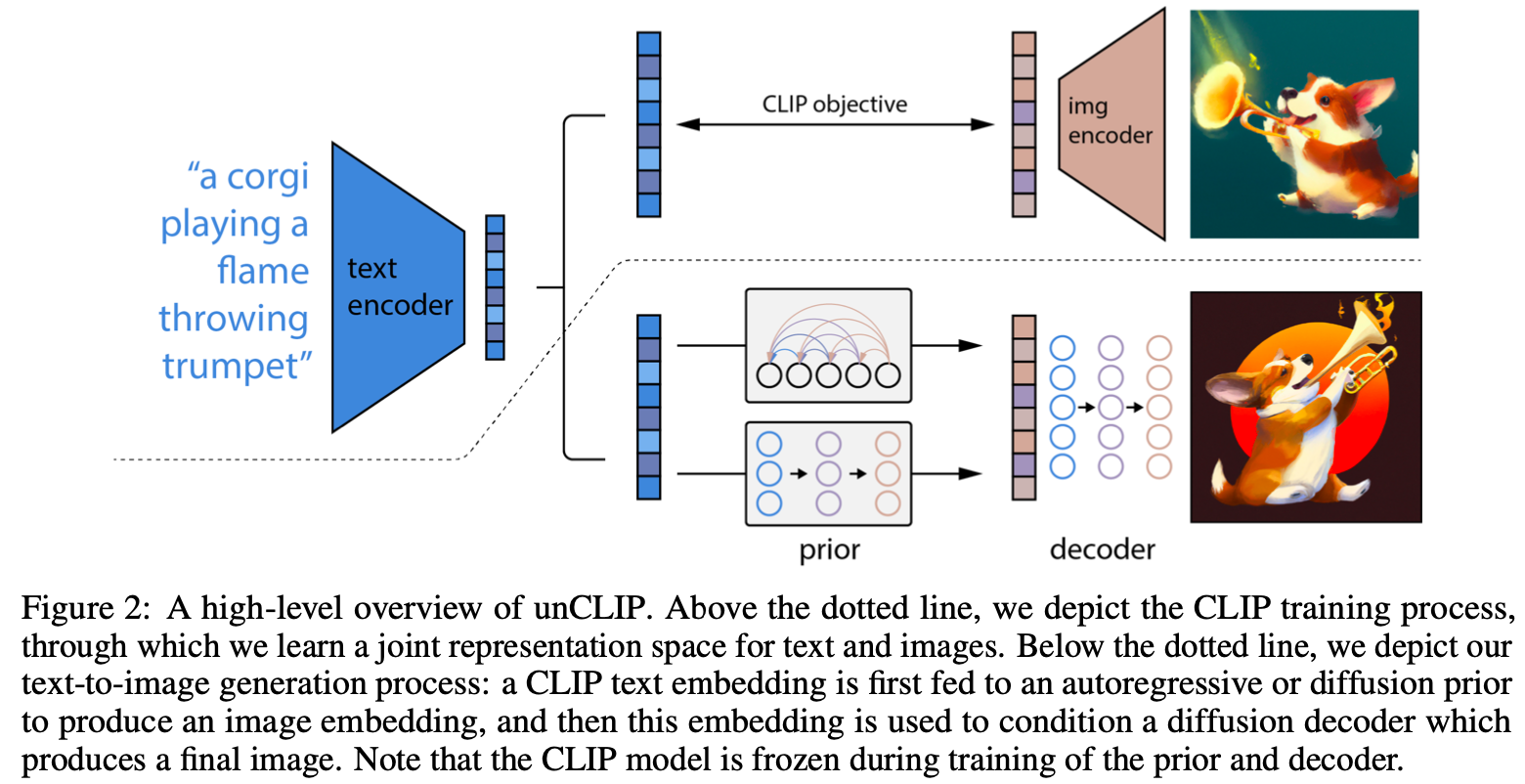
images/dalle2.png
0 → 100644
{kind=link}
425 KB
requirements.txt
0 → 100644
| pydantic==1.10.6 | ||
| dalle2-pytorch==1.1.0 | ||
| datasets |
setup.py
0 → 100644
train_decoder.py
0 → 100644
train_prior.py
0 → 100644