# CRNN
## 论文
[An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition](https://arxiv.org/abs/1507.05717)
## 模型结构
CRNN模型,即将CNN与RNN网络结合,共同训练。主要用于在一定程度上实现端到端(end-
to-end)地对不定长的文本序列进行识别,不用先对单个文字进行切割,而是将文本识别转化为时序依赖的序列学习问题,就是基于图像的序列识别。这里有一个很精彩的改动,一共有四个最大池化层,但是最后两个池化层的窗口尺寸由2x2改为1x2,也就是图片的高度减半了四次,而宽度则只减半了两次(,这是因为文本图像多数都是高较小而宽较长,所以其feature map 也是这种高小宽长的矩形形状,如果使用1×2的池化窗口可以尽量保证不丢失在宽度方向的信息,更适合英文字母识别。
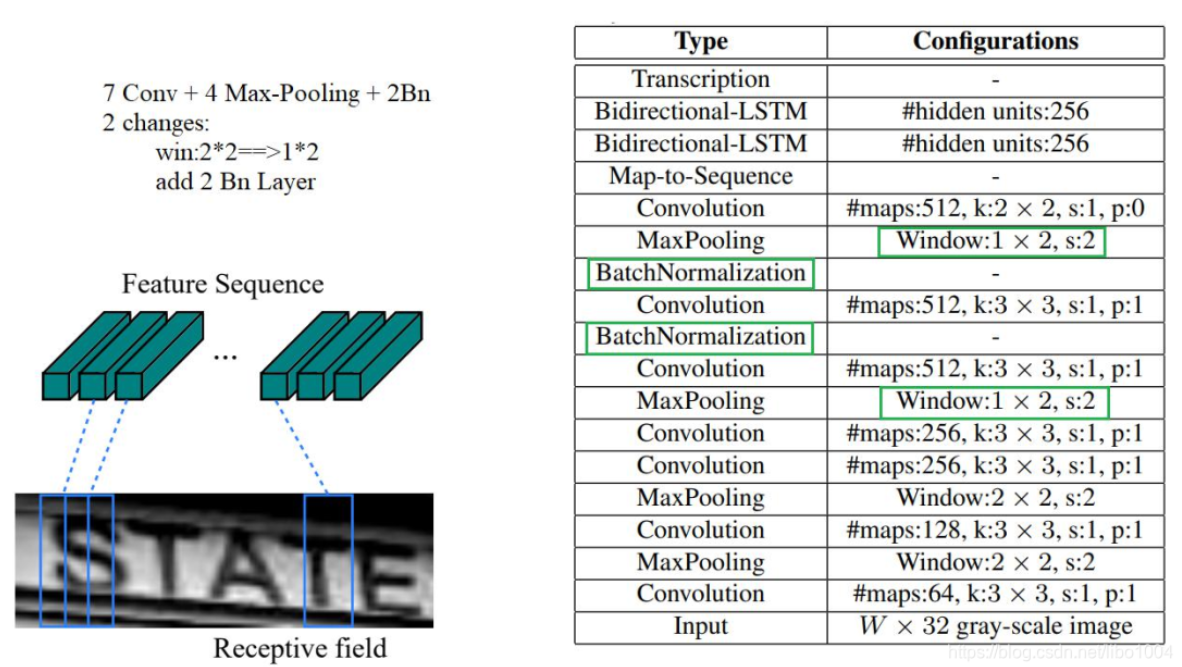
## 算法原理
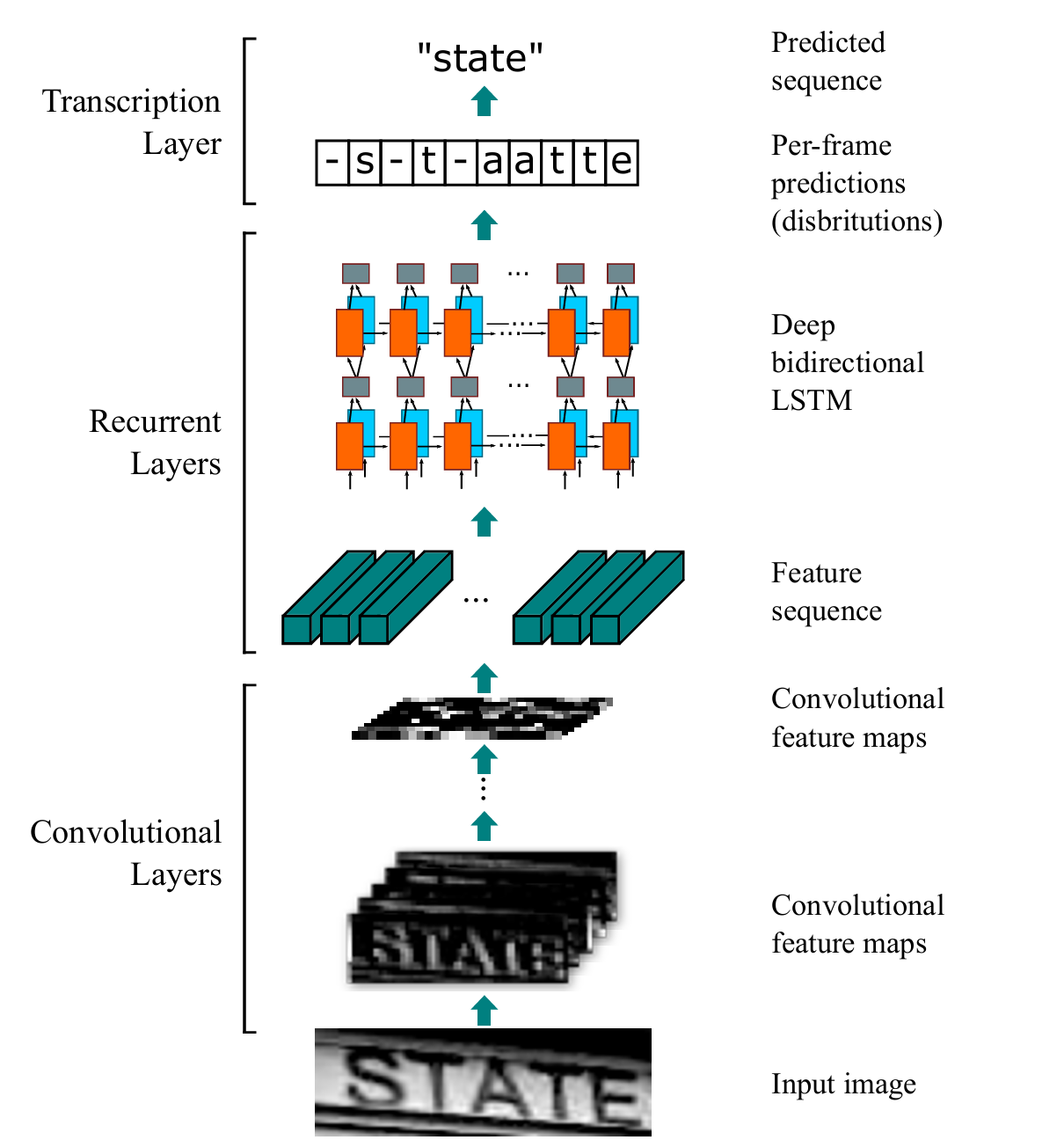
CRNN(卷积循环神经网络)是一种用于光学字符识别(OCR)的深度学习模型,它结合了卷积神经网络(CNN)强大的特征提取能力、循环神经网络(RNN)对序列信息的建模能力,以及连接时序分类(CTC)损失函数来解决不定长序列对齐问题。CNN从输入图像中提取特征图,RNN对特征序列进行建模并预测字符概率分布,CTC则将这些概率分布转化为最终的文本序列。CRNN能够实现端到端的文字识别,无需显式地进行字符分割,同时能够处理不定长的文本序列,广泛应用于自然场景文字识别、文档扫描与识别等领域,具有较高的识别准确率和鲁棒性。
## 环境配置
### Docker(方法一)
推荐使用docker方式运行, 此处提供[光源](https://www.sourcefind.cn/#/service-list)拉取docker镜像的地址与使用步骤
```
docker pull image.sourcefind.cn:5000/dcu/admin/base/paddlepaddle:3.0.0-py3.10-dtk24.04.3-ubuntu20.04
docker run -it --shm-size=1024G -v /path/your_code_data/:/path/your_code_data/ -v /opt/hyhal:/opt/hyhal --network=host --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name CRNN bash # 为以上拉取的docker的镜像ID替换
git clone https://developer.sourcefind.cn/codes/modelzoo/crnn_paddle
cd /path/your_code_data/
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install paddleocr
# 需要关联动态库包
export LD_LIBRARY_PATH=/opt/dtk-24.04.3/lib:/opt/dtk-24.04.3/cuda/extras/CUPTI/lib64:/opt/dtk-24.04.3/cuda/targets/x86_64-linux/lib:$LD_LIBRARY_PATH
```
Tips:以上dtk驱动、python、paddlepaddle等DCU相关工具版本需要严格一一对应。
### Dockerfile(方法二)
此处提供dockerfile的使用方法
```
git clone http://developer.sourcefind.cn/codes/modelzoo/kimi-vl-a3b-instruct_pytorch.git
docker build -t internvl:latest .
docker run --shm-size 500g --network=host --name=kimi-vl --privileged --device=/dev/kfd --device=/dev/dri --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -v 项目地址(绝对路径):/home/ -v /opt/hyhal:/opt/hyhal:ro -it bash
cd /path/your_code_data/
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install paddleocr
# 需要关联动态库包
export LD_LIBRARY_PATH=/opt/dtk-24.04.3/lib:/opt/dtk-24.04.3/cuda/extras/CUPTI/lib64:/opt/dtk-24.04.3/cuda/targets/x86_64-linux/lib:$LD_LIBRARY_PATH
```
### Anaconda(方法三)
此处提供本地配置、编译的详细步骤,例如:
关于本项目DCU显卡所需的特殊深度学习库可从[光合](https://developer.sourcefind.cn/tool/)开发者社区下载安装。
```
DTK驱动:dtk24.04.3
python:3.10
paddlepaddle:3.0.0
```
`Tips:以上dtk驱动、python、torch等DCU相关工具版本需要严格一一对应`
其它非深度学习库参照requirement.txt安装:
```
git clone http://developer.sourcefind.cn/codes/modelzoo/kimi-vl-a3b-instruct_pytorch.git
cd /path/your_code_data/
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install paddleocr
export LD_LIBRARY_PATH=/opt/dtk-24.04.3/lib:/opt/dtk-24.04.3/cuda/extras/CUPTI/lib64:/opt/dtk-24.04.3/cuda/targets/x86_64-linux/lib:$LD_LIBRARY_PATH
```
## 数据集
在本测试中可以使用(icdar2015)[train_data.rar]数据集,可在本项目已经提供并整理了可直接用于验证得数据集文件,可在train_data.rar压缩文件夹中目录下找到。
训练集应有如下文件结构:
```
|-train_data
|-icdar2015
|-rec
|- rec_gt_train.txt
|- train
|- word_001.png
|- word_002.jpg
|- word_003.jpg
| ...
```
## 训练
训练前需要完成两件事,首先是下载模型,然后是修改配置文件。
### 模型下载
下载地址 https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/rec_r34_vd_none_bilstm_ctc_v2.0_train.tar
```
cd PaddleOCR/
# 下载CRNN的预训练模型
wget -P ./pretrain_models/https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/rec_r34_vd_none_bilstm_ctc_v2.0_train.tar
# 解压模型参数
cd pretrain_models
tar -xf rec_r34_vd_none_bilstm_ctc_v2.0_train.tar && rm -rf rec_r34_vd_none_bilstm_ctc_v2.0_train.tar
```
### 配置文件
```
# 本项目的配置文件已经修改,其余的模型及任务可以参考该配置文件中的配置方式
configs/rec/rec_r34_vd_none_bilstm_ctc.yml
```
### 运行训练文件
```
CUDA_VISIBLE_DEVICES=1 python3 tools/train.py -c ./configs/rec/rec_r34_vd_none_bilstm_ctc.yml -o Global.pretrained_model=./pretrain_models/rec_r34_vd_none_bilstm_ctc_v2.0_train/best_accuracy
```
## 推理
### 单机单卡
```
# 预测使用的配置文件必须与训练一致
python3 tools/infer_rec.py -c configs/rec/rec_r34_vd_none_bilstm_ctc.yml -o Global.pretrained_model='./pretrain_models/rec_r34_vd_none_bilstm_ctc_v2.0_train/best_accuracy' Global.infer_img='./docs/images/ppocrv4.png'
```
## result
### 精度
无
## 应用场景
### 算法类别
`文字识别`
### 热点应用行业
`科研,教育,政府,金融`
## 预训练权重
CRNN PaddlePaddle下载地址为:[rec_r34_vd_none_bilstm_ctc](https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/rec_r34_vd_none_bilstm_ctc_v2.0_train.tar)
## 源码仓库及问题反馈
- https://developer.sourcefind.cn/codes/modelzoo/crnn_paddle
## 参考资料
- https://github.com/PaddlePaddle/PaddleOCR/
