# CRNN文本识别
本示例基于CRNN文本识别模型实现了两种MIGraphX推理:静态推理和动态shape推理。静态推理时CRNN模型只接受固定尺寸的图像输入,而动态shape推理则可以输入不同尺寸的图像进行识别。
## 模型简介
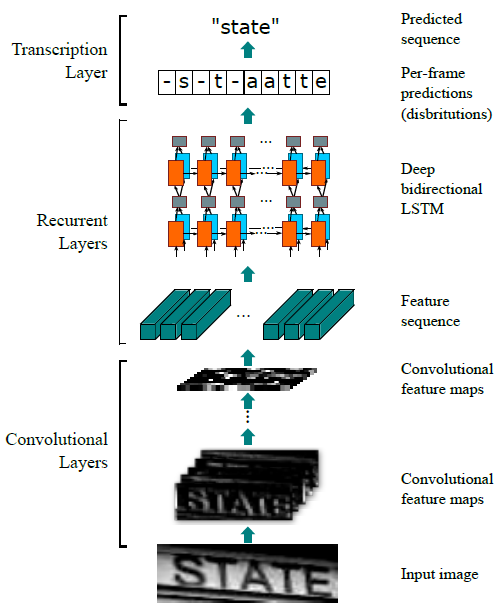
CRNN是文本识别领域的一种经典算法。该算法的主要思想是认为文本识别需要对序列进行预测,所以采用了预测序列常用的RNN网络。算法通过CNN提取图片特征,然后采用RNN对序列进行预测,最终使用CTC方法得到最终结果。模型的主要结构包括基于CNN的图像特征提取模块以及基于双向LSTM的文字序列特征提取模块,网络结构如下图所示。
 本示例采用了如下的开源实现:https://github.com/meijieru/crnn.pytorch, 作者提供了CRNN的预训练模型。
## 模型初始化
本示例使用导出的动态CRNN模型同时执行静态和动态推理。模型加载成功后,模型初始化主要调用MIGraphX的parse_onnx()、get_parameter_shapes()、compile()函数实现对模型的加载解析、获取模型输入属性和编译处理。静态推理和动态推理在这个过程中主要区别在于parse_onnx()函数的输入不同。
1. 静态推理
```
ErrorCode Crnn::Initialize(InitializationParameterOfOcr initializationParameterOfOcr, bool dynamic)
{
...
migraphx::onnx_options onnx_options;
onnx_options.map_input_dims["input"]={1,1,32,100};
net = migraphx::parse_onnx(modelPath, onnx_options);
...
}
```
静态推理将模型的输入设为一个固定的尺寸{1,1,32,100},每次执行静态推理都必须将输入图像resize到设定的尺寸。
2. 动态shape推理
```
ErrorCode Crnn::Initialize(InitializationParameterOfOcr initializationParameterOfOcr, bool dynamic)
{
...
migraphx::onnx_options onnx_options;
onnx_options.map_input_dims["input"]={1,1,32,512};
net = migraphx::parse_onnx(modelPath, onnx_options);
...
}
```
动态shape推理需要设定一个最大shape,本示例设为{1,1,32,512},并在parse_onnx()函数对crnn动态模型解析时作为参数输入。注意每次输入图像的尺寸可以不像静态推理一样需要固定,但是输入尺寸必须要小于设定的最大shape。
## 预处理
静态推理将待识别的文本图像输入模型前,需要对图像做如下预处理:
- 转换为单通道图像
- resize到模型初始化设定的尺寸(100, 32)
- 将像素值归一化到[-1, 1]
- 转换数据排布为NCHW
动态推理将待识别的文本图像输入模型前,需要对图像做如下预处理:
- 转换为单通道图像
- resize到(widthRaw, 32),其中widthRaw为待识别图像原宽度
- 将像素值归一化到[-1, 1]
- 转换数据排布为NCHW
```
ErrorCode Crnn::Infer(const cv::Mat &srcImage, std::vector &resultsChar, bool raw, bool dynamic)
{
...
cv::Mat inputImage, inputBlob;
cv::cvtColor(srcImage, inputImage, CV_BGR2GRAY);
int height, width, widthRaw;
widthRaw = inputImage.cols;
if(dynamic)
{
cv::resize(inputImage, inputImage, cv::Size(widthRaw, 32));
height = inputImage.rows, width = inputImage.cols;
}
else
{
cv::resize(inputImage, inputImage, cv::Size(100, 32));
height = inputImage.rows, width = inputImage.cols;
}
// 数据排布转换
inputBlob = cv::dnn::blobFromImage(inputImage);
for(int i=0; i &resultsChar, bool raw)
{
...
// 输入数据
std::unordered_map inputData;
inputData[inputName]= migraphx::argument{inputShape, (float*)inputBlob.data};
// 推理
std::vector inferenceResults = net.eval(inputData);
// 获取推理结果
std::vector outs;
migraphx::argument result = inferenceResults[0];
// 转换为cv::Mat
migraphx::shape outputShape = result.get_shape();
int shape[]={outputShape.lens()[0],outputShape.lens()[1],outputShape.lens()[2]};
cv::Mat out(3,shape,CV_32F);
memcpy(out.data,result.data(),sizeof(float)*outputShape.elements());
outs.push_back(out);
...
}
```
inferenceResults是crnn.onnx模型的MIGraphX推理结果,CRNN模型包含一个输出,所以result等于inferenceResults[0],result包含三个维度:outputShape.lens()[0]=26可以认为是对应原图的26份纵向分割,也就是这张图片要被从左到右预测的次数,每次预测输出一个特征向量,outputShape.lens()[1]=1表示特征向量的宽度,outputShape.lens()[2]=37表示特征向量的长度。其中37=10+26+1,10、26、1分别表示10个数字(0123456789)、26个英文字母(abcdefghijklmnopqrstuvwxyz)和一个空格“-”。获取MIGraphX推理结果之后需要进行后处理得到最终文本识别的结果。后处理包括两个步骤:
1. 第一步通过判断每次预测输出的特征向量中得分最高字符对应的位置索引信息maxIdx,并将其保存在数组predChars中
```
ErrorCode Crnn::Infer(const cv::Mat &srcImage, std::vector &resultsChar, bool raw)
{
...
std::vector predChars;
const std::string alphabet = "-0123456789abcdefghijklmnopqrstuvwxyz";
//获取字符索引序列
for(uint i = 0; i < outs[0].size[0]; i++)
{
cv::Mat scores = Mat(1,outs[0].size[2],CV_32F,outs[0].ptr(i));
cv::Point charIdPoint;
double maxCharScore;
cv::minMaxLoc(scores, 0, &maxCharScore, 0, &charIdPoint);
int maxIdx = charIdPoint.x;
predChars.push_back(maxIdx);
}
...
}
```
2. 第二步根据predChars保存的字符索引信息从alphabet中提取对应的字符,并且当布尔值raw为真时,数组resultsChar保存包括空格、重复字符在内的所有输出,当布尔值raw为假时,需要做去除空格和重复字符处理,数组resultsChar保存最终的文本识别结果。
```
ErrorCode Crnn::Infer(const cv::Mat &srcImage, std::vector &resultsChar, bool raw)
{
...
//字符转录处理
for(uint i=0; i 0 && predChars[i-1]==predChars[i]))
{
resultsChar.push_back(alphabet[predChars[i]]);
}
}
}
}
...
}
```
### 动态shape推理
动态shape推理需要处理多张图像,每次输入新图像执行与静态推理一致的操作,相关过程定义在main.cpp文件中,代码如下:
```
void Sample_Crnn_Dynamic()
{
...
// 读取多张测试图像
std::vector srcImages;
cv::String folder = "../Resource/Images/DynamicPic";
std::vector imagePathList;
cv::glob(folder,imagePathList);
for (int i = 0; i < imagePathList.size(); ++i)
{
cv:: Mat srcImage=cv::imread(imagePathList[i], 1);
srcImages.push_back(srcImage);
}
// 获取推理结果
LOG_INFO(stdout,"========== Ocr Results ==========\n");
for(int i=0; i resultSim;
crnn.Infer(srcImages[i],resultSim, false, true);
// 打印输出结果
for(int i = 0; i < resultSim.size(); i++)
{
std::cout << resultSim.at(i);
}
std::cout << std::endl;
}
...
}
```
本示例采用了如下的开源实现:https://github.com/meijieru/crnn.pytorch, 作者提供了CRNN的预训练模型。
## 模型初始化
本示例使用导出的动态CRNN模型同时执行静态和动态推理。模型加载成功后,模型初始化主要调用MIGraphX的parse_onnx()、get_parameter_shapes()、compile()函数实现对模型的加载解析、获取模型输入属性和编译处理。静态推理和动态推理在这个过程中主要区别在于parse_onnx()函数的输入不同。
1. 静态推理
```
ErrorCode Crnn::Initialize(InitializationParameterOfOcr initializationParameterOfOcr, bool dynamic)
{
...
migraphx::onnx_options onnx_options;
onnx_options.map_input_dims["input"]={1,1,32,100};
net = migraphx::parse_onnx(modelPath, onnx_options);
...
}
```
静态推理将模型的输入设为一个固定的尺寸{1,1,32,100},每次执行静态推理都必须将输入图像resize到设定的尺寸。
2. 动态shape推理
```
ErrorCode Crnn::Initialize(InitializationParameterOfOcr initializationParameterOfOcr, bool dynamic)
{
...
migraphx::onnx_options onnx_options;
onnx_options.map_input_dims["input"]={1,1,32,512};
net = migraphx::parse_onnx(modelPath, onnx_options);
...
}
```
动态shape推理需要设定一个最大shape,本示例设为{1,1,32,512},并在parse_onnx()函数对crnn动态模型解析时作为参数输入。注意每次输入图像的尺寸可以不像静态推理一样需要固定,但是输入尺寸必须要小于设定的最大shape。
## 预处理
静态推理将待识别的文本图像输入模型前,需要对图像做如下预处理:
- 转换为单通道图像
- resize到模型初始化设定的尺寸(100, 32)
- 将像素值归一化到[-1, 1]
- 转换数据排布为NCHW
动态推理将待识别的文本图像输入模型前,需要对图像做如下预处理:
- 转换为单通道图像
- resize到(widthRaw, 32),其中widthRaw为待识别图像原宽度
- 将像素值归一化到[-1, 1]
- 转换数据排布为NCHW
```
ErrorCode Crnn::Infer(const cv::Mat &srcImage, std::vector &resultsChar, bool raw, bool dynamic)
{
...
cv::Mat inputImage, inputBlob;
cv::cvtColor(srcImage, inputImage, CV_BGR2GRAY);
int height, width, widthRaw;
widthRaw = inputImage.cols;
if(dynamic)
{
cv::resize(inputImage, inputImage, cv::Size(widthRaw, 32));
height = inputImage.rows, width = inputImage.cols;
}
else
{
cv::resize(inputImage, inputImage, cv::Size(100, 32));
height = inputImage.rows, width = inputImage.cols;
}
// 数据排布转换
inputBlob = cv::dnn::blobFromImage(inputImage);
for(int i=0; i &resultsChar, bool raw)
{
...
// 输入数据
std::unordered_map inputData;
inputData[inputName]= migraphx::argument{inputShape, (float*)inputBlob.data};
// 推理
std::vector inferenceResults = net.eval(inputData);
// 获取推理结果
std::vector outs;
migraphx::argument result = inferenceResults[0];
// 转换为cv::Mat
migraphx::shape outputShape = result.get_shape();
int shape[]={outputShape.lens()[0],outputShape.lens()[1],outputShape.lens()[2]};
cv::Mat out(3,shape,CV_32F);
memcpy(out.data,result.data(),sizeof(float)*outputShape.elements());
outs.push_back(out);
...
}
```
inferenceResults是crnn.onnx模型的MIGraphX推理结果,CRNN模型包含一个输出,所以result等于inferenceResults[0],result包含三个维度:outputShape.lens()[0]=26可以认为是对应原图的26份纵向分割,也就是这张图片要被从左到右预测的次数,每次预测输出一个特征向量,outputShape.lens()[1]=1表示特征向量的宽度,outputShape.lens()[2]=37表示特征向量的长度。其中37=10+26+1,10、26、1分别表示10个数字(0123456789)、26个英文字母(abcdefghijklmnopqrstuvwxyz)和一个空格“-”。获取MIGraphX推理结果之后需要进行后处理得到最终文本识别的结果。后处理包括两个步骤:
1. 第一步通过判断每次预测输出的特征向量中得分最高字符对应的位置索引信息maxIdx,并将其保存在数组predChars中
```
ErrorCode Crnn::Infer(const cv::Mat &srcImage, std::vector &resultsChar, bool raw)
{
...
std::vector predChars;
const std::string alphabet = "-0123456789abcdefghijklmnopqrstuvwxyz";
//获取字符索引序列
for(uint i = 0; i < outs[0].size[0]; i++)
{
cv::Mat scores = Mat(1,outs[0].size[2],CV_32F,outs[0].ptr(i));
cv::Point charIdPoint;
double maxCharScore;
cv::minMaxLoc(scores, 0, &maxCharScore, 0, &charIdPoint);
int maxIdx = charIdPoint.x;
predChars.push_back(maxIdx);
}
...
}
```
2. 第二步根据predChars保存的字符索引信息从alphabet中提取对应的字符,并且当布尔值raw为真时,数组resultsChar保存包括空格、重复字符在内的所有输出,当布尔值raw为假时,需要做去除空格和重复字符处理,数组resultsChar保存最终的文本识别结果。
```
ErrorCode Crnn::Infer(const cv::Mat &srcImage, std::vector &resultsChar, bool raw)
{
...
//字符转录处理
for(uint i=0; i 0 && predChars[i-1]==predChars[i]))
{
resultsChar.push_back(alphabet[predChars[i]]);
}
}
}
}
...
}
```
### 动态shape推理
动态shape推理需要处理多张图像,每次输入新图像执行与静态推理一致的操作,相关过程定义在main.cpp文件中,代码如下:
```
void Sample_Crnn_Dynamic()
{
...
// 读取多张测试图像
std::vector srcImages;
cv::String folder = "../Resource/Images/DynamicPic";
std::vector imagePathList;
cv::glob(folder,imagePathList);
for (int i = 0; i < imagePathList.size(); ++i)
{
cv:: Mat srcImage=cv::imread(imagePathList[i], 1);
srcImages.push_back(srcImage);
}
// 获取推理结果
LOG_INFO(stdout,"========== Ocr Results ==========\n");
for(int i=0; i resultSim;
crnn.Infer(srcImages[i],resultSim, false, true);
// 打印输出结果
for(int i = 0; i < resultSim.size(); i++)
{
std::cout << resultSim.at(i);
}
std::cout << std::endl;
}
...
}
```